Hbase -- 总结
文章目录
- 为什么使用Hbase
- hbase与mysql与NoSql的区别
- hbase结构
- HDFS
- 这玩意是什么
- HDFS的关键元素:
- HDFS运行原理
- 为什么要用分布式存储文件
- 什么是hbase
- Master
- Region Server
- Zookeeper
- Master的作用:
- RegionServer的作用:
- HRegion
- Store
- MemStore
- StoreFile
- HFile
- HLog
- LogFlusher
- LogRoller
- HLog的写入
- wal同步过程
- wal滚动
- wal失效
- wal删除
- 组件高可用
- Hbase读写流程
- 写操作流程 重要
- put数据的流程。
- 读操作流程
为什么使用Hbase
HBase是Apache Hadoop生态系统中可用的NoSQL数据存储之一。非关系数据库,它是用Java编写的开源,多维,分布式和可伸缩的NoSQL数据存储。HBase在HDFS(Hadoop分布式文件系统)之上运行,HBase通过提供对大型数据集的更快的读/写访问来实现高吞吐量和低延迟。因此,它是需要快速随机访问大量数据的应用程序的选择。
Mysql 存储的方式虽然是结构化的,但是对于大数据量进行存储的时候超过千万百万的数据,mysql就要进行分表存储分库存储,这是当下阶段可以解决的一种办法,但是当数据量过大那么我们需要一种大数据存储的方案,这时候可以考虑使用hbase,使用hbase的原因主要是它是需要快速随机访问大量数据的应用程序的选择。
当数据量越来越大,RDB数据库撑不住了,一般会组装读写分离策略,通过一个Master专门负责写操作,多个Slave负责读操作,服务器成本倍增。随着压力增加,Master撑不住了,这时就要分库了,把关联不大的数据分开部署,一些join查询不能用了,需要借助中间层。随着数据量的进一步增加,一个表的记录越来越大,查询就变得越来越慢,于是又得搞分表,比如按ID取模分成多个表以减少单个表的记录数。经历过这些事的人都知道过程是多么的折腾。采用HBase就简单了,只需要加机器即可,HBase会自动水平切分扩展,一般项目都会使用这两种,mysql 作为结构性弱数据存储,而提交量比较大的数据放在hbase存储。还有一种策略是,先把数据放到mysql,然后同步到hbase,mysql过一段时间清除一次。对于时间范围不在范围内的通过mysql查找,对于全量数据需要从hbase查找,这样既保证了数据存储,也提供了数据分析能力
hbase与mysql与NoSql的区别
- MySQL:关系型数据库,主要面向OLTP,联机事务处理,支持事务,支持二级索引,支持sql,支持主从、Group
- HBase:基于HDFS,支持海量数据读写(尤其是写),支持上亿行、上百万列的,面向列的分布式
- NoSql数据库。天然分布式,主从架构,不支持事务,不支持二级索引,不支持sql
比较
- MySQL采用行存储MySQL行存储的方式比较适合OLTP业务。
- HBase是面向列的NoSql数据库列存储的方式比较适合OLAP业务,而HBase采用了列族的方式平衡了OLTP和OLAP,支持水平扩展,如果数据量比较大、对性能要求没有那么高,hbase是不错的选择
- mysql 存储使用的是行存储, hbase 列存储
- mysql 扩展是单机,hbase是水平扩展加机器
- mysql支持事务,hbase 反之
- mysql 支持全文索引, hbase 不支持
OLTP 系统强调数据库内存效率,强调内存各种指标的命令率,强调绑定变量,强调并发操作;
