java spi 与 dubbo spi
传统java spi
在java 中我们要动态通过配置文件制定实现类该如何实现呢?使用java spi机制即可,我们来看下面这个例子
public interface Robot {void sayHello();}
然后定义两个实现类。分别为 OptimusPrime 和 Bumblebee
public class OptimusPrime implements Robot {@Overridepublic void sayHello() {System.out.println("Hello, I am Optimus Prime.");}}public class Bumblebee implements Robot {@Overridepublic void sayHello() {System.out.println("Hello, I am Bumblebee.");}}
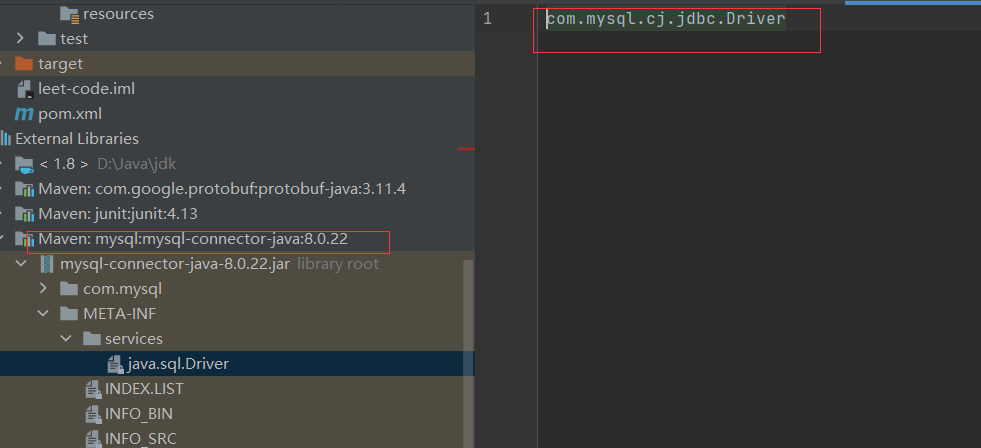
然后在META-INF/services文件夹下创建一个文件,名称为 Robot 的全限定名org.apache.dubbo.Robot。
文件内容为实现类的全限定的类名,如下:
org.apache.dubbo.OptimusPrimeorg.apache.dubbo.Bumblebee
文件名为接口Robot的 包路径+名称
