安装CenterPoint遇到的BUG
问题描述:
解决pip超时的问题
解决方案:
https://www.jianshu.com/p/8e042b7e91b6
更改镜像的源:https://www.runoob.com/w3cnote/pip-cn-mirror.html
问题描述:
在spconv中的build中编译的时候
– Found CUDNN: /usr/local/cuda-10.2/lib64/libcudnn.so
– Found cuDNN: v? (include: /usr/local/cuda-10.2/include, library: /usr/local/cuda-10.2/lib64/libcudnn.so)
解决方案:
找到自己创建的虚拟环境,
例如我的位置是
/home/philtell/anaconda3/envs/centerpoint/
然后进入到这个目录/home/philtell/anaconda3/envs/centerpoint/lib/python3.6/site-packages/torch/share/cmake
你会看到如下的截图
进入到下面的目录/home/philtell/anaconda3/envs/centerpoint/lib/python3.6/site-packages/torch/share/cmake/Caffe2/public
编辑cuda.cmake,找到第137行,进行替换
A quick and dirty edit of libtorch/share/cmake/Caffe2/public/cuda.cmake at line 148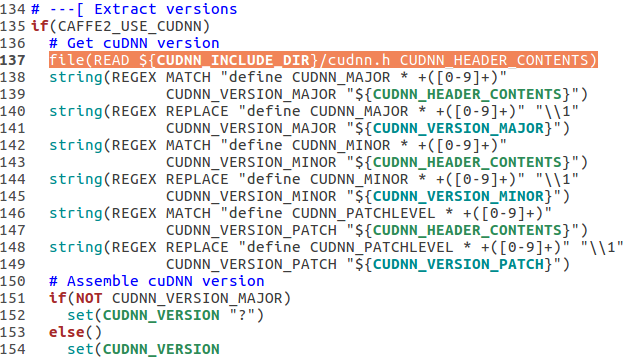
Replacing : file(READ ${CUDNN_INCLUDE_PATH}/cudnn.h CUDNN_HEADER_CONTENTS)
By : file(READ ${CUDNN_INCLUDE_PATH}/cudnn_version.h CUDNN_HEADER_CONTENTS)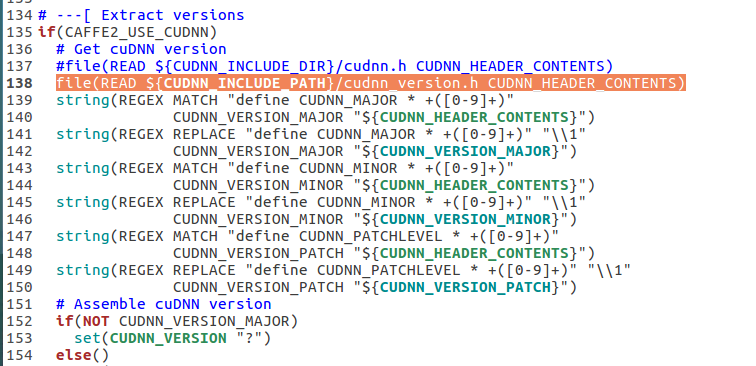
项目场景:
no matching function for call to ‘torch:
 :RegisterOperators
:RegisterOperators
解决方案:
Use torch::RegisterOperators() instead of torch::RegisterOperator(), it will be ok.