OLAP 系统则强调数据分析,强调SQL执行市场,强调磁盘I/O,强调分区等。
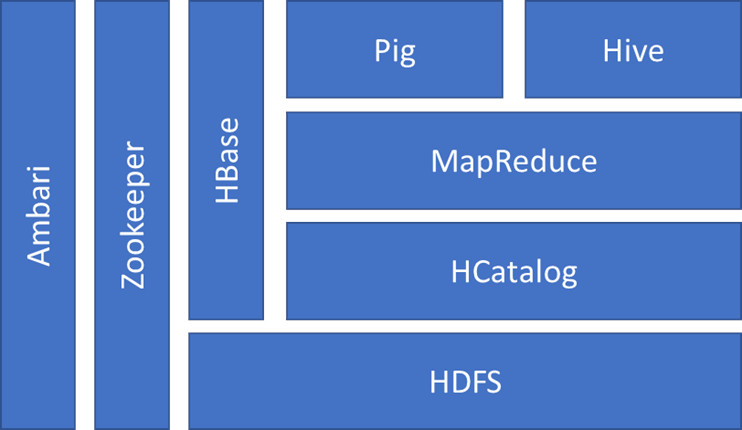
hbase结构
要聊Hbase 可以看到底层是hdfs做为支撑
所以需要先对hdfs 聊一下
HDFS
这玩意是什么
HDFS是分布式文件系统的其中一种
HDFS的关键元素:
- Block:将一个文件进行分块,通过配置参数( dfs.blocksize)来设置,hadoop2.x版本中是128M,老版本中是64M。
- NameNode:保存整个文件系统的目录信息、文件信息及分块信息,这是由唯一一台主机专门保存,当然这台主机如果出错,NameNode就失效了。在 Hadoop2.* 开始支持 activity-standy 模式——如果主 NameNode 失效,启动备用主机运行NameNode。
- DataNode:分布在廉价的计算机上,用于存储Block块文件。
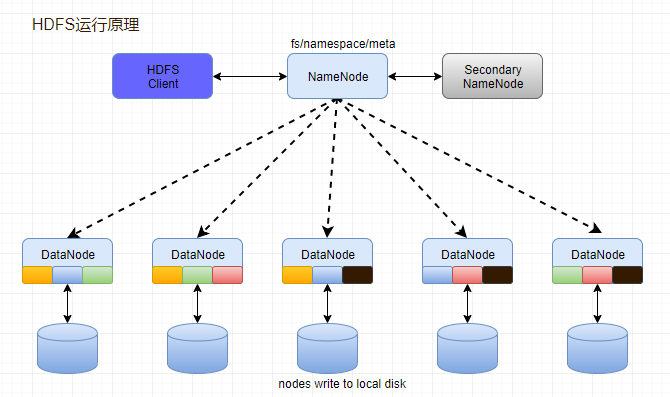
HDFS运行原理
- NameNode和DataNode节点初始化完成后,采用RPC进行信息交换,采用的机制是心跳机制,即DataNode节点定时向NameNode反馈状态信息,反馈信息如:是否正常、磁盘空间大小、资源消耗情况等信息,以确保NameNode知道DataNode的情况;
- NameNode会将子节点的相关元数据信息缓存在内存中,对于文件与Block块的信息会通过fsImage和edits文件方式持久化在磁盘上,以确保NameNode知道文件各个块的相关信息;
- NameNode负责存储fsImage和edits元数据信息,但fsImage和edits元数据文件需要定期进行合并,这时则由SecondNameNode进程对fsImage和edits文件进行定期合并,合并好的文件再交给NameNode存储。
为什么要用分布式存储文件
当数据集超过了一个独立的物理计算机存储怎么办
- 扩容
- 分开存储在多个机器
扩容只能解决暂时的问题,更高效和持久化,只能分开存储在多台机器,所以需要使用分布式存储文件
既然存储在多台机器,如何把文件找到,分片存储依据什么分片规则,如何保证各个机器都是ok的,同时如果一台机器挂了,数据怎么办。这些都需要一些方案;
什么是hbase
Hbase是一个分布式的、面向列的开源数据库,它不同于一般的关系数据库,是一个适合于非结构化数据存储的数据库。另一个不同的是Hbase基于列的而不是基于行的模式。Hbase使用和 BigTable非常相同的数据模型。用户存储数据行在一个表里。一个数据行拥有一个可选择的键和任意数量的列,一个或多个列组成一个ColumnFamily,一个Fmaily下的列位于一个HFile中,易于缓存数据。表是疏松的存储的,因此用户可以给行定义各种不同的列。在Hbase中数据按主键排序,同时表按主键划分为多个Region。
值得说的是hbase的null 不占用空间
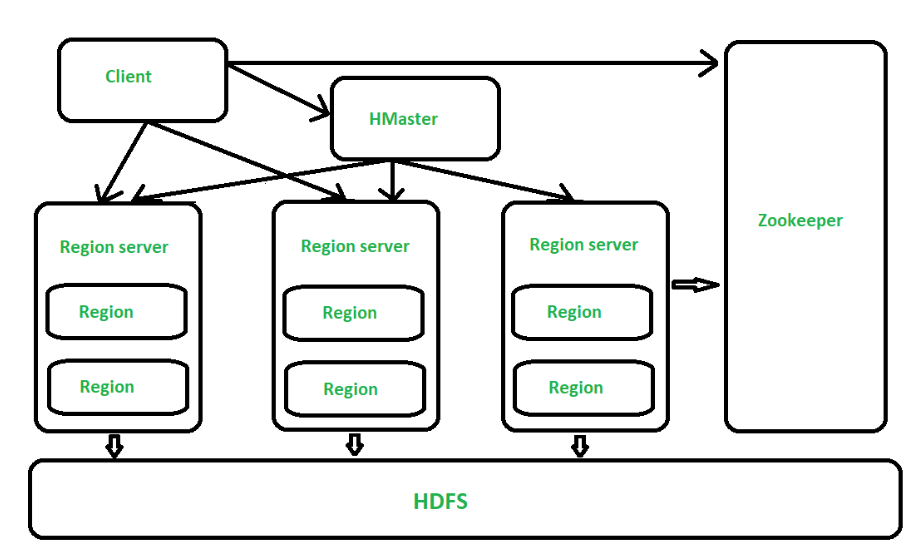
在分布式的生产环境中,Hbase 需要运行在 HDFS 之上,以 HDFS 作为其基础的存储设施。Hbase 上层提供了访问的数据的 Java API 层,供应用访问存储在 Hbase 的数据。在 Hbase 的集群中主要由 Master 和 Region Server 组成,以及 Zookeeper。
既然聊到了master和Region Server 可以聊一下区别
Master