文件内容则为接口实现类的 包路径+名称
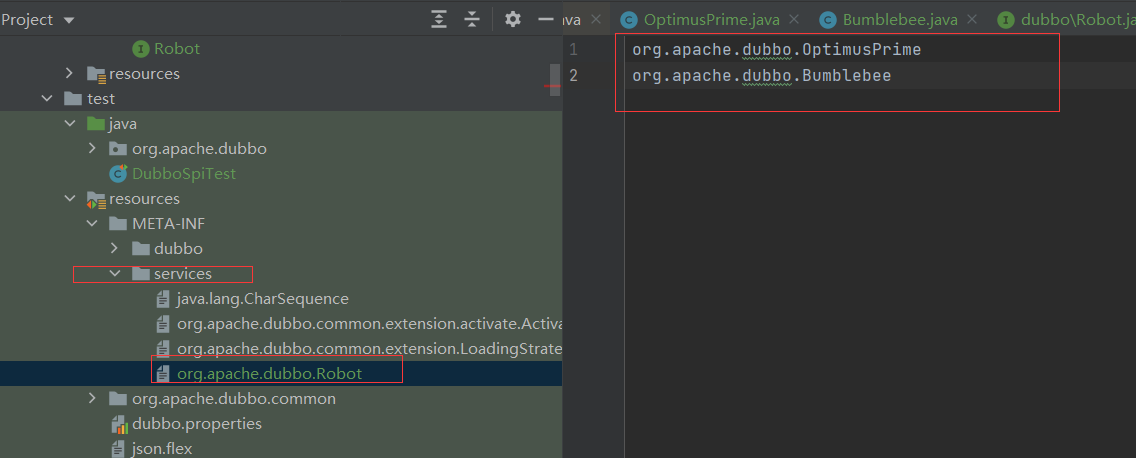
然后运行我们的测试用例
@Testpublic void javaSpiSayHello() {ServiceLoader<Robot> serviceLoader = ServiceLoader.load(Robot.class);System.out.println("Java SPI");serviceLoader.forEach(Robot::sayHello);}
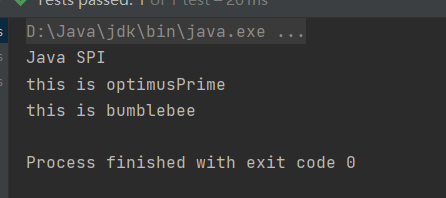
可以看到两个实现类被成功的加载,并输出了相应的内容。
java spi源码分析
可以看到核心类是ServiceLoader
类结构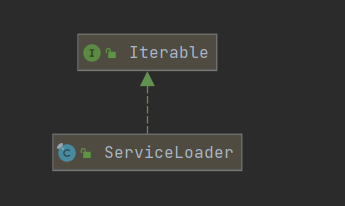
可以看到 ServiceLoader实现了 Iterable,所以可以循环遍历,因为一个接口有多个实现类,所以是一个集合。
而其中我们为什么我们要强制在META-INF/services这个路径创建文件呢。源码中我们看这个方法找到了答案
首先第一行代码中
ServiceLoader<Robot> serviceLoader = ServiceLoader.load(Robot.class);
我们深入到源码底层发现只是new 了一个LazyIterator
