Redis 5中数据类型和使用场景
一、Redis基本介绍
Redis(REmote DIctionary Server)是用C语言开发的一个开源的高性能键值对(key-value)数据库。
特征:
1、数据间没有必然的关联关系
2、内部采用单线程机制进行工作
3、高性能。官方提供测试数据,50个并发执行100000次/s,写的速度是81000次/s。
4、多数据类型支持
- String
- list
- hash
- set
- sorted_set
String
1、常见的字符串操作
set key valueget keymset key1 value1 key2 value2 ...get key1 key2strlen key :返回key的value的值长度getrange key X Y :返回key对应value的一个子字符串,位置从X到Yappend key value :给key对应的value追加值,如果key不存在,相当于set一个新值# 设置数据具有生命周期setex key seconds valuepsetex key milliseconds value# 设置key和value,仅当key不存在时setnx key value
2、如果字符串的内容是数值(integer,在redis中,数值也是string)
incr key :在给定key的value上增加1;(常用于id);redis中的incr是一个原子操作,支持并发;如果key不存在,则相当于设置1;incrby key value :给定key的value上增加value值;相当于key=key.value+value;这也是一个原子操作;decr :在给定key的value上减少1;decrby key value :给定key的value上减少value值;
3、string最常见的使用场景
存储json类型对象
set user:1 {
id:1,name:xiaolong} 第一个user设置属性
set user:2 {
id:2,name:stef} 第二个user设置属性
计数器
incr count;
incr user:id
incr user:id incr 是原子操作,支持并发优酷视频点赞(为第100个视频点赞统计)
初 始 set vedio
 good:count 0
good:count 0
点 赞 incr vediogood:count
取消点赞 decr vediogood:count分布式锁
setnx key value :如果存在key,则设置失败;不存在key,设置成功;
List
1、redis的LIST结构(想象成java中的List)
- 是一个
双向链表结构,可以用来存储一组数据;从这个列表的前端和后端取数据效率非常高 - list中保存的数据都是String类型的,数据总容量是有限的
- list具有索引的概念,但是操作数据时常以队列的形式进行入队出队操作,或者以栈的形式进行入栈出栈操作
- 获取全部数据操作结束索引设置为 - 1
2、list的常用操作
# 插入RPUSH :在一个list最后添加一个元素RPUSH firends "stef"LPUSH :在一个list最前面添加一个元素LPUSH firends "stea"# 获取 出队 出栈LPOP :移除list中第一个元素,并返回这个元素==>LPOP friendsRPOP :移除list中最后一个元素,并返回这个元素==>RPOP friends# 阻塞获取BLPOPBRPOP# 删除lrem key count value 删除key中存储的指定count个数value# 裁剪listLTRIM key start stop :剪裁一个列表,剩下的内容从start到stop;LTRIM friends 0 3 =>只剩下前4个数据;#读取LRANGE key start stop :获取列表中的一部分数据,两个参数,第一个参数代表第一个获取元素的位置(0)开始,第二个值代表截止的元素位置,如果第二个参数为-1,截止到列表尾部==>LRANGE firends 0 -1LLEN key : 返回一个列表当前长度==>LLEND friendsLINDEX key index 获取index上的数据
3、使用场景
- 使用redis的list模拟队列、栈
- 消息队列:reids的链表结构,可以轻松实现阻塞队列,可以使用左进右出的命令组成来完成队列的设计。比如:数据的生产者可以通过Lpush命令从左边插入数据,多个数据消费者,可以使用BRpop命令阻塞的“抢”列表尾部的数据。
朋友圈点赞
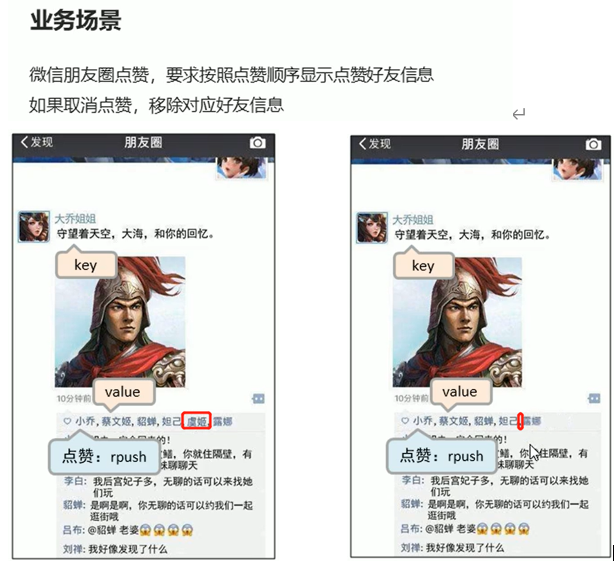
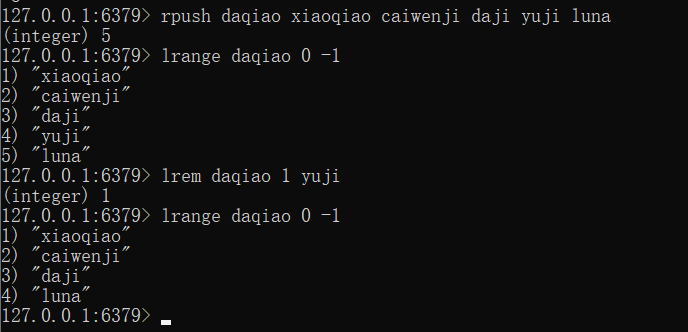
解决方案:
移除指定数据lrem key count value // count为移除的数量,value为移除哪个值
最新消息的展示
- twitter、新浪微博、腾讯微博中个人用于的关注列表需要按照用户的关注顺序进行展示,粉丝列表需要将最近关注的粉丝列在前面
- 新闻、资讯类网站如何将最新的新闻或资讯按照发生的时间顺序展示
- 企业运营过程中,系统将产生大量的运营数据,如何保障多台服务器操作日志的统一顺序输出?
解决方案
- 依赖list的数据具有顺序的特征对信息进行管理
- 使用队列模型解决多路信息汇总合并的问题
- 使用栈模型解决最新消息的问题
Set
1、SET结构和java中差不多,数据没有顺序,并且每一个值不能重复;与hash存储结构完全相同,仅存储key,不存储值(nil),并且key不允许重复