Hbase Master用于协调多个Region Server,侦测各个RegionServer之间的状态,并平衡RegionServer之间的负载。HbaseMaster还有一个职责就是负责分配Region给RegionServer。Hbase允许多个Master节点共存,但是这需要Zookeeper的帮助。不过当多个Master节点共存时,只有一个Master是提供服务的,其他的Master节点处于待命的状态。当正在工作的Master节点宕机时,其他的Master则会接管Hbase的集群。
Region Server
对于一个RegionServer而言,其包括了多个Region。RegionServer的作用只是管理表格,以及实现读写操作。Client直接连接RegionServer,并通信获取Hbase中的数据。对于Region而言,则是真实存放Hbase数据的地方,也就说Region是Hbase可用性和分布式的基本单位。如果当一个表格很大,并由多个CF组成时,那么表的数据将存放在多个Region之间,并且在每个Region中会关联多个存储的单元(Store)。
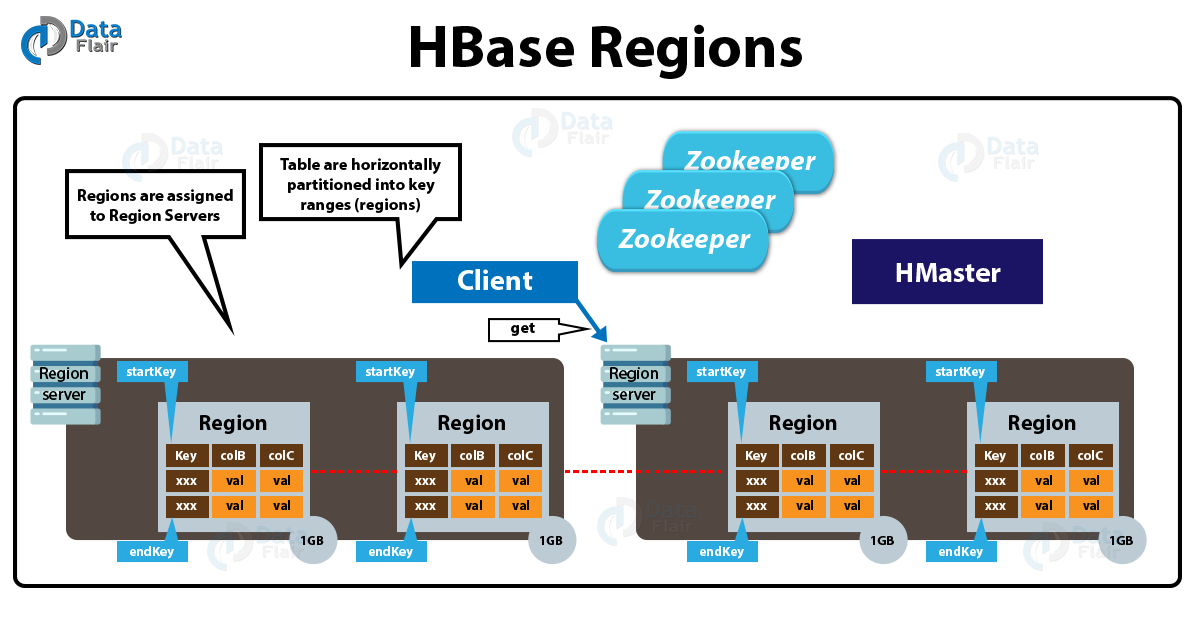
Zookeeper
对于 Hbase 而言,Zookeeper的作用是至关重要的。首先Zookeeper是作为Hbase Master的HA解决方案。也就是说,是Zookeeper保证了至少有一个Hbase Master 处于运行状态。并且Zookeeper负责Region和Region Server的注册。其实Zookeeper发展到目前为止,已经成为了分布式大数据框架中容错性的标准框架。不光是Hbase,几乎所有的分布式大数据相关的开源框架,都依赖于Zookeeper实现HA。
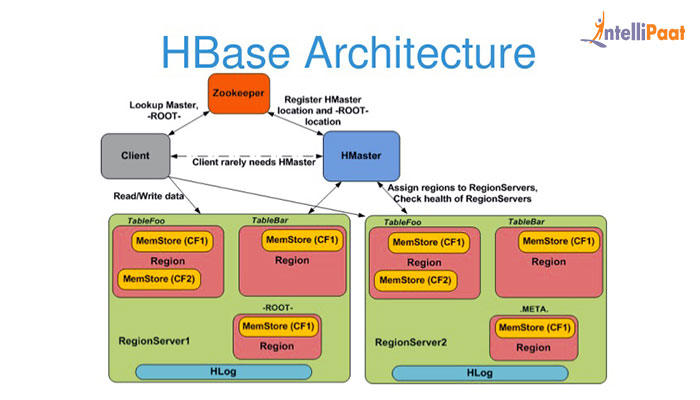
Hbase中的每张表都通过键按照一定的范围被分割成多个子表(HRegion),默认一个HRegion超过256M就要被分割成两个,这个过程由HRegionServer管理,而HRegion的分配由HMaster管理。
Master的作用:
- 为RegionServer分配HRegion
- 负责RegionServer的负载均衡
- 发现失效的RegionServer并重新分配
- HDFS上的垃圾文件回收
- 处理Schema更新请求
RegionServer的作用:
维护Master分配给它的Region,处理对这些Region的IO请求
负责切分正在运行过程中变得过大的Region ,大于256数据切分
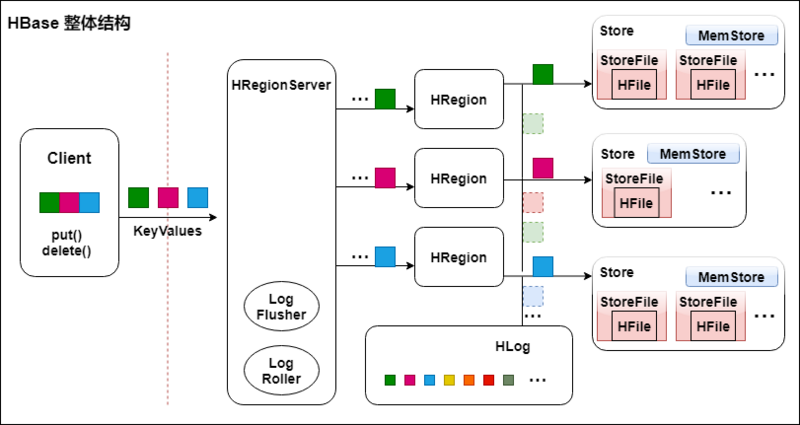
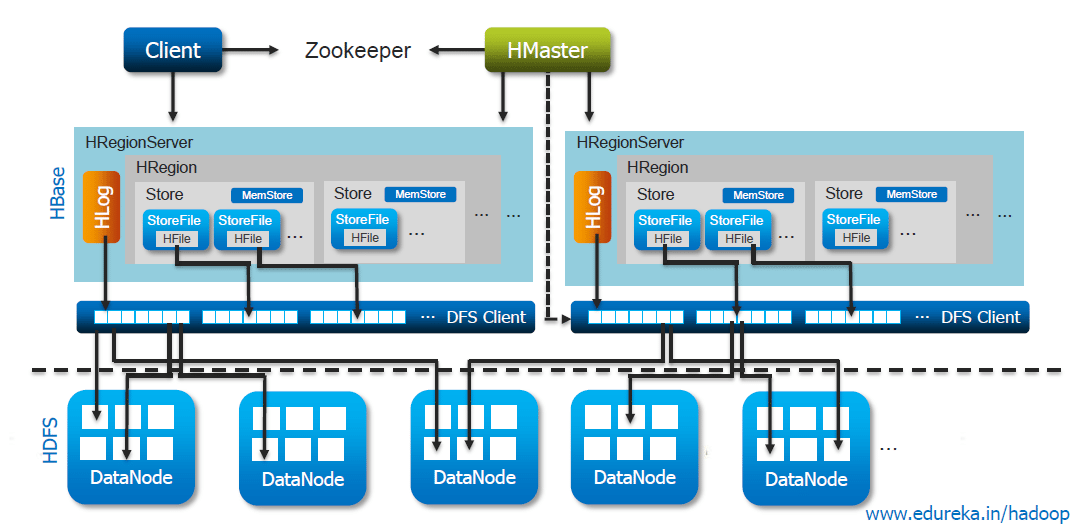
Client访问Hbase上的数据并不需要HMaster参与,寻址访问ZooKeeper和HRegionServer,数据读写访问HRegionServer,HMaster仅仅维护Table和Region的元数据信息,Table的元数据信息保存在ZooKeeper上,负载很低。HRegionServer存取一个子表时,会创建一个HRegion对象,然后对表的每个列簇创建一个Store对象,每个Store都会有一个MemStore和0或多个StoreFile与之对应,每个StoreFile都会对应一个HFile,HFile就是实际的存储文件。因此,一个HRegion有多少列簇就有多少个Store。
一个HRegionServer会有多个HRegion和一个HLog

HRegion
Table在行的方向上分割为多个HRegion,HRegion是Hbase中分布式存储和负载均衡的最小单元,即不同的HRegion可以分别在不同的HRegionServer上,但同一个HRegion是不会拆分到多个HRegionServer上的。HRegion按大小分割,每个表一般只有一个HRegion,随着数据不断插入表,HRegion不断增大,当HRegion的某个列簇达到一个阀值(默认256M)时就会分成两个新的HRegion。
