Spark之Shuffle总结
Shuffle概念
shuffle,是一种多对多的依赖关系,即每个Reduce Task从每个Map Task产生数的据中读取一片数据,极限情况下可能触发M*R个数据拷贝通道(M是Map Task数目,R是Reduce Task数目)。
Shuffle描述着数据从map task输出到reduce task输入的这段过程。shuffle是连接Map和Reduce之间的桥梁,Map的输出要到Reduce中必须经过shuffle这个环节,shuffle的性能高低直接影响了整个程序的性能和吞吐量。
因为在分布式情况下,reduce task需要跨节点去拉取其它节点上的map task结果。这一过程将会产生网络资源消耗和内存,磁盘IO的消耗。
通常shuffle分为两部分:
Map阶段的数据准备和Reduce阶段的数据拷贝处理。
一般将在map端的Shuffle称之为Shuffle Write;
在Reduce端的Shuffle称之为Shuffle Read。
Spark 的 Shuffle 过程与 MapReduce 的 Shuffle 过程有着诸多类似,一些概念可直接套用,例如,Shuffle 过程中,
提供数据的一端,被称作 Map 端,Map 端每个生成数据的任务称为 Mapper;对应的,
接收数据的一端,被称作 Reduce 端,Reduce 端每个拉取数据的任务称为 Reducer;
Shuffle 过程本质上都是将 Map 端获得的数据使用分区器进行划分,并将数据发送给对应的 Reducer 的过程。
为什么需要 Shuffle?
因为需要将具有某种共同特征的一类数据汇聚到一个节点上进行计算。
Shuffle分类
1、hashshuffle : 默认不排序,直接进行shuffle
2、sortshuffle :默认先进行排序。在shuffle
3、Tungsten(钨丝) shuffle : 在sortshuffle的基础上对内存进行了优化
Shuffle定义
与 MapReduce 的 Shuffle 类似,即在分区之间重新分配数据,将数据打乱重新汇聚到不同节点的过程。
还是以 WordCount 为例。如下图所示:
对一个分区上进行map和flatMap可以如同流水线一样只在同一台的机器上进行,不存在多个节点之间的数据移动,而 reduceByKey 这样的操作,需要将相同的 key 做聚合操作。
上图中 Stage1 中按 key 做 hash 分配三个分区做 reduce 操,对于 Stage2 中任意一个分区而言,其输入可能存在与上游 Stage1 中每一个分区中,因此需要从上游的每一个分区所在的机器上拉取数据,这个过程称为Shuffle。
Shuffle过程的核心方法
Spark Shuffle 分为 Write 和 Read 两个过程。在 Spark 中负责 shuffle 过程的执行、计算、处理的组件主要是 ShuffleManager,其是一个 trait,负责管理本地以及远程的 block 数据的 shuffle 操作。