项目场景:
缺少fmt.h
fatal error: fmt/format.h: No such file or directory
解决方案:
https://github.com/fmtlib/fmt 安装之后进行编译
项目场景:
提示:这里简述项目相关背景:
例如:项目场景:示例:通过蓝牙芯片(HC-05)与手机 APP 通信,每隔 5s 传输一批传感器数据(不是很大)
问题描述:
提示:这里描述项目中遇到的问题: 例如:数据传输过程中数据不时出现丢失的情况,偶尔会丢失一部分数据 APP 中接收数据代码:
@Overridepublic void run() {bytes = mmInStream.read(buffer);mHandler.obtainMessage(READ_DATA, bytes, -1, buffer).sendToTarget();}
原因分析:
提示:这里填写问题的分析:
例如:Handler 发送消息有两种方式,分别是 Handler.obtainMessage()和 Handler.sendMessage(),其中 obtainMessage 方式当数据量过大时,由于 MessageQuene 大小也有限,所以当 message 处理不及时时,会造成先传的数据被覆盖,进而导致数据丢失。
解决方案:
提示:这里填写该问题的具体解决方案:
例如:新建一个 Message 对象,并将读取到的数据存入 Message,然后 mHandler.obtainMessage(READ_DATA, bytes, -1, buffer).sendToTarget();换成 mHandler.sendMessage()。
问题描述:
ERROR: No matching distribution found for det3d
解决方案:
pip install mmdet3d
问题描述:
cuda_runtime_api.h: No such file or directory
解决方案:
export CUDA_HOME=$HOME/tools/cuda-9.0 # change to your pathexport CUDA_TOOLKIT_ROOT_DIR=$CUDA_HOMEexport LD_LIBRARY_PATH="$CUDA_HOME/extras/CUPTI/lib64:$LD_LIBRARY_PATH"export LIBRARY_PATH=$CUDA_HOME/lib64:$LIBRARY_PATHexport LD_LIBRARY_PATH=$CUDA_HOME/lib64:$LD_LIBRARY_PATHexport CFLAGS="-I$CUDA_HOME/include $CFLAGS"
问题描述:
docker: Error response from daemon: could not select device driver “” with capabilities: [[gpu]].
解决方案:
wget https://nvidia.github.io/nvidia-docker/gpgkey --no-check-certificatesudo apt-key add gpgkeydistribution=$(. /etc/os-release;echo $ID$VERSION_ID)curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.listsudo apt-get updatesudo apt-get install -y nvidia-container-toolkitsudo apt-get install nvidia-container-runtimesystemctl restart docker
最后在我的Docker上安装上了CenterPoint. 耗时三天。。。 再给大家看一下我的系统环境:
再给大家看一下我的系统环境: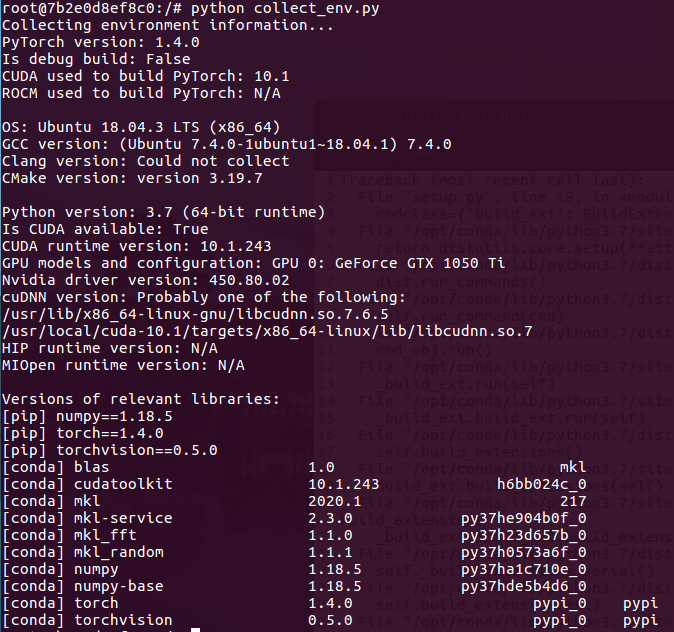
问题描述:
在对spconv进行编译,也就是执行CMake …的活动时。遇到如下错误
nvcc fatal : unknown option 'Wall'
解决方案:
在CMakeLists.txt 最下面加上如下两行
set_property(TARGET torch_cuda PROPERTY INTERFACE_COMPILE_OPTIONS "")set_property(TARGET torch_cpu PROPERTY INTERFACE_COMPILE_OPTIONS "")





























")
使用AKShare 做股票数据出来,替换现有每日数据,job相关任务,制作基础镜像使用python3.7-slim-stretch,akshare使用 0.9.65 版本")



还没有评论,来说两句吧...