HRegion定位
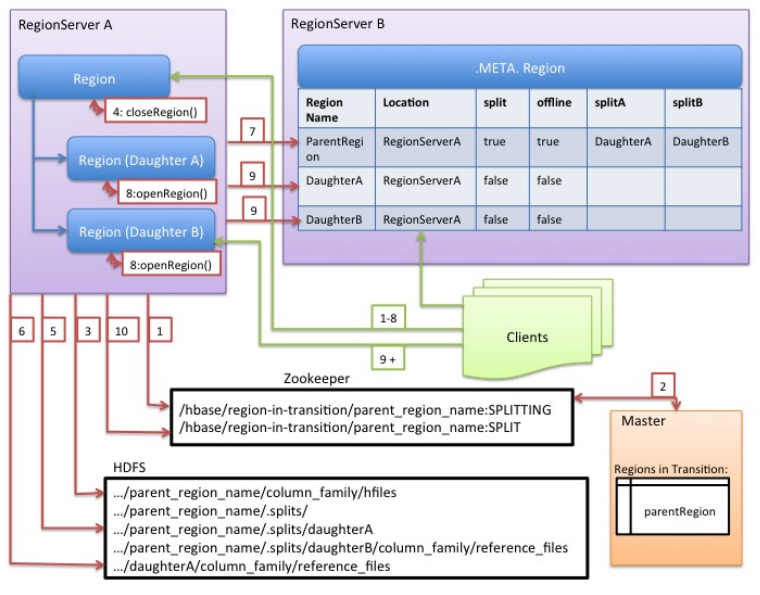
HRegion被分配给哪个HRegionServer是完全动态的,所以需要机制来定位HRegion具体在哪个HRegionServer,Hbase使用三层结构来定位HRegion:
- 1、通过zk里的文件/Hbase/rs得到-ROOT-表的位置。-ROOT-表只有一个region。
- 2、通过-ROOT-表查找.META.表的第一个表中相应的HRegion位置。其实-ROOT-表是.META.表的第一个region;.META.表中的每一个Region在-ROOT-表中都是一行记录。
- 3、通过.META.表找到所要的用户表HRegion的位置。用户表的每个HRegion在.META.表中都是一行记录。-ROOT-表永远不会被分隔为多个HRegion,保证了最多需要三次跳转,就能定位到任意的region。Client会将查询的位置信息保存缓存起来,缓存不会主动失效,因此如果Client上的缓存全部失效,则需要进行6次网络来回,才能定位到正确的HRegion,其中三次用来发现缓存失效,另外三次用来获取位置信息。
Store
每一个HRegion由一个或多个Store组成,至少是一个Store,Hbase会把一起访问的数据放在一个Store里面,即为每个ColumnFamily建一个Store,如果有几个ColumnFamily,也就有几个Store。一个Store由一个MemStore和0或者多个StoreFile组成。 Hbase以Store的大小来判断是否需要切分HRegion。

MemStore
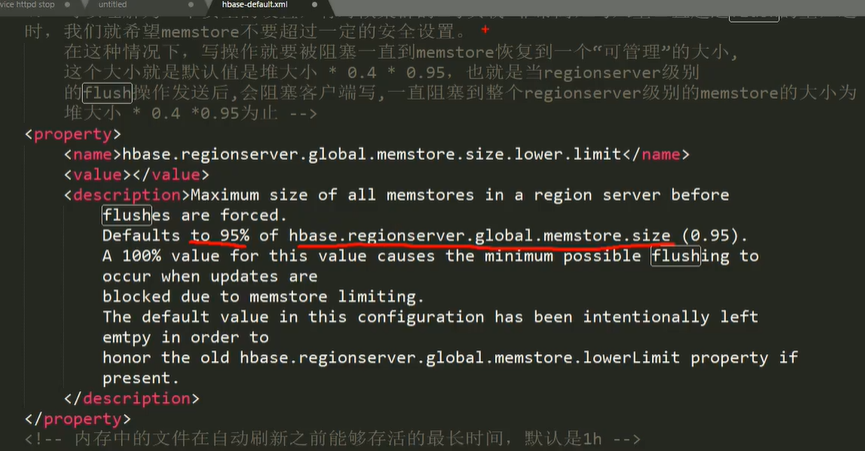
MemStore 是放在内存里的,保存修改的数据即keyValues。当MemStore的大小达到一个阀值(默认64MB)时,MemStore会被Flush到文件,即生成一个快照。目前Hbase会有一个线程来负责MemStore的Flush操作。

参考博客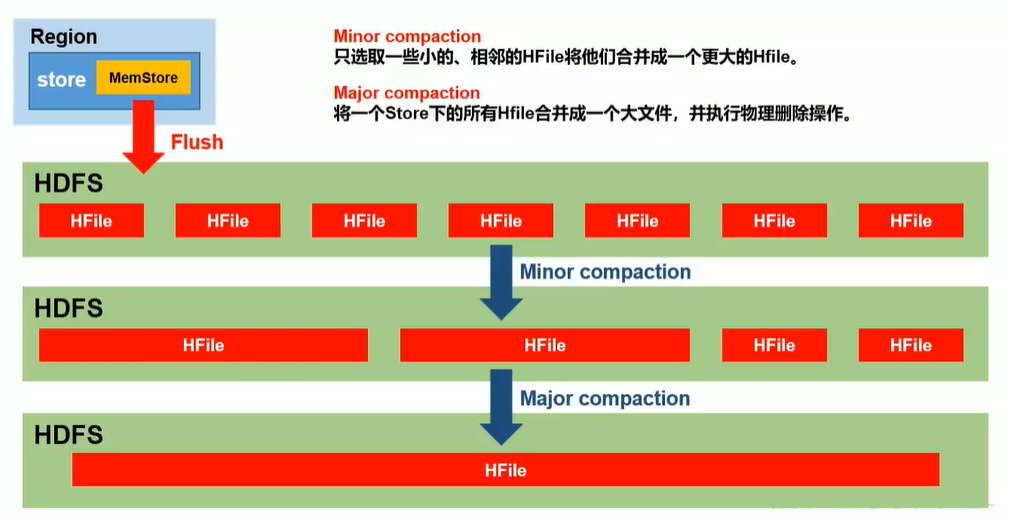

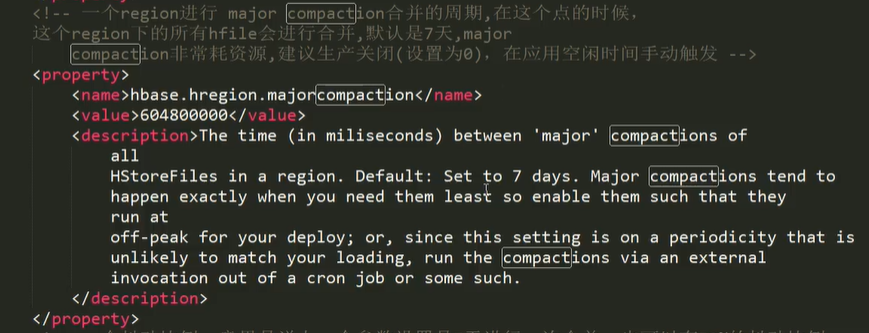
合并大型压缩需要大量时间,一般会设置为0避免占用太大性能
StoreFile
MemStore内存中的数据写到文件后就是StoreFile,StoreFile底层是以HFile的格式保存。
HFile
Hbase中KeyValue数据的存储格式,是Hadoop的二进制格式文件。 首先HFile文件是不定长的,长度固定的只有其中的两块:Trailer和FileInfo。
Trailer中有指针指向其他数据块的起始点,FileInfo记录了文件的一些meta信息。Data Block是Hbase IO的基本单元,为了提高效率,
HRegionServer中有基于LRU的Block Cache机制。每个Data块的大小可以在创建一个Table的时候通过参数指定(默认块大小64KB),大号的Block有利于顺序Scan,小号的Block利于随机查询。每个Data块除了开头的Magic以外就是一个个KeyValue对拼接而成,Magic内容就是一些随机数字,目的是防止数据损坏,结构如下。
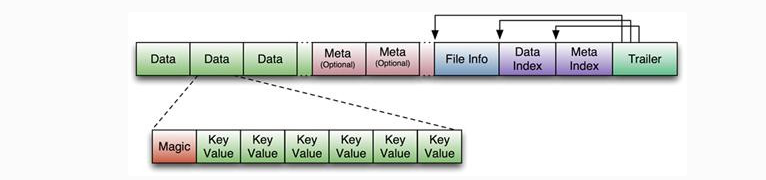
