MySQL之EXPLAIN
关键词:explain 索引
EXPLAIN提供了关于MySQL如何执行语句的信息,即执行计划。可以用在SELECT、UPDATE、INSERT、REPLACE等语句前,本文主要讨论的是SELECT。通常使用EXPLAIN SELECT,结合分析返回结果,对SQL语句进行优化。
<文中案例操作使用的MySQL版本为:5.7.32,版本不同会存在差异>
比如下文中的例子,同样的查询语句,通过EXPLAINE查看执行计划,得到的结果有所不同。
5.1.73版本:

5.7.31版本:

从上面的两个结果比较可以看出,版本的不同,不仅仅是字段中的内容不同,而且,5.7.31版本要比5.1.73版本中多了两列:partitions、filtered。
█ 使用
以下结果截图,如果没有指明具体的版本,都是在5.7.31版本中执行后的结果。
①创建表和索引,并插入数据
drop table if exists STUDENT;create table STUDENT(id int primary key auto_increment,car_id varchar(5),first_name varchar(10),last_name varchar(10),class_id int,index index_name(first_name, last_name));create index index_car_id on STUDENT(car_id);insert into STUDENT(car_id,first_name,last_name,class_id) values('111','Jim', 'Green',1);insert into STUDENT(car_id,first_name,last_name,class_id) values('111','Dave', 'Brice',1);insert into STUDENT(car_id,first_name,last_name,class_id) values('222','Ann', 'King',2);insert into STUDENT(car_id,first_name,last_name,class_id) values('222','Rose', 'Rice',3);insert into STUDENT(car_id,first_name,last_name,class_id) values('333','jack', 'ma',4);drop table if exists CLASS;create table CLASS(id int primary key auto_increment,name varchar(10));create index index_name on CLASS(name);insert into CLASS(name) values('语文');insert into CLASS(name) values('数学');insert into CLASS(name) values('英语');
 student表数据
student表数据
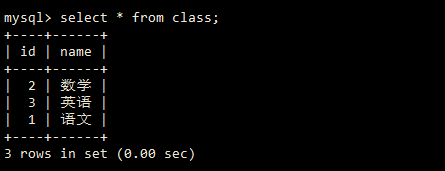 class表数据
class表数据 student表索引
student表索引 class表索引
class表索引
②使用explain查看表结构
语法:explain 表名;
此用法和desc相同。

③使用explain查看执行计划
语法:explain select语句;

█ 执行计划
- id:查询的标识
用来区分每组查询。值是个有序递增数字,从1开始。值相同时,表示是一组查询,值不同时,表示不同组的查询。值越大,优先级越高,越先被执行。值相同时,按照结果表格中从上到下依次执行。比如查看select s.first_name, (select c.name from CLASS c) from STUDENT s; 的执行计划:

返回结果的id不同,数字越大越优先执行。select c.name from CLASS c语句的id为2,则会先被执行,然后再执行select s.first_name from STUDENT s;再比如查看select * from STUDENT where CLASS_ID in (select name from CLASS); 的执行计划:

从返回结果的id相同,从上到下依次执行。select * from STUDENT语句在上,先被执行,接着再执行select name from CLASS。
- select_type:查询的连接类型
有以下可选项,不同的值表示不同的类:
①SIMPLE
简单查询,没有使用UNION的查询或子查询。比如查看select * from STUDENT where id=1; 的执行计划:

②PRIMARY
在UNION或者子查询中,最外层的查询会是此类型,即最后被执行的语句。比如查看子查询:select s.first_name, (select c.name from CLASS c) from STUDENT s;的执行计划:

从id的值可以看出,id=1的查询语句是最后被执行的,其select_type就是PRIMARY类型的。再比如查看UNION查询:select s.first_name from STUDENT s union all select c.name from CLASS c;的执行计划:

③UNION
对于UNION查询,不是最后一个执行的语句会是此类型,因为最后一个被执行的语句是PRIMARY类型。比如查看select s.first_name from STUDENT s union all select c.name from CLASS c union all select class.id from CLASS class;三张表使用UNION的执行计划:

④DEPENDENT UNION
个人认为,对于UNION查询,如果PRIMARY类型的查询语句需要依赖UNION的某个语句,则这个被依赖的语句会是DEPENDENT UNION类型。所谓依赖是指需要使用到语句的查询结果。比如查看select * from STUDENT stu where stu.first_name in (select s.first_name from STUDENT s union select c.name from CLASS c);的执行计划:

⑤UNION RESULT
UNION查询的结果,根据(4)中图片最后一行可以看到此类型,并且当select_type是NUION RESULT时,id为NULL。
⑥SUBQUERY
子查询中的第一个查询语句,即子查询中最后一个被执行的语句。比如查看select FIRST_NAME, (select c.name from CLASS c) as className from STUDENT;的执行计划:

图中的子查询select c.name from CLASS c,因为此语句的结果不会被select from student所依赖,所以是SUBQUERY,如果被依赖了,则是下面的DEPENDENT SUBQUERY类型
⑦DEPENDENT SUBQUERY
个人认为是在子查询中,结果被PRIMARY类型的语句所依赖的会是此类型。比如在5.1.7版本中查看select * from STUDENT where FIRST_NAME in (select id from CLASS);的执行计划(此语句在5.7.31中获得的结果不一样):
 5.1.7版本执行结果
5.1.7版本执行结果
⑧DERIVED
派生表。比如查看select * from (select now() from dual) d; 的执行计划,其中(select now() from dual) d就是派生表。

⑨MATERIALIZED
物化子查询。
⑩UNCACHEABLE SUBQUERY
子查询每次都不是从缓存中查询的。不能缓存其结果的子查询,并且必须针对类型为PRIMARY的每次查询的每一行重新求值。
⑪UNCACHEABLE UNION
和UNCACHEABLE SUBQUERY一样,只不过是针对UNION查询的。
- table
查询的表名。当指定了别名,则显示别名。没有指定别名使用实际的表名。
未指定别名:

指定了别名:

并且区分大小写:

- partitions
查询的分区,当没有设置多个分区时,为NULL。
- type
表连接的类型。有如下几种表连接类型,查询的效率依次从高到低。
①system
查询只有一条记录的系统表。是一种特殊的const类型。比如sys数据库中的version表:

从执行计划结果看出,我猜测,执行select * from sys.version,感觉是执行了select version() from dual后再查询的。
②const
使用主键索引或唯一键索引等值查询表(使用=),即查询的索引列数据没有重复值,查询的结果最多有一条命中。比如:重新往STUDENT中插入多条数据,然后查询select * from STUDENT stu where stu.id = 3;的执行计划,其中id是主键索引。

再比如查询select * from student where class_id = 3;的执行计划,其中class_id列虽然是索引,但是不是唯一值,是有重复值的:

③eq_ref
连接查询时,表与表之间通过副表(左连接的右表或右连接的左表)的主键索引或者唯一键且不为NULL的索引作为连接条件的。比如查看select * from STUDENT s left join CLASS c on s.CAR_ID = c.id;连接查询的执行计划,查询条件使用了CLASS表的主键id索引,在左连接中,CLASS表是右表,是副表。

比如查看select * from STUDENT s left join CLASS c on s.id = c.name;的执行计划,使用了左表(主表)的主键id索引,但是结果类型并不是eq_ref:

④ref
ref反应的是查询条件用到的索引,不是主键索引和唯一索引,即索引列的值有重复值。比如查看select * from STUDENT where car_id = ‘111’;的执行计划,其中car_id列是索引,但是有重复值。

