分库分表sharding-jdbc
一、为什么要分库分表
图示为垂直分库
二、分库分表的方式
分库分表有4种方式,垂直分库/垂直分表,水平分库/水平分表。
1.垂直分库
把原本的单库拆成多库,一般是根据表来分库。如把用户表分成单独的用户库。
2.垂直分表
把原来的单表拆成多表,一般是把一些大数据高量查询的字段,独立成一个新表。如把商品表中的商品详情字段拆成一张新的商品详情表。
垂直分库/分表本质上,只是把单一数据库,数据表,进行优化。把各个表的查询压力,由原来的单一数据库,分流到个每个表拆分后的数据库中。数据量大了之后,拆分后的数据库也不能高效工作了,这时就要把库中的数据进行分散。也就是水平分库。
3.水平分库
把单库中的数据,分散到多个库中,如把用户库分成用户库_0,用户库_1。
4.水平分表
把单表中的数据,分散到多个表中,如把用户表分成用户表_0,用户表_1。
水平分库/分表,一般都是要设置分库键,和分表键的。不设置的话会查询所有分库节点,产生多余的查询。
三、使用sharding-jdbc实现水平分库分表
垂直分库分表不概述,因为一般使用微服务方式开发,就是使用垂直分库了。垂直分表则是一个表的设计问题了。
因此,只讨论一下怎么sharding-jdbc水平主从复制分库分表
一、确定数据库节点
声明所有数据库节点,我这里是2个业务节点order_db_0(m0),order_db_1(m1),但做了主从复制,所以有2个是从节点。2个主节点,负责写。2个从节点负责读,实现了读写分离,总共4个节点。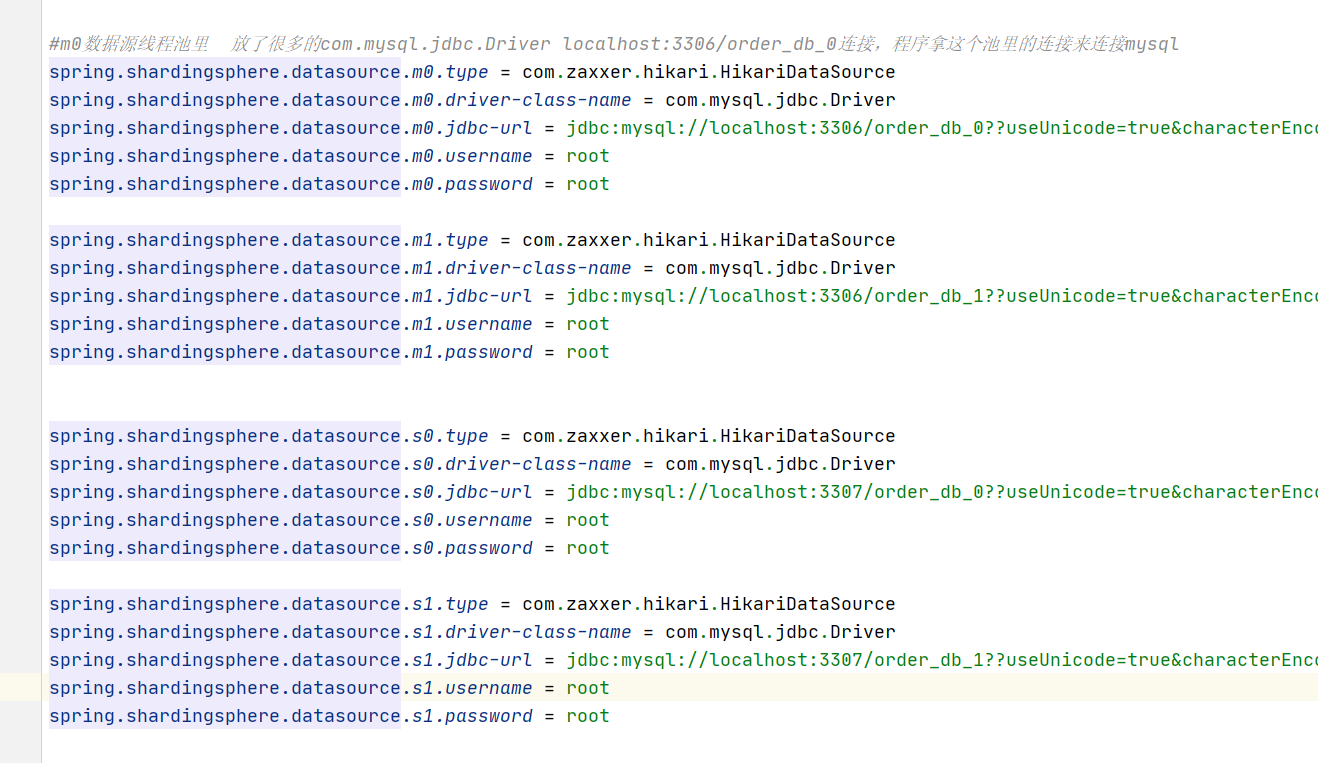