Data Block段用来保存表中的数据,这部分可以被压缩。 Meta Block段(可选的)用来保存用户自定义的kv段,可以被压缩。 FileInfo段用来保存HFile的元信息,不能被压缩,用户也可以在这一部分添加自己的元信息。 Data Block Index段(可选的)用来保存Meta Blcok的索引。 Trailer这一段是定长的。保存了每一段的偏移量,读取一个HFile时,会首先读取Trailer,Trailer保存了每个段的起始位置(段的Magic Number用来做安全check),然后,DataBlock Index会被读取到内存中,这样,当检索某个key时,不需要扫描整个HFile,而只需从内存中找到key所在的block,通过一次磁盘io将整个 block读取到内存中,再找到需要的key。DataBlock Index采用LRU机制淘汰。 HFile的Data Block,Meta Block通常采用压缩方式存储,压缩之后可以大大减少网络IO和磁盘IO,随之而来的开销当然是需要花费cpu进行压缩和解压缩。(备注: DataBlock Index的缺陷。 a) 占用过多内存 b) 启动加载时间缓慢)
HLog
HLog(WAL log):WAL意为write ahead log,用来做灾难恢复使用,HLog记录数据的所有变更,一旦region server 宕机,就可以从log中进行恢复。
LogFlusher
定期的将缓存中信息写入到日志文件中
LogRoller
对日志文件进行管理维护
WAL(Write-Ahead Logging)是数据库系统中保障原子性和持久性的技术,通过使用WAL可以将数据的随机写入变为顺序写入,可以提高数据写入的性能。在Hbase中写入数据时,会将数据写入内存同时写wal日志,为防止日志丢失,日志是写在hdfs上
默认是每个RegionServer有1个WAL,在Hbase1.0开始支持多个WALHBASE-5699,这样可以提高写入的吞吐量。配置参数为Hbase.wal.provider=multiwal支持的值还有defaultProvider和filesystem(这2个是同样的实现)。
WAL的持久化的级别有如下几种:
- SKIP_WAL:不写wal日志,这种可以较大提高写入的性能,但是会存在数据丢失的危险,只有在大批量写入的时候才使用(出错了可以重新运行),其他情况不建议使用。
- ASYNC_WAL:异步写入
- SYNC_WAL:同步写入wal日志文件,保证数据写入了DataNode节点。
- FSYNC_WAL: 目前不支持了,表现是与SYNC_WAL是一致的
- USE_DEFAULT: 如果没有指定持久化级别,则默认为USE_DEFAULT, 这个为使用Hbase全局默认级别(SYNC_WAL)
wal写入
先看看wal写入中的几个主要的类
- WALKey:wal日志的key,包括regionName:日志所属的region
tablename:日志所属的表,writeTime:日志写入时间,clusterIds:cluster的id,在数据复制的时候会用到。 - WALEdit:在Hbase的事务日志中记录一系列的修改的一条事务日志。另外WALEdit实现了Writable接口,可用于序列化处理。
- FSHLog: WAL的实现类,负责将数据写入文件系统
在每个wal的写入这里使用的是多生产者单消费者的模式,这里使用到了disruptor框架,将WALKey和WALEdit信息封装为FSWALEntry,然后通过RingBufferTruck放入RingBuffer中。接下来看hlog的写入流程,分为以下3步:
- 日志写入缓存:由rpcHandler将日志信息写入缓存ringBuffer.
