Spark Core快速入门系列(8) | HashPartitioner和RangePartitioner
HashPatitioner
1.默认分区器2.聚合算子如果没有分区器就是默认分区器对shuffle后的rdd进行重新分区缺点:容易造成数据倾斜
RangePartitioner
sortByKey排序算子使用的RangePartitioner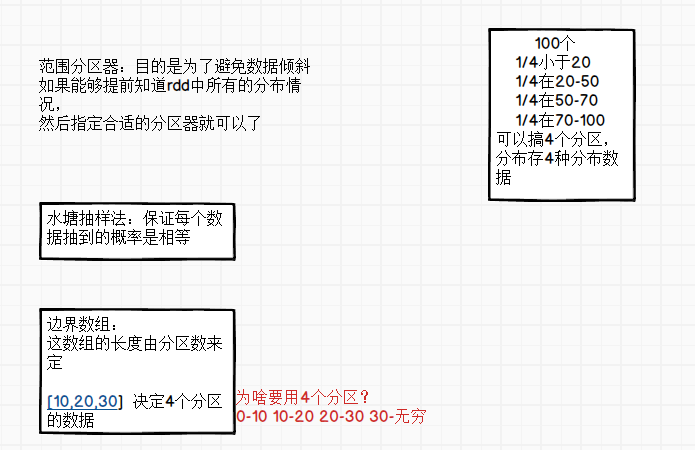
看源码
在0分区
在3分区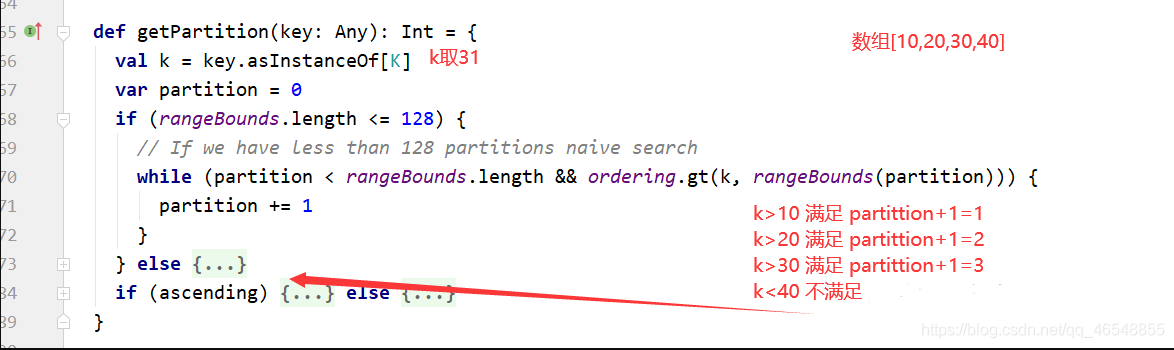
在4分区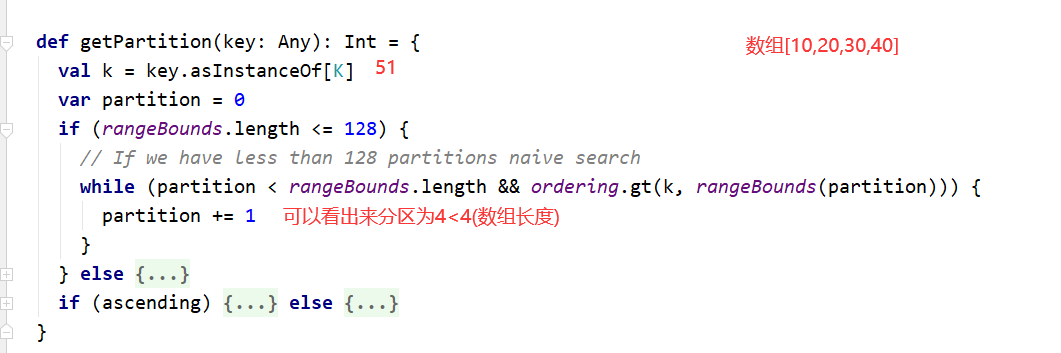
HashPatitioner
1.默认分区器2.聚合算子如果没有分区器就是默认分区器对shuffle后的rdd进行重新分区缺点:容易造成数据倾斜
RangePartitioner
sortByKey排序算子使用的RangePartitioner
看源码
在0分区
在3分区
在4分区
目录 读取文件的切片规则 如果找不到源码-分享步骤 读取文件的切片规则 截取了源码重要的部分 //所有的文件 File
`HashPatitioner` 1.默认分区器 2.聚合算子如果没有分区器就是默认分区器对shuffle后的rdd进行重新分区 缺点:
目录 rdd的持久化 聚合算子默认缓存 checkpoint rdd的持久化 ![在这里插入图片描述][watermark
目录 spark的序列化 关于序列化的原理 Kyro序列化(建议使用) 总结 spark的序列化 进行 Sp
![在这里插入图片描述][watermark_type_ZmFuZ3poZW5naGVpdGk_shadow_10_text_aHR0cHM6Ly9ibG9nLmNzZG4ub
`话不多说,直接看源码!` ctrl+左键 ![在这里插入图片描述][watermark_type_ZmFuZ3poZW5naGVpdGk_shadow_10_text
[\[Spark\] - HashPartitioner & RangePartitioner 区别][Spark_ - HashPartitioner _ RangePart




























还没有评论,来说两句吧...