所有方法如下图所示。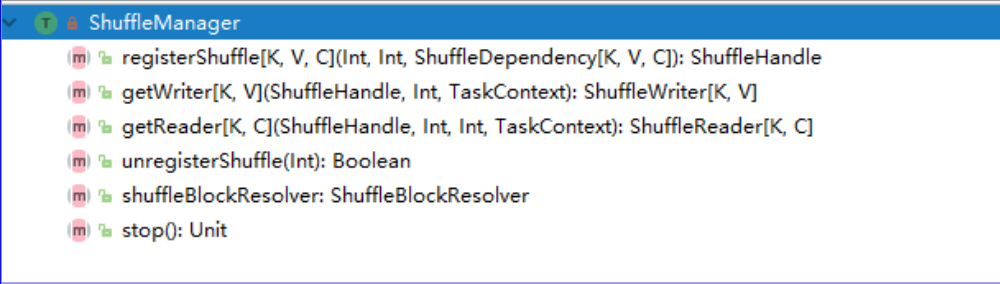
主要方法解释:
- registerShuffle:注册 ShuffleDependency(宽依赖),同时获取一个ShuffleHandle 并将其传递给任务。
- getWriter:返回 ShuffleWriter 用于 Shuffle Write 过程。对一个分区返回一个 ShuffleWriter,并由 executors 上的 ShuffleMapTask 任务调用。
- getReader:返回 ShuffleReader 用于 Shuffle Read 过程。
map端的Shuffle简述:
- input:根据split输入数据,运行map任务;
- patition: 每个map task都有一个内存缓冲区,存储着map的输出结果;
- spill:当缓冲区快满的时候需要将缓冲区的数据以临时文件的方式存放到磁盘;
- merge: 当整个map task结束后再对磁盘中这个map task产生的所有临时文件做合并,生成最终的正式输出文件,然后等待reduce task来拉数据。
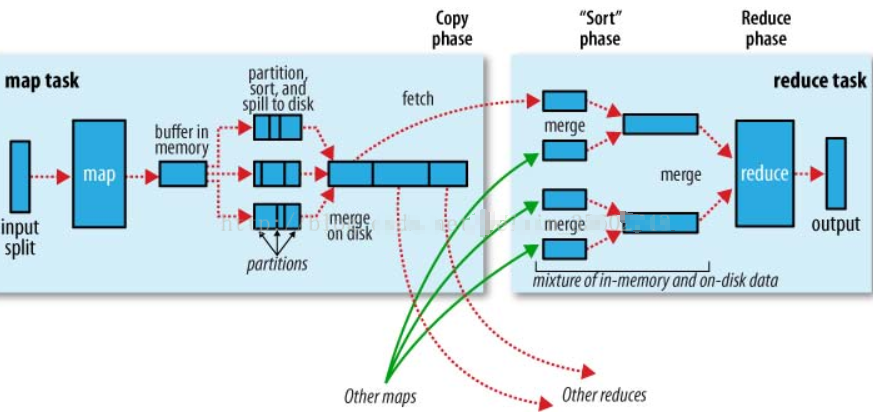
reduce端的Shuffle简述:
reduce task在执行之前的工作就是不断地拉取当前job里每个map task的最终结果,然后对从不同地方拉取过来的数据不断地做merge,也最终形成一个文件作为reduce task的输入文件。
- Copy过程,拉取数据
- Merge阶段,合并拉取来的小文件
- Reducer计算
- Output输出计算结果
如下图所示,形象的描述了MR数据流动的整个过程: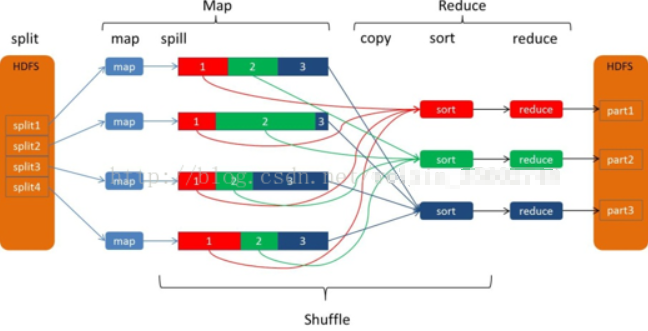
解析上图:
map端,有4个map;Reduce端,有3个reduce。4个map 也就是4个JVM,每个JVM处理一个数据分片(split1~split4),每个map产生一个map输出文件;
但是每个map都为后面的reduce产生了3部分数据(分别用红1、绿2、蓝3标识),也就是说每个输出的map文件都包含了3部分数据。
mapper运行后,通过Partitioner接口,根据key或value及reduce的数量来决定当前map的输出数据最终应该交由哪个reduce task处理.Reduce端一共有3个reduce,去前面的4个map的输出结果中抓取属于自己的数据。
我们知道stage中是高效快速的pipline的计算模式,宽依赖才会发生 shuffle 操作,因此宽依赖之间会划分stage,而Stage之间就是Shuffle,shuffle 是划分 DAG 中 stage 的标识,同时影响 Spark 执行速度的关键步骤.
Shuffle流程
shuffle 过程内存分配使用 ShuffleMemoryManager 类管理,会针对每个 Task 分配内存,Task 任务完成后通过 Executor 释放空间.这里可以把 Task 理解成不同 key 的数据对应一个 Task.