2、SET结构的常见操作:
# 添加、删除元素sadd key member1 [member2] :给set添加一个元素srem key member1 [member2] :从set中移除一个给定元素# 获取元素smembers key :返回指定set内所有的元素,以一个list形式返回scard key :返回set的元素个数# 随机获取srandmember key [count] :返回指定set中随机的count个元素 ==> srandmember friends 3 //随机推荐3个用户(典型场景,抽奖)spop key :随机获取集合中的某个数据并将该数据移出集合# 判断是否在集合中sismember key member :判断给定的一个元素是否在set中,如果存在,返回1,如果不存在,返回0# 求两个集合的交、并、差集sinter key1 [key2] :获取多个key对应的set之间的交集sunion key1 [key2] :综合多个set的内容,并返回一个list的列表,包含综合后的所有元素;sdiff key1 [key2] :求key1集合想较于key2集合的差集# 求两个集合的交、并、差集并存储到指定集合中sinterstore destination key1 [key2] :获取多个key对应的set之间的交集,并保存为新的key值;目标也是一个set;sunionstore destination key1 [key2] :获取多个key对应的set之间的并集,并保存为新的key值;目标也是一个set;sdiffstore destination key1 [key2] :获取多个key对应的set之间的并集,并保存为新的key值;目标也是一个set;# 将指定数据从原始集合中移动到目标集合中smove source destination memberSINTER groupfriends friends:user:1000 friends:user:1001 friends:user:1002 =>获取三个用户共同的好友列表并保存为组好友列表;
3、set的使用场景:
①、去重;
②、抽奖;
准备一个抽奖池: sadd luckdraws 1 2 3 4 5 6 7 8 9 10 11 12 13抽3个三等奖: srandmember luckdraws 3srem luckdraws 11 1 10抽2个二等奖
③做set运算(共同好友)
初始化好友圈
sadd user:1:friends ‘user:2’ ‘user:3’ ‘user:5’sadd user:2:friends ‘user:1’ ‘user:3’ ‘user:6’sadd user:3:friends ‘user:1’ ‘user:7’ ‘user:8’
把user:1的好友的好友集合做并集;
user:1 user:3 user:6 user:7 user:8
让这个并集和user:1的好友集合做差集;
user:1 user:6 user:7 user:8
从差集中去掉自己
user:6 user:7 user:8
随机选取推荐好友

