超详细讲解SpringBoot——数据访问
前言:
大部分系统都离不开数据访问,数据库包括SQL和NOSQL,SQL是指关系型数据库,常见的有SQL Server,Oracle,MySQL(开源),NOSQL是泛指非关系型数据库,常见的有MongoDB,Redis。
用spring开发时我们常用的ORM框架有JDBC、Mybatis,Hibernate,现在最常用的应该是Mybatis。
在Springboot中对于数据访问层,无论是SQL还是NOSQL,都默认采用整合Spring Data的方式进行统一处理,Springboot会帮我们添加大量自动配置,屏蔽了很多设置。并引入各种xxxTemplate,xxxRepository来简化我们对数据访问层的操作。对我们来说只需要进行简单的设置即可。这篇就来学习springboot整合JDBC,mybatis、JPA。
我们需要用什么数据访问,就引入相关的start进行开发。
一、JDBC
jdbc是我们最先学习的一个数据库框架,SpringBoot也进行了相应整合。
(1)引入依赖
<!--JDBC --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-jdbc</artifactId></dependency><!--mysql 驱动--><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><scope>runtime</scope></dependency>
(2)数据源配置
我們可以做个测试:
@Autowiredprivate DataSource dataSource;@Testpublic void test() throws SQLException {System.out.println(dataSource.getClass());Connection connection = dataSource.getConnection();System.out.println(connection);connection.close();}
输出为:com.zaxxer.hikari.HikariDataSource
说明默认数据源是com.zaxxer.hikari.HikariDataSource,而在springboot 2.0之前为org.apache.tomcat.jdbc.pool.DataSource。我们也可以通过改变spring.datasource.type 属性来更改我们想自定义的数据源。数据源的相关配置都在DataSourceProperties,我们可以参考这个类进行配置。
(3)DataSourceInitializer
DataSourceInitializer这里面有两个方法runSchemaScripts()可以运行建表语句,runDataScripts()可以运行插入数据的sql语句。
默认使用schema-.sql创建建表语句,用data-.sql插入数据语句,当然我们也可以自己配置:
spring:datasource:schema:- classpath:department.sql
(4)操作数据库
由于spingboot已经帮我们自动配置了,那我们可以直接使用JdbcTemplate进行数据库操作:
@AutowiredJdbcTemplate jdbcTemplate;@Testpublic void jdbcTest(){List<Map<String, Object>> mapList = jdbcTemplate.queryForList("select * from user ");System.out.println(mapList.get(0));}
结果:{id=1, username=王五, birthday=null, sex=2, address=null}
二、整合Druid数据源
上面讲到我们有默认的数据源,但一般情况我们还是会使用阿里提供的Druid数据源,因为Druid提供的功能更多,并且能够监控统计,这个时候我们需要先引入pom依赖,然后将spring.datasource.type 修改:
<!-- https://mvnrepository.com/artifact/com.alibaba/druid --><dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.1.16</version></dependency>
Druid的常用配置如下:
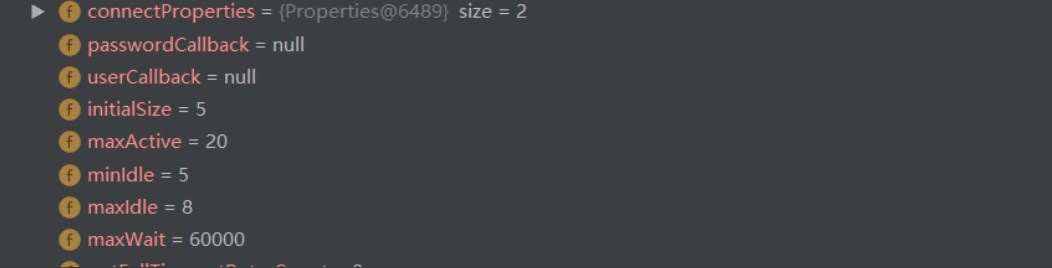
type: com.alibaba.druid.pool.DruidDataSource# 数据源其他配置initialSize: 5minIdle: 5maxActive: 20maxWait: 60000timeBetweenEvictionRunsMillis: 60000minEvictableIdleTimeMillis: 300000validationQuery: SELECT 1 FROM DUALtestWhileIdle: truetestOnBorrow: falsetestOnReturn: falsepoolPreparedStatements: true# 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙filters: stat,wall,log4jmaxPoolPreparedStatementPerConnectionSize: 20useGlobalDataSourceStat: trueconnectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=500