- 缓存数据写入文件系统:每个FSHLog有一个线程负责将数据写入文件系统(HDFS)
- 数据同步:如果操作的持久化级别为(SYNC_WAL或者USE_DEFAULT 则需进行数据同步处理
下面来详细说明一下各类线程是如何配合来实现这几步操作的,
rpcHandler线程负责将日志信息(FSWALEntry)写入缓存RingBbuffer,在操作日志写完后,rpcHandler会调用wal的sync方法,进行数据同步,其实际处理为写入一个SyncFuture到RingBuffer,然后blocking一直到syncFuture处理完成。
wal线程从缓存RingBuffer中取数据,如果为日志(FSWALEntry)就调用Writer将数据写入文件系统,如果为SyncFuture,则由专门的同步线程来进行同步处理。
整体处理流程图如下:
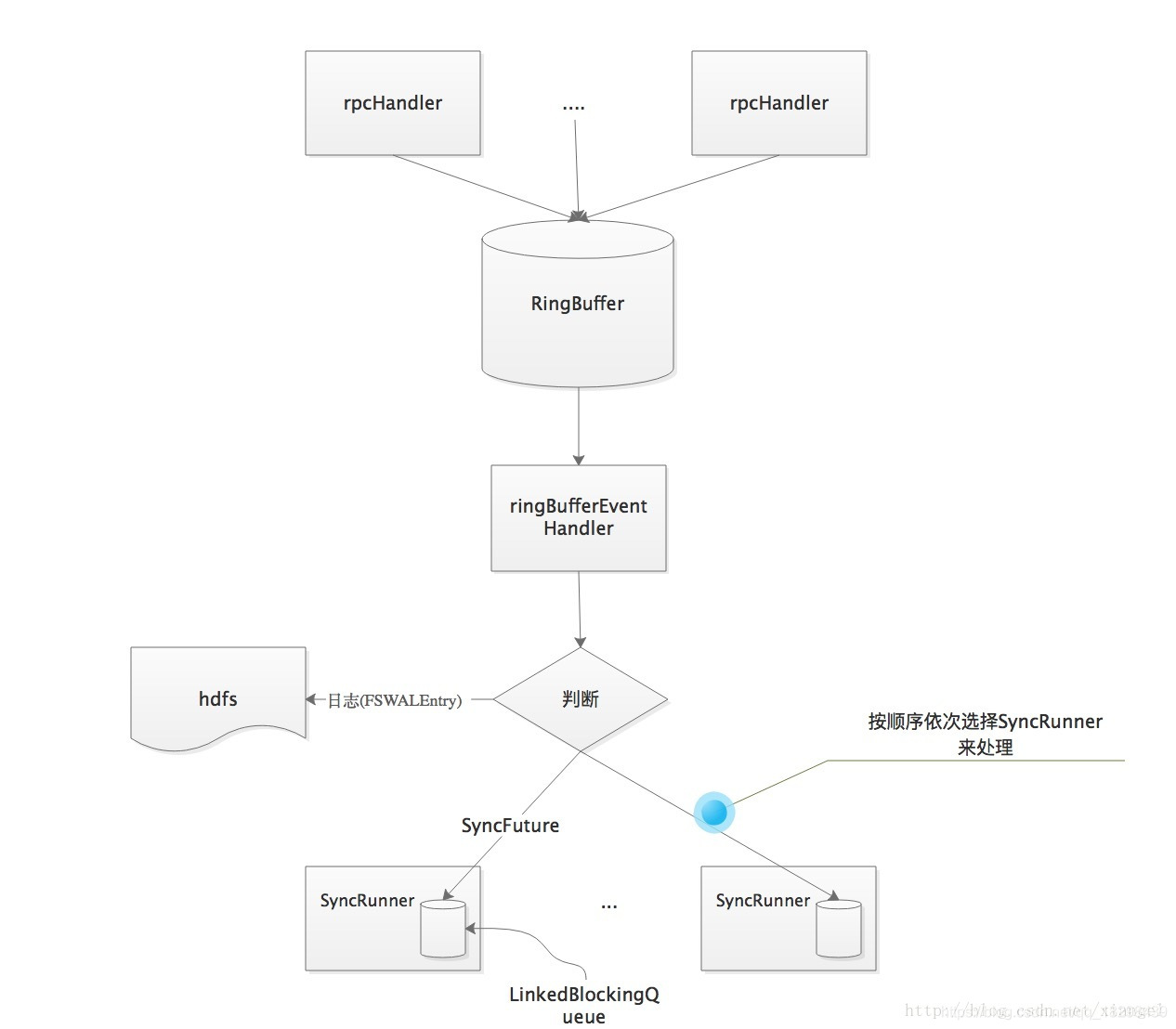
HLog的写入
wal写入文件系统是通过Writer来写入的,其实际类为ProtobufLogWriter,使用的是Protobuf的格式持久化处理。使用Protobuf格式有如下优势:
- 性能较高
- 结构更加紧凑,节省空间
- 方便扩展以及支持其他语言,通过其他语言来解析日志。
= 写入的日志中是按WALKey和WALEdit来依次存储的(具体内容见前面WALKey和WALEdit类的说明),另外还将WALKey和WALEdit分别进行了压缩处理。
wal同步过程
每个wal中有一个RingBufferEventHandler对象,其中用数组管理着多个SyncRunner线程(由参数Hbase.regionserver.hlog.syncer.count配置,默认5)来进行同步处理,每个SyncRunner对象里面有一个LinkedBlockingQueue(syncFutures,大小为参数{Hbase.regionserver.handler.count默认值200}*3
另外这里的SyncFuture是每个rpcHandler线程拥有一个,由wal中的private final Map
这里在处理ringBuffer中的syncFuture时,不是每有一个就提交到syncRunner处理,而是按批来处理的,这里的批分2种情况:
从ringBuffer中取到的一批数据(为提高效率,在disruptor框架中是按批从ringBuffer中取数据的,具体的请看disruptor的相关文档),如果这批数据中的syncFuture个数<{Hbase.regionserver.handler.count默认值200},则按一批处理
如果这一批数据中的syncFuture个数>={Hbase.regionserver.handler.count默认值200}个数,则按{Hbase.regionserver.handler.count默认值200}分批处理。
如果达到了批大小,就从syncRunner数组中顺序选择下一个SyncRunner,将这批数据插入该SyncRunner的BlockingQueue中。最后由SyncRunner线程进行hdfs文件同步处理。为保证数据的不丢失,rpc请求需要保证wal日志写入成功后才能返回,这里Hbase做了一系列的优化处理的操作。
wal滚动
通过wal日志切换,这样可以避免产生单独的过大的wal日志文件,这样可以方便后续的日志清理(可以将过期日志文件直接删除)另外如果需要使用日志进行恢复时,也可以同时解析多个小的日志文件,缩短恢复所需时间。
wal触发切换的场景有如下几种:
SyncRunner线程在处理日志同步后,如果有异常发生,就会调用requestLogRoll发起日志滚动请求
SyncRunner线程在处理日志同步后, 检查当前在写的wal的日志大小是否超过配置{Hbase.regionserver.hlog.blocksize默认为hdfs目录块大小}*{Hbase.regionserver.logroll.multiplier默认0.95},超过后同样调用requestLogRoll发起日志滚动请求
每个RegionServer有一个LogRoller线程会定期滚动日志,滚动周期由参数{Hbase.regionserver.logroll.period默认值1个小时}控制
这里前面2种场景调用requestLogRoll发起日志滚动请求,最终也是通过LogRoller来执行日志滚动的操作。
wal失效
当memstore中的数据刷新到hdfs后,那对应的wal日志就不需要了,FSHLog中有记录当前memstore中各region对应的最老的sequenceId,如果一个日志中的各个region的操作的最新的sequenceId均小于wal中记录的各个需刷新的region的最老sequenceId,说明该日志文件就不需要了,于是就会将该日志文件从./WALs目录移动到./oldWALs目录。这块是在前面日志滚动完成后调用cleanOldLogs来处理的。
wal删除
由于wal日志还会用于跨集群的同步处理,所以wal日志失效后并不会立即删除,而是移动到oldWALs目录。由HMaster中的LogCleaner这个Chore线程来负责wal日志的删除,在LogCleaner内部通过参数{Hbase.master.logcleaner.plugins}以插件的方式来筛选出可以删除的日志文件。目前配置的插件有ReplicationLogCleaner、SnapshotLogCleaner和TimeToLiveLogCleaner
TimeToLiveLogCleaner: 日志文件最后修改时间在配置参数{Hbase.master.logcleaner.ttl默认600秒}之前的可以删除
ReplicationLogCleaner:如果有跨集群数据同步的需求,通过该Cleaner来保证那些在同步中的日志不被删除
SnapshotLogCleaner: 被表的snapshot使用到了的wal不被删除
高可用
Write-Ahead-Log(WAL)保障数据高可用
我们理解下HLog的作用。Hbase中的HLog机制是WAL的一种实现,而WAL(一般翻译为预写日志)是事务机制中常见的一致性的实现方式。每个RegionServer中都会有一个HLog的实例,RegionServer会将更新操作(如 Put,Delete)先记录到 WAL(也就是HLo)中,然后将其写入到Store的MemStore,最终MemStore会将数据写入到持久化的HFile中(MemStore 到达配置的内存阀值)。这样就保证了Hbase的写的可靠性。如果没有 WAL,当RegionServer宕掉的时候,MemStore 还没有写入到HFile,或者StoreFile还没有保存,数据就会丢失。或许有的读者会担心HFile本身会不会丢失,这是由 HDFS 来保证的。在HDFS中的数据默认会有3份。因此这里并不考虑 HFile 本身的可靠性。
HFile由很多个数据块(Block)组成,并且有一个固定的结尾块。其中的数据块是由一个Header和多个Key-Value的键值对组成。在结尾的数据块中包含了数据相关的索引信息,系统也是通过结尾的索引信息找到HFile中的数据。