二、设置主从关系
一个主从关系,对应一个名称。2个业务节点那就是有两个主从关接
三、设置业务节点分库逻辑
有2个业务节点,就直接user_id%2了,因为取值为0-1嘛。
四、设置业务节点分表逻辑
有3个逻辑表。
五、选配公共表
六、真实场景注意
一般最少设3个节点3个分表。也就是分库逻辑,分表逻辑要最少%3。
因为, 一般项目的并发不会很高,基本不会在同一毫秒内产生多个并发,那么每个不同毫秒产生的第一个nextId雪花值,都为偶数。那么%2值,百分百为0。这样的话所有数据都在一个库中了,就不能上平均分到每个节点上了。
spring:redis:host: 127.0.0.1port: 6379shardingsphere:datasource:# names: m$->{0..2}names: m$->{0}m0:type: com.zaxxer.hikari.HikariDataSourcedriverClassName: com.mysql.jdbc.Driverjdbc-url: jdbc:mysql://localhost:3306/task_chat_task_0?useUnicode=true&characterEncoding=UTF-8&useSSL=false&serverTimezone=GMT%2B8username: rootpassword: root# m1:# type: com.zaxxer.hikari.HikariDataSource# driverClassName: com.mysql.jdbc.Driver# jdbc-url: jdbc:mysql://localhost:3306/task_chat_task_1?useUnicode=true&characterEncoding=UTF-8&useSSL=false&serverTimezone=GMT%2B8# username: root# password: root# m2:# type: com.zaxxer.hikari.HikariDataSource# driverClassName: com.mysql.jdbc.Driver# jdbc-url: jdbc:mysql://localhost:3306/task_chat_task_2?useUnicode=true&characterEncoding=UTF-8&useSSL=false&serverTimezone=GMT%2B8# username: root# password: rootsharding:tables:task:# actualDataNodes: m$->{0..2}.taskactualDataNodes: m$->{0}.taskdatabase-strategy:inline:shardingColumn: task_idalgorithmExpression: m$->{task_id%1}chat:# actualDataNodes: m$->{0..2}.chatactualDataNodes: m$->{0}.chatdatabase-strategy:inline:shardingColumn: chat_idalgorithmExpression: m$->{chat_id%1}list:# actualDataNodes: m$->{0..2}.listactualDataNodes: m$->{0}.listdatabase-strategy:inline:shardingColumn: list_idalgorithmExpression: m$->{list_id%1}props:sql:show: trueserver:port: 1003seata:enabled: trueservice:vgroup-mapping: defaultgrouplist:default: 127.0.0.1:8091disable-global-transaction: falsedubbo:registry:address: spring-cloud://127.0.0.1protocol:name: dubboport: -1scan:base-packages: springcloudspring:shardingsphere:datasource:names: m0m0:type: com.zaxxer.hikari.HikariDataSourcedriverClassName: com.mysql.jdbc.Driverjdbc-url: jdbc:mysql://localhost:3306/taskchat_user_0?useUnicode=true&characterEncoding=UTF-8&useSSL=false&serverTimezone=GMT%2B8username: rootpassword: rootsharding:tables:user:# 不分表,2020。10。5认为分表没必要# actualDataNodes: m0.user_$->{0..2}actualDataNodes: m0.user# tableStrategy:# inline:# shardingColumn: user_id# algorithmExpression: user_$->{user_id%3}database-strategy:inline:shardingColumn: phonealgorithmExpression: m$->{phone%1}props:sql:show: trueredis:host: 127.0.0.1port: 6379server:port: 1001seata:enabled: trueservice:vgroup-mapping: defaultgrouplist:default: 127.0.0.1:8091disable-global-transaction: falsesms:id: LTAI4G1SPA3fPuZBHESLZzVzsercret: ck4fY3W4pkSwEHR4XF0qDky0hS2OWO





























【授权流程】")



还没有评论,来说两句吧...