早期的内存分配机制使用公平分配,即不同 Task 分配的内存是一样的,但是这样容易造成内存需求过多的 Task 的 OutOfMemory, 从而造成多余的 磁盘 IO 过程,影响整体的效率.(例:某一个 key 下的数据明显偏多,但因为大家内存都一样,这一个 key 的数据就容易 OutOfMemory).
1.5版以后 Task 共用一个内存池,内存池的大小默认为 JVM 最大运行时内存容量的16%;
分配机制如下:
假如有 N 个 Task,ShuffleMemoryManager 保证每个 Task 溢出之前至少可以申请到1/2N 内存,且至多申请到1/N,N 为当前活动的 shuffle Task 数,因为N 是一直变化的,所以 manager 会一直追踪 Task 数的变化,重新计算队列中的1/N 和1/2N;
但是这样仍然容易造成内存需要多的 Task 任务溢出,所以最近有很多相关的研究是针对 shuffle 过程内存优化的.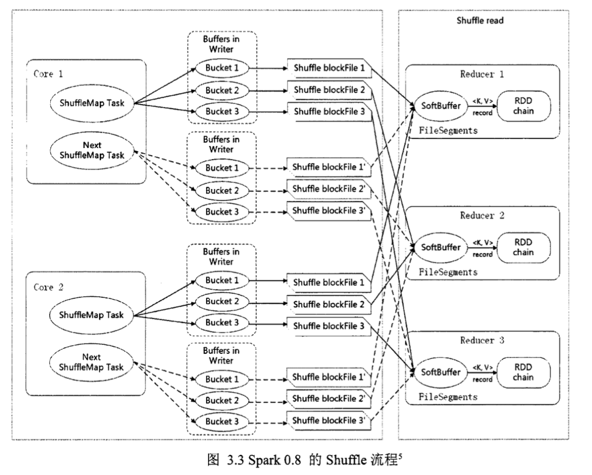
ShuffleManager随着Spark的发展有两种实现的方式,分别为HashShuffleManager和SortShuffleManager,因此spark的Shuffle有Hash Shuffle和Sort Shuffle两种。
在早期版本中,ShuffleManager 的实现者是 HashShuffleManager,而新版本中只有 SortShuffleManager。前者存在的问题:会产生大量的磁盘文件,进而有大量的磁盘 IO 操作,比较影响性能。
SortShuffleManager 相对来说,有了一定的改进。主要就在于,每个 Task 在 Shuffle Write 操作时,虽然也会产生较大的磁盘文件,但最后会将所有的临时文件合并 (merge) 成一个磁盘文件,因此每个 Task 就只有一个磁盘文件。在下一个 Stage 的 Shuffle Read Task 拉取自己数据的时候,只要根据索引拉取每个磁盘文件中的部分数据即可。
Hash Shuffle
HashShuffleManager的运行机制主要分成两种,一种是普通运行机制,另一种是合并的运行机制。
合并机制主要是通过复用buffer来优化Shuffle过程中产生的小文件的数量。Hash shuffle是不具有排序的Shuffle。
1.普通机制的Hash Shuffle
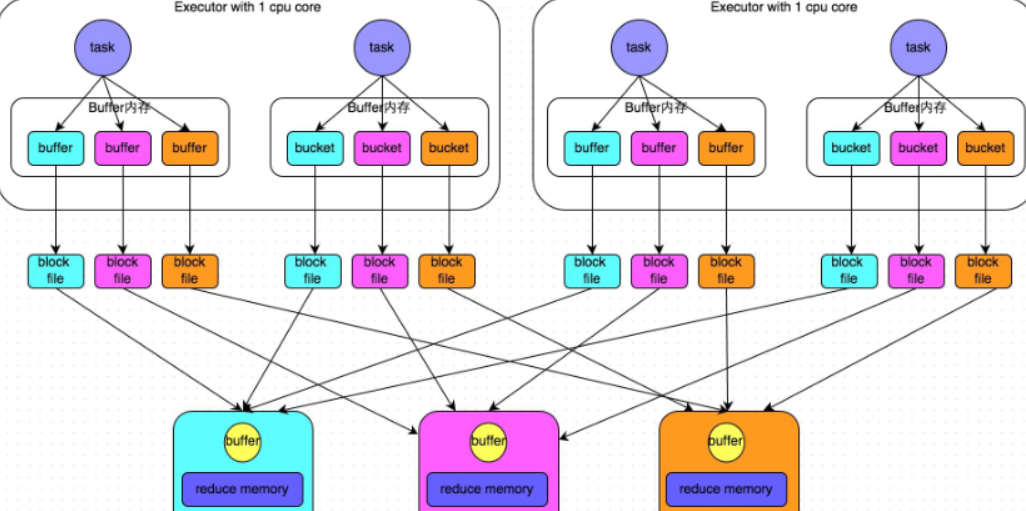
解析上图:
这里我们先明确一个假设前提:每个Executor只有1个CPU core,也就是说,无论这个Executor上分配多少个task线程,同一时间都只能执行一个task线程。
图中有3个 Reducer,从Task 开始那边各自把自己进行 Hash 计算(分区器:hash/numreduce取模),分类出3个不同的类别,每个 Task 都分成3种类别的数据,想把不同的数据汇聚然后计算出最终的结果,所以Reducer 会在每个 Task 中把属于自己类别的数据收集过来,汇聚成一个同类别的大集合,每1个 Task 输出3份本地文件,这里有4个 Mapper Tasks,所以总共输出了4个 Tasks x 3个分类文件 = 12个本地小文件。