组件高可用
- Master容错:Zookeeper重新选择一个新的Master。如果无Master过程中,数据读取仍照常进行,但是,
region切分、负载均衡等无法进行; - RegionServer容错:
定时向Zookeeper汇报心跳,如果一旦时间内未出现心跳,Master将该RegionServer上的Region重新分配到其他RegionServer上,失效服务器上“预写”日志由主服务器进行分割并派送给新的RegionServer; - Zookeeper容错:Zookeeper是一个可靠地服务,一般配置3或5个Zookeeper实例。
Hbase读写流程
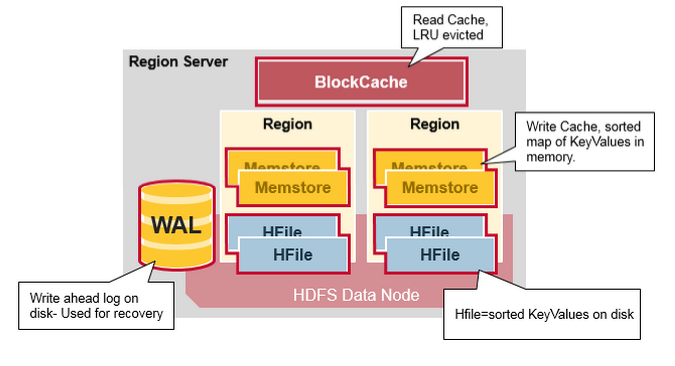
RegionServer数据存储关系图。上文提到,Hbase使用MemStore和StoreFile存储对表的更新。数据在更新时首先写入HLog和MemStore。MemStore中的数据是排序的,当MemStore累计到一定阈值时,就会创建一个新的MemStore,并且将老的MemStore添加到Flush队列,由单独的线程Flush到磁盘上,成为一个StoreFile。与此同时,系统会在Zookeeper中记录一个CheckPoint,表示这个时刻之前的数据变更已经持久化了。当系统出现意外时,可能导致MemStore中的数据丢失,此时使用HLog来恢复CheckPoint之后的数据。
StoreFile是只读的,一旦创建后就不可以再修改。因此Hbase的更新其实是不断追加的操作。这个可以看我上文写的hdfs存储流程。
当一个Store中的StoreFile达到一定阈值后,就会进行一次合并操作,默认是256m,将对同一个key的修改合并到一起,形成一个大的StoreFile。当StoreFile的大小达到一定阈值后,又会对 StoreFile进行切分操作,等分为两个StoreFile。
写操作流程 重要
- Client通过Zookeeper的调度,向RegionServer发出写数据请求,在Region中写数据。
- 数据被写入Region的MemStore,直到MemStore达到预设阈值。
- MemStore中的数据被Flush成一个StoreFile。
- 随着StoreFile文件的不断增多,当其数量增长到一定阈值后,触发Compact合并操作,将多个StoreFile合并成一个StoreFile,同时进行版本合并和数据删除。
- StoreFiles通过不断的Compact合并操作,逐步形成越来越大的StoreFile。
- 单个StoreFile大小超过一定阈值后,触发Split操作,把当前Region Split成2个新的Region。
父Region会下线,新Split出的2个子Region会被HMaster分配到相应的RegionServer上,使得原先1个Region的压力得以分流到2个Region上。
可以看出Hbase只有增添数据,所有的更新和删除操作都是在后续的Compact历程中举行的,使得用户的写操作只要进入内存就可以立刻返回,实现了Hbase I/O的高机能。
put数据的流程。
连接hbase
public static void main(String[] args) throws Exception {//创建配置对象Configuration conf = HBaseConfiguration.create();//配置zookeeper的连接对象,因为zookeeper存储了所有的hbase的储存信息,所以可以通过zookeeper操作hbaseconf.set("xxxxx","xxxxx");//获取hbase的连接对象Connection conn = ConnectionFactory.createConnection(conf);//获取用户对象,可获得一系列对表和名称空间进行操作的方法Admin admin = conn.getAdmin();//获取表名对象TableName[] tableNames = admin.listTableNames();for (TableName tableName : tableNames) {//可直接打印表名对象//System.out.println(tableName);//也可以通过表名对象将表名转换成字符串String tbname = tableName.getNameAsString();//通过表名对象获取它所在的名称空间名String namespace = tableName.getNamespaceAsString();System.out.println(namespace+"-"+tbname);}//获取表的对象,给他一个表名,返回一个该表的对象,可以对这个表内的数据进行操作Table tb = conn.getTable(TableName.valueOf("tb_user2"));tb.close();admin.close();conn.close();}
客户端
put在客户端的操作主要分为三个步骤,下面分别从三个步骤展开解释:
- 客户端缓存用户提交的put请求
get/delete/put/append/increment可用的函数都在客户端的HTable.java文件中。
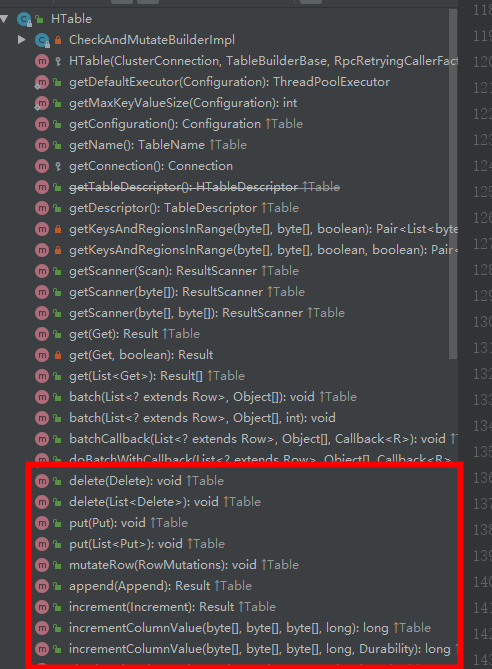
在HTable.java文件中有如下的两个变量:
- private RpcRetryingCallerFactory rpcCallerFactory;
- private RpcControllerFactory rpcControllerFactory;
protected AsyncProcess multiAp;
protected HTable(final ClusterConnection connection,
final TableBuilderBase builder,
final RpcRetryingCallerFactory rpcCallerFactory,
final RpcControllerFactory rpcControllerFactory,
