Kafka 顺序消费问题
自定义分区器
定义分区器
public class MyPartitioner implements Partitioner {private final AtomicInteger counter = new AtomicInteger(0);@Overridepublic int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {List<PartitionInfo> parts = cluster.partitionsForTopic(topic);int partitionSize = parts.size();if(key == null ){return counter.getAndIncrement() % partitionSize;}else{//默认分区器DefaultPartitioner采用了MurmurHash2算法进行hashreturn Utils.toPositive(Utils.murmur2(keyBytes)) % partitionSize;}}@Overridepublic void close() {}@Overridepublic void configure(Map<String, ?> map) {}}
增加配置
properties.setProperty(ProducerConfig.PARTITIONER_CLASS_CONFIG, MyPartitioner.class.getName());
顺序消费问题
Kafka的特性
- kafka中,写入一个partition分区中的数据是一定有顺序的。
- kafka中一个消费者消费一个partition的数据,消费者取出数据时,也是有顺序的。
多线程消费会导致消息乱序
比如说我们建了一个 topic,有三个 partition。生产者在写的时候,其实可以指定一个 key
- 比如说我们指定了某个订单 id 作为 key,那么这个订单相关的数据,一定会被分发到同一个 partition 中去,而且这个 partition 中的数据一定是有顺序的。
- 消费者从 partition 中取出来数据的时候,也一定是有顺序的。
接着,我们在消费者里可能会搞多个线程来并发处理消息。
- 因为如果消费者是单线程消费处理,而处理比较耗时的话,比如处理一条消息耗时几十 ms,那么 1 秒钟只能处理几十条消息,这吞吐量太低了。而多个线程并发跑的话,顺序可能就乱掉了。
- 由于消费者消费消息之后,有可能交给很多个线程去处理数据(如下图),这样就导致数据顺序错乱。
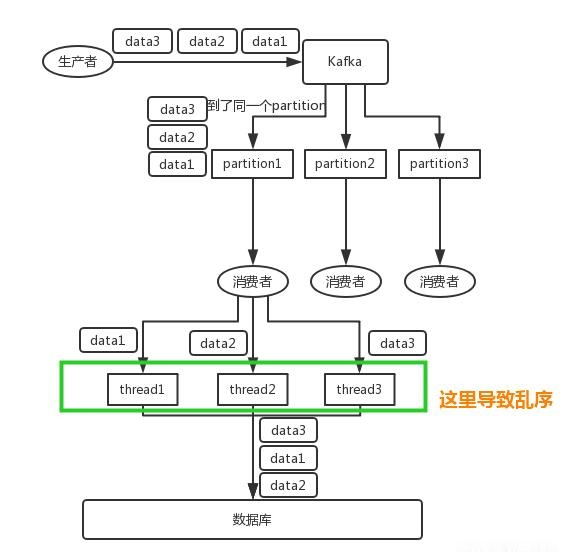
需要关注如下几个知识点:
- 写入一个partition中的数据,一定是有顺序的;
- 生产者在写消息的时候,可以指定一个key,比如指定订单的id作为key;则同一个订单相关数据,一定会分发到一个partition中去;
- 消费者从partition中取出数据的时候,一定是有顺序的;
解决消息的有序性
方案1:
一个 topic,一个 partition,一个 consumer,内部单线程消费,单线程吞吐量太低,一般不会用这个。
或者针对前面的方式进行改良,一个topic,多个partition,多个consumer 实例。
@KafkaListener(topics = { “mytopic”},
topicPartitions = { @TopicPartition(topic = "mytopic",partitions = { "1","3"})})
这种方式实现起来比较简单快捷,每一个消费者实例负责处理一个partition中的消息。
- 一个分区Partition不能被同一个消费组(Consumer Group)中多个消费者Consumer消息,这样就保证了Partition中消息消费的有序性。
方案2:
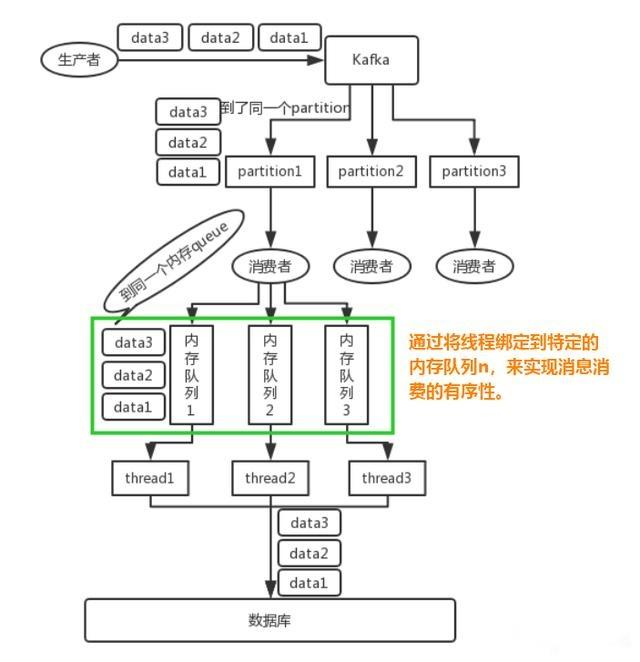
为了保证一个消费者中多个线程去处理时,不会使得消息的顺序被打乱,则可以在消费者中,消息分发至不同的线程时,加一个队列,消费者去做hash分发,将需要放在一起的数据,分发至同一个队列中,最后多个线程从队列中取数据,如下图所示。
- 写 N 个内存 queue,具有相同 key 的数据都分发到同一个内存 queue;
- 然后对于 N 个线程,每个线程分别消费一个内存 queue 即可,这样就能保证顺序性。




























还没有评论,来说两句吧...