执行流程
- 每一个map task将不同结果写到不同的buffer中,每个buffer的大小为32K。buffer起到数据缓存的作用,缓存能够加速写磁盘,提高计算的效率。
- 每个buffer文件最后对应一个磁盘小文件。
- reduce task来拉取对应的磁盘小文件。
总结
- map task的计算结果会根据分区器(默认是hashPartitioner)来决定写入到哪一个磁盘小文件中去。ReduceTask会去Map端拉取相应的磁盘小文件。
- 产生的磁盘小文件的个数:M(map task的个数)* R(reducetask的个数)
- 分区器:根据hash/numRedcue取模决定数据由几个Reduce处理,也决定了写入几个buffer中
- M为map task的数量,R为Reduce的数量,一般Reduce的数量等于buffer的数量,都是由分区器决定的
存在的问题
产生的磁盘小文件过多,会导致以下问题:
- 在Shuffle Write过程中会产生很多写磁盘小文件的对象。
- 在Shuffle Read过程中会产生很多读取磁盘小文件的对象。
- 在JVM堆内存中对象过多会造成频繁的gc,gc还无法解决运行所需要的内存 的话,就会OOM。
- 在数据传输过程中会有频繁的网络通信,频繁的网络通信出现通信故障的可能性大大增加,一旦网络通信出现了故障会导致shuffle file cannot find 由于这个错误导致的task失败,TaskScheduler不负责重试,由DAGScheduler负责重试Stage。
2.合并机制的Hash Shuffle
合并机制就是复用buffer,开启合并机制的配置是spark.shuffle.consolidateFiles。该参数默认值为false,将其设置为true即可开启优化机制。
通常来说,如果我们使用HashShuffleManager,那么都建议开启这个选项。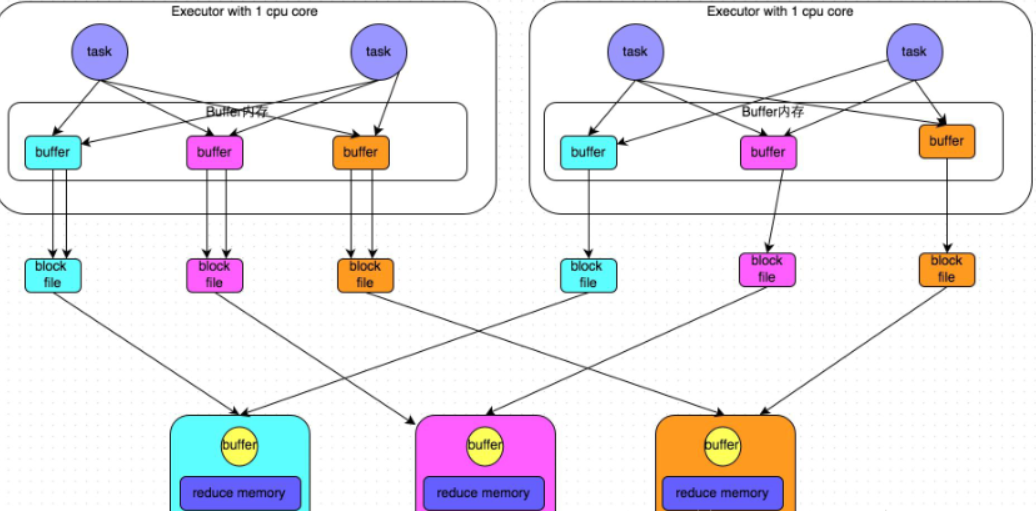
这里还是有4个Tasks,数据类别还是分成3种类型,因为Hash算法会根据你的 Key 进行分类,在同一个进程中,无论是有多少过Task,都会把同样的Key放在同一个Buffer里,然后把Buffer中的数据写入以Core数量为单位的本地文件中,(一个Core只有一种类型的Key的数据),每1个Task所在的进程中,分别写入共同进程中的3份本地文件,这里有4个Mapper Tasks,所以总共输出是 2个Cores x 3个分类文件 = 6个本地小文件。
解析上图:
开启consolidate机制之后,在shuffle write过程中,task就不是为下游stage的每个task创建一个磁盘文件了。此时会出现shuffleFileGroup的概念,每个shuffleFileGroup会对应一批磁盘文件,磁盘文件的数量与下游stage的task数量是相同的。一个Executor上有多少个CPU core,就可以并行执行多少个task。而第一批并行执行的每个task都会创建一个shuffleFileGroup,并将数据写入对应的磁盘文件内。