⑤fulltext
全文索引的类型。
⑥ref_or_null
在ref类型的基础上,加上了查询NULL值的情况。比如在5.1.7版本中查看select * from STUDENT where CAR_ID = ‘111’ or CAR_ID is NULL的执行计划:
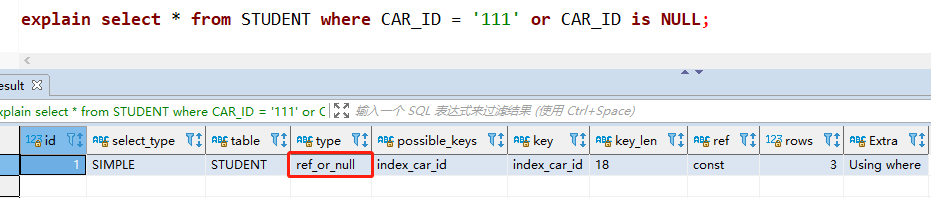 5.1.7版本执行结果
5.1.7版本执行结果
⑦index_merge
索引合并。
⑧unique_subquery
唯一结果的子查询,即子查询返回的结果是唯一索引列(主键索引是特殊的唯一索引)。比如在5.1.7版本中查看select * from STUDENT where id in (select id from CLASS);的执行计划,其中子查询select id from CLASS返回的是CLASS主键列。

⑨index_subquery
(这个有点没搞清楚)和unique_subquery的区别是,子查询返回的结果是有重复值的索引列。比如在5.1.7版本中查看select * from STUDENT s1 where s1.FIRST_NAME in (select NAME from CLASS);的执行计划:
 5.1.7版本执行结果
5.1.7版本执行结果
⑩range
范围查询,使用=, <>, >, >=, <, <=, IS NULL, <=>, BETWEEN, LIKE 或 IN() 等操作符。比如查看select * from student where id in (1,2,3);和select * from student where id < 5;的执行计划:

⑪index
全表扫描索引表,不会去查询数据。查询的结果通过索引就能获取,即查询索引列的内容。比如查询select id from student where id <> 0;的执行计划,返回结果id通过索引数据就能获取到:

⑫ALL
全表扫描数据表,有两种情况,一种是查询没有使用索引,查找的时候需要遍历整张数据表去匹配数据,比如:select * from student;还有一种情况是使用了索引,但是还需要遍历整张数据表才能获取数据,比如:select * from student where id is not null;虽然id列是索引列,但是因为是select *,结果是需要查询所有表才能得到的。

- possible_keys
查询可能用到的索引,显示的是索引名。此内容只是可能用到的索引,实际未必会用到。
- key
查询实际用到的索引。
- key_len
查询实际用到的索引的长度。
- ref
在进行查询时,将什么类型的数据与索引列进行比较的。这里就是显示什么类型的数据。
- rows
查询过程查询了多少行数据才找到目标值,此值是个估计值。
- filtered
表示根据查询条件会过滤的行数的一个估计的百分比。最大值是100,表示没有过滤任何行。值从100减少表示过滤的次数增加。可能是查询最终的结果个数 / rows显示的条数 = filtered的百分比值。
- Extra
额外的信息。举例说明:
①Impossible WHERE
字面意思是不可能的where条件,当where条件永远是false的时候,会显示此信息。比如:select id from STUDENT where 1>2;

②Using index
此处有个功能叫索引下推,当使用辅助索引的时候,通过辅助索引就能得到要查询的结果,不需要再去查询主键索引去获取行数据了。比如:select id from student where car_id = ‘111’;其中car_id是辅助索引,辅助索引的叶子节点会记录其对应的主键id值的:

③no matching row in const table
使用唯一索引查询不到记录。比如:select * from student where id = 9;STUDENT表中总共有5条数据,id最大是5,根据id=9是查不到记录的:

④Using where
根据索引过滤不出数据,必须通过where条件进行过滤数据。

⑤Using filesort
在排序语句中,需要先根据where条件排序,再根据排序的内容去查询获得数据。一般在不适用索引的时候排序,或者使用辅助索引排序的时候出现。比如:select * from student order by class_id;其中class_id不是索引列。select * from student order by car_id;其中car_id虽然是索引列,但因为是select *,单单通过辅助索引是获取不到所有的字段信息的。

对于查询效率慢的sql,可以通过EXPLAIN查看执行计划,一般根据key来判断是否使用了索引,根据type、Extra信息来调整语句。
关于EXPLIANE的使用就到这里了,文章写的很浅显。关于EXPLAINE的使用和利用其优化SQL,需要在实际开发中经常使用,以此来体会。


































还没有评论,来说两句吧...