Sorted_Set
1、redis提供了一个sorted set,每一个添加的值都有一个对应的分数,可以通过这个分数进行排序;sorted set中的排名是按照分组升序排列
2、Sortedset的常用操作:
# 添加数据zadd key score1 member1 [score2 member2]:添加一个带分数的元素,也可以同时添加多个:ZADD hackers 1940 “Alan Kay”ZADD hackers 1906 “Grace Hopper”ZADD hackers 1969 “Linus Torvalds”ZADD hackers 1940 “Alan Kay” 1906 “Grace Hopper” 1969 “Linus Torvalds”# 获取全部元素zrange key start stop [withscores]zrevrange key start stop [withscores]# 删除元素zrem key member [member ...]# 获取集合数量总量zcard keyzcount key min max# 获取数据对应的索引,索引从0开始zrank key memberzrevrank key member# score值获取与修改zscore key memberzincrby key increment member
3、sorted set的使用场景:sorted set算是redis中最有用的一种结构,非常适合用于做海量的数据的排行(比如一个巨型游戏的用户排名);sorted set中所有的方法都建议大去看一下;sorted set的速度非常快;
示例1,天梯排名:
1,添加初始排名和分数:
2,查询fat在当前ladder中的排名:
3,查询ladder中的前3名:
4,jian增加了20ladder score:

示例2:
票选广东十大杰出青年,各类综艺选秀海选投票
各类资源网站Top10
聊天室活跃度统计
游戏好友亲密度
Hash
1、hashes可以理解为一个map,这个map由一对一对的字段和值组成,所以,可以用hashes来保存一个对象:
2、hashes的常见操作:
hset:给一个hashes添加一个field和value;HSET user:1000 name “John Smith”HSET user:1000 email "john.smith@example.com"HSET user:1000 password “s3cret”hget可以得到一个hashes中的某一个属性的值:HGET user:1000 name 'John Smith'hgetall:一次性取出一个hashes中所有的field和value,使用list输出,一个field,一个value有序输出;HGETALL user:1000 =>1) “name”2) “John Smith”3) “email”4) "john.smith@example.com"5) “password”6) “s3cret”hmset :一次性的设置多个值(hashes multiple set)HMSET user:1001 name 'Mary Jones' password 'hidden' email 'mjones@example.com'hmget:一次性的得到多个字段值(hashes multiple get),以列表形式返回;HMGET user:1001 name email =>1)“Mary Jones”2)“mjones@example.com”hincrby:给hashes的一个field的value增加一个值(integer),这个增加操作是原子操作:HSET user:1000 visits 10HINCRBY user:1000 visits 1 => 11HINCRBY user:1000 visits 10 => 21hkeys:得到一个key的所有fields字段,以list返回:HKEYS user:1000 =>1)“name”2)“password”3)“email”hvals:得到一个key的所有value值hvals girl1) "3"2) "xiaohong"3) "female"hdel:删除hashes一个指定的filed;HDEL user:1000 visits# 存在时,设置失败hsetnx key field valuehsetnx girl sex man
3、使用场景
- 使用hash来保存一个对象更直观;(建议不使用hash来保存)
- 电商网站购物车设计及与实现

- 抢购

解决方案
(1)以商家id作为key
(2)将参与抢购的商品id作为field
(3)将参与抢购的商品个数作为对应的value
(4)抢购时使用峰值的方式 控制产品的数量
实际业务中还有超卖等实际问题,这里不做讨论



































还没有评论,来说两句吧...