Executor的CPU core执行完一批task,接着执行下一批task时,下一批task就会复用之前已有的shuffleFileGroup,包括其中的磁盘文件。也就是说,此时task会将数据写入已有的磁盘文件中,而不会写入新的磁盘文件中。因此,consolidate机制允许不同的task复用同一批磁盘文件,这样就可以有效将多个task的磁盘文件进行一定程度上的合并,从而大幅度减少磁盘文件的数量,进而提升shuffle write的性能。
假设第二个stage有100个task,第一个stage有50个task,总共还是有10个Executor,每个Executor执行5个task。那么原本使用未经优化的HashShuffleManager时,每个Executor会产生500个磁盘文件,所有Executor会产生5000个磁盘文件的。但是此时经过优化之后,每个Executor创建的磁盘文件的数量的计算公式为:CPU core的数量 * 下一个stage的task数量。也就是说,每个Executor此时只会创建100个磁盘文件,所有Executor只会创建1000个磁盘文件。
注意:
- 启动HashShuffle的合并机制ConsolidatedShuffle的配置:
spark.shuffle.consolidateFiles=true - 产生磁盘小文件的个数 = Core*R
Core为CPU的核数,R为Reduce的数量
存在的问题
如果 Reducer 端的并行任务或者是数据分片过多的话则 Core * Reducer Task 依旧过大,也会产生很多小文件。
Sort Shuffle
SortShuffleManager的运行机制主要分成两种,一种是普通运行机制,另一种是bypass运行机制
当shuffle read task的数量小于等于spark.shuffle.sort.bypassMergeThreshold参数的值时(默认为200),就会启用bypass机制。
1.Sort shuffle的普通机制
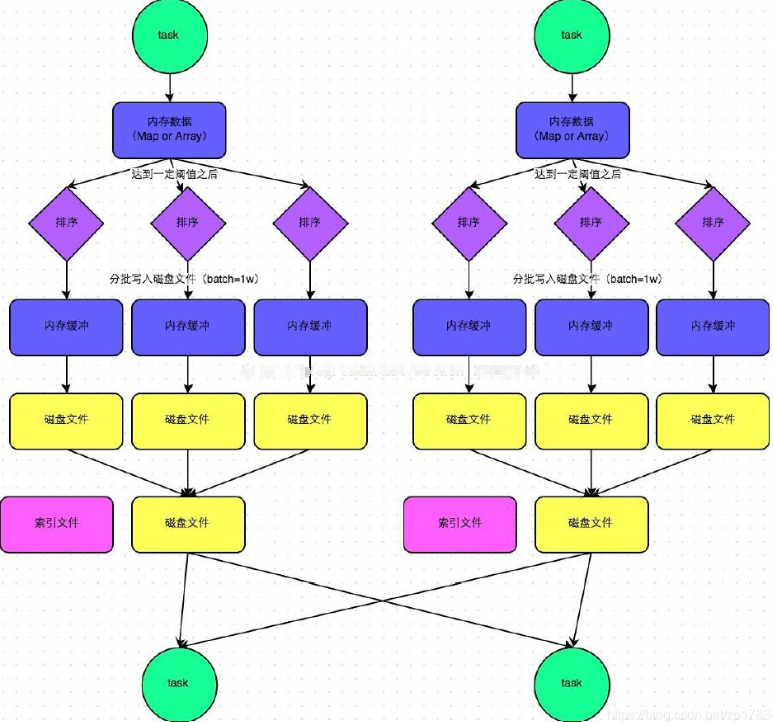
该图说明了普通的SortShuffleManager的原理。在该模式下,数据会先写入一个内存数据结构中(默认5M),此时根据不同的shuffle算子,可能选用不同的数据结构。如果是reduceByKey这种聚合类的shuffle算子,那么会选用Map数据结构,一边通过Map进行聚合,一边写入内存;
如果是join这种普通的shuffle算子,那么会选用Array数据结构,直接写入内存。接着,每写一条数据进入内存数据结构之后,就会判断一下,是否达到了某个临界阈值。如果达到临界阈值的话,那么就会尝试将内存数据结构中的数据溢写到磁盘,然后清空内存数据结构。
注意:
- shuffle中的定时器:定时器会检查内存数据结构的大小,如果内存数据结构空间不够,那么会申请额外的内存,申请的大小满足如下公式:
applyMemory=nowMenory*2-oldMemory - 申请的内存 = 当前的内存情况*2 - 上一次内嵌的情况