配置之后不会立刻生效,我们还需要编写配置类:
@Configurationpublic class DruidConfig {@ConfigurationProperties(prefix = "spring.datasource")@Beanpublic DataSource druid(){return new DruidDataSource();}}
再次运行上面查询数据源的方法,可以得到如下结果:
注:必须引入日志依赖,否则会报错
<!-- https://mvnrepository.com/artifact/log4j/log4j --><dependency><groupId>log4j</groupId><artifactId>log4j</artifactId><version>1.2.17</version></dependency>
我们在加上Druid的监控配置:
//配置Druid的监控//1、配置一个管理后台的Servlet@Beanpublic ServletRegistrationBean statViewServlet(){ServletRegistrationBean bean = new ServletRegistrationBean(new StatViewServlet(), "/druid/*");Map<String,String> initParams = new HashMap<>();initParams.put("loginUsername","admin");initParams.put("loginPassword","123456");initParams.put("allow","");//默认就是允许所有访问initParams.put("deny","192.168.15.21");bean.setInitParameters(initParams);return bean;}//2、配置一个web监控的filter@Beanpublic FilterRegistrationBean webStatFilter(){FilterRegistrationBean bean = new FilterRegistrationBean();bean.setFilter(new WebStatFilter());Map<String,String> initParams = new HashMap<>();initParams.put("exclusions","*.js,*.css,/druid/*");bean.setInitParameters(initParams);bean.setUrlPatterns(Arrays.asList("/*"));return bean;}
这样我们可以直接通过后台监控数据源访问情况。
三、Mybatis
第一步也是引入依赖:
<dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter</artifactId><version>1.3.1</version></dependency>
也导入Druid数据源,并加入之前学习Mybatis时用到的实体,而后就可以进行测试,Mybatis的使用也有两种方法,注解版和配置文件版,注解版用的很少,一般都是配置文件。
(1)注解版
@Mapperpublic interface DepartmentMapper {@Select("select * from department where id=#{id}")Department getDeptById(Integer id);@Delete("delete from department where id=#{id}")int deleteDeptById(Integer id);@Options(useGeneratedKeys = true,keyProperty = "id")@Insert("insert into department(departmentName) values(#{departmentName})")int insertDept(Department department);@Update("update department set departmentName=#{departmentName} where id=#{id}")int updateDept(Department department);}
测试:
@AutowiredUserMapper userMapper;@AutowiredDepartmentMapper departmentMapper;@Testpublic void mybatisTest(){Department deptById = departmentMapper.getDeptById(1);System.out.println(deptById);}结果:Department(id=1, departmentName=AA)
(2)配置文件版
使用配置文件版方式也很简单,也是先新增一个接口:
@Mapperpublic interface UserMapper {User queryUserById(Integer id);}
然后新增一个全局配置文件:SqlMapConfig.xml