final ExecutorService pool) {this.connection = Preconditions.checkNotNull(connection, "connection is null");this.configuration = connection.getConfiguration();this.connConfiguration = connection.getConnectionConfiguration();if (pool == null) {this.pool = getDefaultExecutor(this.configuration);this.cleanupPoolOnClose = true;} else {this.pool = pool;this.cleanupPoolOnClose = false;}if (rpcCallerFactory == null) {this.rpcCallerFactory = connection.getNewRpcRetryingCallerFactory(configuration);} else {this.rpcCallerFactory = rpcCallerFactory;}if (rpcControllerFactory == null) {this.rpcControllerFactory = RpcControllerFactory.instantiate(configuration);} else {this.rpcControllerFactory = rpcControllerFactory;}this.tableName = builder.tableName;this.operationTimeoutMs = builder.operationTimeout;this.rpcTimeoutMs = builder.rpcTimeout;this.readRpcTimeoutMs = builder.readRpcTimeout;this.writeRpcTimeoutMs = builder.writeRpcTimeout;this.scannerCaching = connConfiguration.getScannerCaching();this.scannerMaxResultSize = connConfiguration.getScannerMaxResultSize();// puts need to track errors globally due to how the APIs currently work.multiAp = this.connection.getAsyncProcess();this.locator = new HRegionLocator(tableName, connection);
}
package org.apache.hadoop.hbase.client;
TableBuilder getTableBuilder(TableName tableName, ExecutorService pool);
如上的几个变量分别定义了rpc调用的工厂和一个异步处理的进程
@Overridepublic void put(final Put put) throws IOException {// 校验参数validatePut(put);ClientServiceCallable<Void> callable =// 创建客户端服务调用回调new ClientServiceCallable<Void>(this.connection, getName(), put.getRow(),this.rpcControllerFactory.newController(), put.getPriority()) {@Overrideprotected Void rpcCall() throws Exception {MutateRequest request =// 调用请求转换RequestConverter.buildMutateRequest(getLocation().getRegionInfo().getRegionName(), put);// 请求doMutate(request);return null;}};// rpc调用 从这里可以看到 上文说的存储数据是通过rpc 客户端连接服务端的servicerpcCallerFactory.<Void> newCaller(this.writeRpcTimeoutMs).callWithRetries(callable,this.operationTimeoutMs);}/** * 为放置创建协议缓冲区MutateRequest * * @param regionName region 名称 * @param put put 参数 * @return a mutate request 请求透 * @throws IOException io异常 */public static MutateRequest buildMutateRequest( final byte[] regionName, final Put put) {// builder 构建MutateRequest.Builder builder = MutateRequest.newBuilder();RegionSpecifier region = buildRegionSpecifier( RegionSpecifierType.REGION_NAME, regionName);builder.setRegion(region);builder.setMutation(ProtobufUtil.toMutation(MutationType.PUT, put, MutationProto.newBuilder()));return builder.build();}/** * 将字节数组转换为协议缓冲区RegionSpecifier * * @param 区域说明符类型 * @param 区域说明符字节数组值 * @return 协议缓冲区RegionSpecifier */public static RegionSpecifier buildRegionSpecifier(final RegionSpecifierType type, final byte[] value) {RegionSpecifier.Builder regionBuilder = RegionSpecifier.newBuilder();regionBuilder.setValue(UnsafeByteOperations.unsafeWrap(value));regionBuilder.setType(type);return regionBuilder.build();}

读操作流程
- Client访问Zookeeper,查找-ROOT-表,获取.META.表信息。
- 从.META.表查找,获取存放目标数据的Region信息,从而找到对应的RegionServer。
- 通过RegionServer获取需要查找的数据。
- Regionserver的内存分为MemStore和BlockCache两部分,MemStore主要用于写数据,BlockCache主要用于读数据。读请求先到MemStore中查数据,查不到就到BlockCache中查,再查不到就会到StoreFile上读,并把读的结果放入BlockCache。
寻址过程:client–>Zookeeper–>-ROOT-表–>.META.表–>RegionServer–>Region–>client


























")


——LinearLayout、FrameLayout和AbsoulteLayout")
")



还没有评论,来说两句吧...