意思就是说内存数据结构的大小的动态变化,如果存储的数据超出内存数据结构的大小,将申请内存数据结构存储的数据*2-内存数据结构的设定值的内存大小空间。申请到了,内存数据结构的大小变大,内存不够,申请不到,则发生溢写。
排序
在溢写到磁盘文件之前,会先根据key对内存数据结构中已有的数据进行排序。
溢写
排序过后,会分批将数据写入磁盘文件。默认的batch数量是10000条,也就是说,排序好的数据,会以每批1万条数据的形式分批写入磁盘文件。写入磁盘文件是通过Java的BufferedOutputStream实现的。BufferedOutputStream是Java的缓冲输出流,首先会将数据缓冲在内存中,当内存缓冲满溢之后再一次写入磁盘文件中,这样可以减少磁盘IO次数,提升性能。
merge
一个task将所有数据写入内存数据结构的过程中,会发生多次磁盘溢写操作,也就会产生多个临时文件。最后会将之前所有的临时磁盘文件都进行合并,这就是merge过程,此时会将之前所有临时磁盘文件中的数据读取出来,然后依次写入最终的磁盘文件之中。
此外,由于一个task就只对应一个磁盘文件,也就意味着该task为Reduce端的stage的task准备的数据都在这一个文件中,因此还会单独写一份索引文件,其中标识了下游各个task的数据在文件中的start offset与end offset。
SortShuffleManager由于有一个磁盘文件merge的过程,因此大大减少了文件数量。比如第一个stage有50个task,总共有10个Executor,每个Executor执行5个task,而第二个stage有100个task。由于每个task最终只有一个磁盘文件,因此此时每个Executor上只有5个磁盘文件,所有Executor只有50个磁盘文件。
注意:
- block file= 2M
一个map task会产生一个索引文件和一个数据大文件 - m*r>2m(r>2):
SortShuffle会使得磁盘小文件的个数再次的减少
执行流程:
- map task 的计算结果会写入到一个内存数据结构里面,内存数据结构默认是5M
- 在shuffle的时候会有一个定时器,不定期的去估算这个内存结构的大小,当内存结构中的数据超过5M时,比如现在内存结构中的数据为5.01M,那么他会申请5.01*2-5=5.02M内存给内存数据结构。
- 如果申请成功不会进行溢写,如果申请不成功,这时候会发生溢写磁盘。
- 在溢写之前内存结构中的数据会进行排序分区
- 然后开始溢写磁盘,写磁盘是以batch的形式去写,一个batch是1万条数据
- map task执行完成后,会将这些磁盘小文件合并成一个大的磁盘文件,同时生成一个索引文件
- reduce task去map端拉取数据的时候,首先解析索引文件,根据索引文件再去拉取对应的数据
2.bypass运行机制
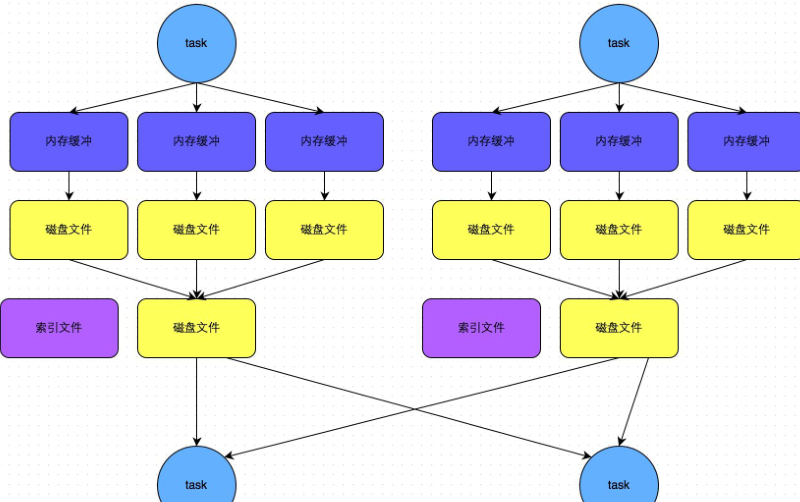
bypass运行机制的触发条件如下:
- shuffle map task数量小于spark.shuffle.sort.bypassMergeThreshold参数的值。
- 不是聚合类的shuffle算子(比如reduceByKey)。