<?xml version="1.0" encoding="UTF-8" ?><!DOCTYPE configurationPUBLIC "-//mybatis.org//DTD Config 3.0//EN""http://mybatis.org/dtd/mybatis-3-config.dtd"><configuration></configuration>
里面暂时什么配置都不需要,然后再引入相应的XXXMapper.xml文件,最后在配置文件中加上扫描文件配置即可
mybatis:config-location: classpath:mybatis/SqlMapConfig.xmlmapper-locations: classpath:mybatis/mapper/*.xml
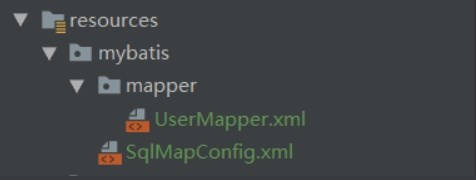
UserMapper.xml内容:
<?xml version="1.0" encoding="UTF-8" ?><!DOCTYPE mapperPUBLIC "-//mybatis.org//DTD Mapper 3.0//EN""http://mybatis.org/dtd/mybatis-3-mapper.dtd"><mapper namespace="com.yuanqinnan.mapper.UserMapper"><select id="queryUserById" parameterType="int" resultType="com.yuanqinnan.model.User">SELECT * FROM `user`where id=#{ id}</select></mapper>
测试:
@Testpublic void mybatisTest(){Department deptById = departmentMapper.getDeptById(1);System.out.println(deptById);User userById = userMapper.queryUserById(1);System.out.println(userById);}
Mybatis的配置就是这么简单,基本不需要额外配置。
四、JPA
JDBC和Mybatis我们之前都学习过,SpringBoot只不过是帮我们整合配置,而JPA我们之前没有接触过,所以还是要先解释下,了解JPA之前我们先了解Spring Data:
Spring Data 项目的目的是为了简化构建基于Spring 框架应用的数据访问技术,包括非关系数据库、Map-Reduce 框架、云数据服务等等;另外也包含对关系数据库的访问支持。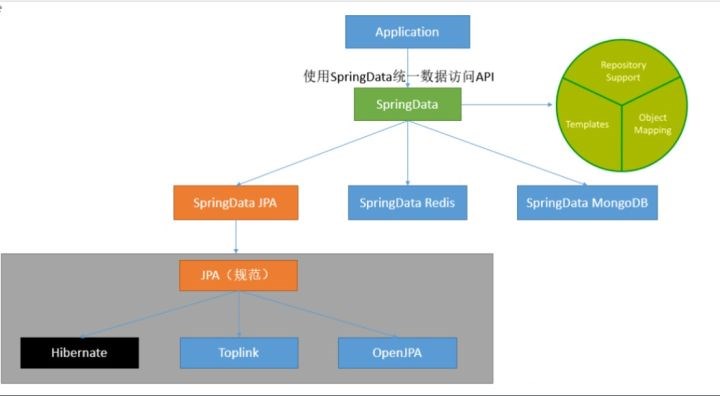
Spring Data 主要特点是:
SpringData为我们提供使用统一的API来对数据访问层进行操作;这主要是Spring Data Commons项目来实现的。Spring Data Commons让我们在使用关系型或者非关系型数据访问技术时都基于Spring提供的统一标准,标准包含了CRUD(创建、获取、更新、删除)、查询、排序和分页的相关操作。
SpringData帮我们封装了数据库操作,我们只需要进程接口,就可以进行操作,SpringData有如下统一的接口
Repository
我们要使用JPA,就是继承JpaRepository,我们只要按照它的命名规范去对命名接口,便可以实现数据库操作功能,这样说有些抽象,还是用一个例子来说明:
第一步:引入依赖
<!-- springdata jpa依赖 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-jpa</artifactId></dependency>
第二步:编写表对应实体:
//使用JPA注解配置映射关系@Entity //告诉JPA这是一个实体类(和数据表映射的类)@Table(name = "order") //@Table来指定和哪个数据表对应;order;@Datapublic class Order {@Id //这是一个主键@GeneratedValue(strategy = GenerationType.IDENTITY)//自增主键private Integer id;@Column(name = "user_Id")private Integer userId;//这是和数据表对应的一个列@Column(name="number",length = 32)private String number;// 订单创建时间,省略默认列名就是属性名private Date createtime;// 备注private String note;}
第三步:编写仓库接口:
@Repositorypublic interface OrderRepository extends JpaRepository<Order, Integer> {}
这个时候OrderRepository 已经有了很多实现好的方法,我们只要跟着调用即可
测试:
@AutowiredOrderRepository orderRepository;@Testpublic void jpaTest(){List<Order> all = orderRepository.findAll();System.out.println(all);}
一个简单的JPA实现完成,当然JPA的内容很多,这里只是一个非常简单的例子,要进一步的学习的话还是要去看官方文档。
结语:
这里的分享暂时就这样了,我这还整理有大量的Java面试资料和学习资料,有需要的可以点击进入,暗号:cszq,免费领取!

最后!祝大家都能工作顺利哦!



























- 找指定长度的目标子串+哈希")
")





还没有评论,来说两句吧...