此时task会为每个reduce端的task都创建一个临时磁盘文件,并将数据按key进行hash然后根据key的hash值,将key写入对应的磁盘文件之中。当然,写入磁盘文件时也是先写入内存缓冲,缓冲写满之后再溢写到磁盘文件的。最后,同样会将所有临时磁盘文件都合并成一个磁盘文件,并创建一个单独的索引文件。
该过程的磁盘写机制其实跟未经优化的HashShuffleManager是一模一样的,因为都要创建数量惊人的磁盘文件,只是在最后会做一个磁盘文件的合并而已。因此少量的最终磁盘文件,也让该机制相对未经优化的HashShuffleManager来说,shuffle read的性能会更好。
而该机制与普通SortShuffleManager运行机制的不同在于:
第一,磁盘写机制不同;
第二,不会进行排序。也就是说,启用该机制的最大好处在于,shuffle write过程中,不需要进行数据的排序操作,也就节省掉了这部分的性能开销。
总结:
- Shuffle 过程本质上都是将 Map 端获得的数据使用分区器进行划分,并将数据发送给对应的 Reducer 的过程。
- shuffle作为处理连接map端和reduce端的枢纽,其shuffle的性能高低直接影响了整个程序的性能和吞吐量。map端的shuffle一般为shuffle的Write阶段,reduce端的shuffle一般为shuffle的read阶段。Hadoop和spark的shuffle在实现上面存在很大的不同,spark的shuffle分为两种实现,分别为HashShuffle和SortShuffle。
- HashShuffle又分为普通机制和合并机制,普通机制因为其会产生M * R个数的巨量磁盘小文件而产生大量性能低下的Io操作,从而性能较低,因为其巨量的磁盘小文件还可能导致OOM,HashShuffle的合并机制通过重复利用buffer从而将磁盘小文件的数量降低到Core*R个,但是当Reducer 端的并行任务或者是数据分片过多的时候,依然会产生大量的磁盘小文件。
- SortShuffle也分为普通机制和bypass机制,普通机制在内存数据结构(默认为5M)完成排序,会产生2M个磁盘小文件。而当shuffle map task数量小于spark.shuffle.sort.bypassMergeThreshold参数的值。或者算子不是聚合类的shuffle算子(比如reduceByKey)的时候会触发SortShuffle的bypass机制,SortShuffle的bypass机制不会进行排序,极大的提高了其性能。
- 在Spark 1.2以前,默认的shuffle计算引擎是HashShuffleManager,因为HashShuffleManager会产生大量的磁盘小文件而性能低下,
- 在Spark 1.2以后的版本中,默认的ShuffleManager改成了SortShuffleManager。SortShuffleManager相较于HashShuffleManager来说,有了一定的改进。主要就在于,每个Task在进行shuffle操作时,虽然也会产生较多的临时磁盘文件,但是最后会将所有的临时文件合并(merge)成一个磁盘文件,因此每个Task就只有一个磁盘文件。在下一个stage的shuffle read task拉取自己的数据时,只要根据索引读取每个磁盘文件中的部分数据即可。
Shuffle文件寻址
1.MapOutputTracker
MapOutputTracker是Spark架构中的一个模块,是一个主从架构。管理磁盘小文件的地址。
- MapOutputTrackerMaster是主对象,存在于Driver中。
- MapOutputTrackerWorker是从对象,存在于Excutor中。
2.BlockManager
BlockManager块管理者,是Spark架构中的一个模块,也是一个主从架构。
- BlockManagerMaster:主对象,存在于Driver中。
BlockManagerMaster会在集群中有用到广播变量和缓存数据或者删除缓存数据的时候,通知BlockManagerSlave传输或者删除数据。 - BlockManagerWorker:从对象,存在于Excutor中。
BlockManagerWorker会与BlockManagerWorker之间通信。
注意:
无论在Driver端的BlockManager还是在Excutor端的BlockManager都含有四个对象:
- DiskStore:负责磁盘的管理
- MemoryStore:负责内存的管理
- ConnectionManager:负责连接其他的BlockManagerWorker
- BlockTransferService:负责数据的传输
3.Shuffle文件寻址图

4.Shuffle文件寻址流程
- 当map task执行完成后,会将task的执行情况和磁盘小文件的地址封装到MpStatus对象中,通过MapOutputTrackerWorker对象向Driver中的MapOutputTrackerMaster汇报。
- 在所有的map task执行完毕后,Driver中就掌握了所有的磁盘小文件的地址。
- 在reduce task执行之前,会通过Excutor中MapOutPutTrackerWorker向Driver端的MapOutputTrackerMaster获取磁盘小文件的地址。
- 获取到磁盘小文件的地址后,会通过BlockManager中的ConnectionManager连接数据所在节点上的ConnectionManager,然后通过BlockTransferService进行数据的传输。
- BlockTransferService 默认启动 5 个 task 去节点拉取数据。默认情况下,5 个 task 拉取数据量不能超过 48 M。拉取过来的数据放在 Executor端的shuffle聚合内存中(spark.shuffle.memeoryFraction 0.2), 如果5 个 task 一次拉取的数据放不到shuffle内存中会有 OOM,如果放下一次,不会有 OOM,以后放不下的会放磁盘。
shuffle的总结就暂时写到这里,后面小编还会对shuffle的 write和read操作做具体演练,记得关注小编




























还没有评论,来说两句吧...