并没有初始化接口的实现,可见是懒加载,在遍历ServiceLoader才会加载实现类。LazyIterator也实现了Iterator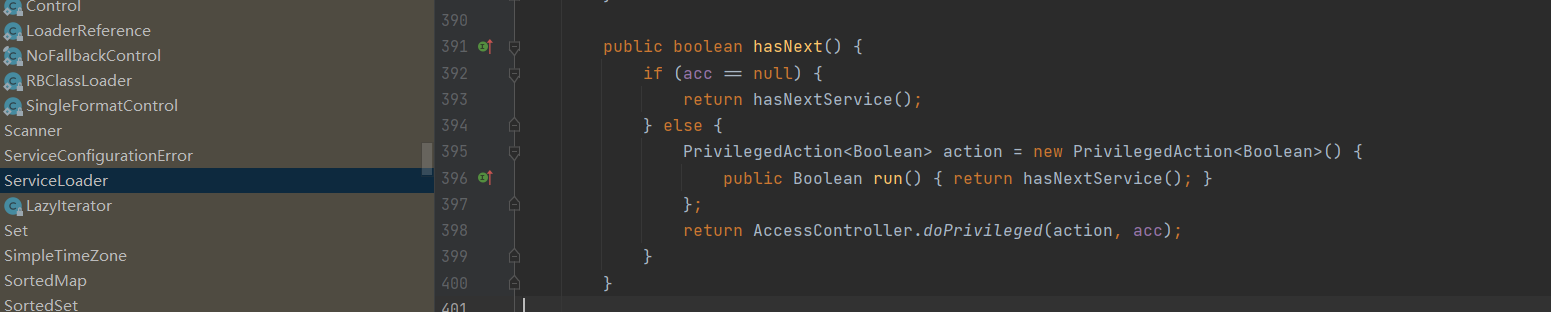
我们看看 hasNextService()方法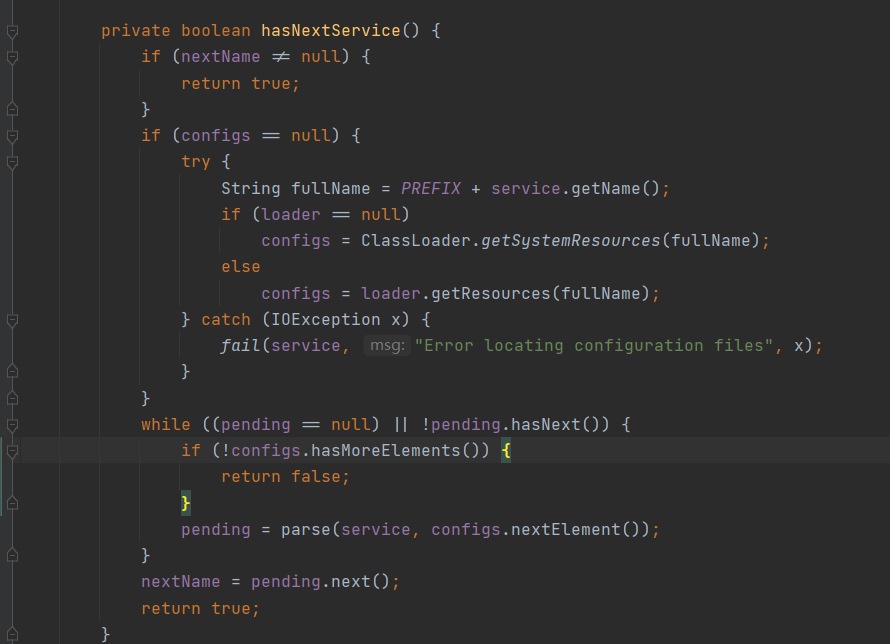
可以看到fullName = PREFIX + service.getName()
而PREFIX 是写死的常量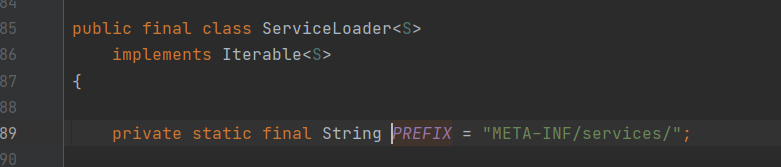
这里初始化了所有的实现类名称
而真正初始化实现类的方法则是在nextService()里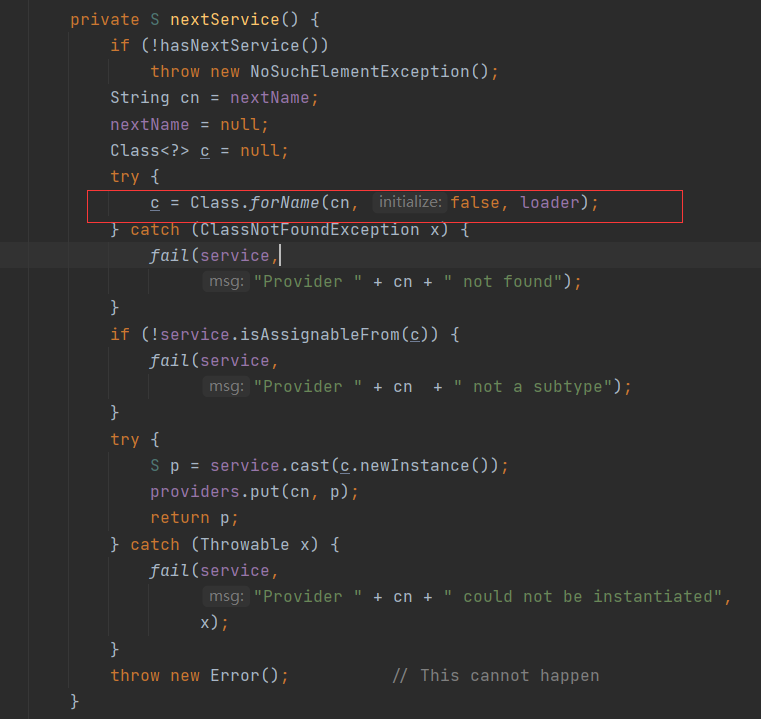
很多开源jar都使用了java 的spi比如日志,jdb驱动等
java spi 缺点
java spi缺点也很明显
- 多个并发多线程使用ServiceLoader类的实例是不安全的
- 每次获取元素需要遍历全部元素,不能按需加载。
- 加载不到实现类时抛出并不是真正原因的异常,错误很难定位
- 获取某个实现类的方式不够灵活,只能通过 Iterator 形式获取,不能根据某个参数来获取对应的实现类
基于以上缺点 dubbo重新实现了一套功能更强的 SPI 机制,Dubbo SPI 支持按需加载接口实现类,还增加了 IOC 和 AOP 等特性
dubbo SPI
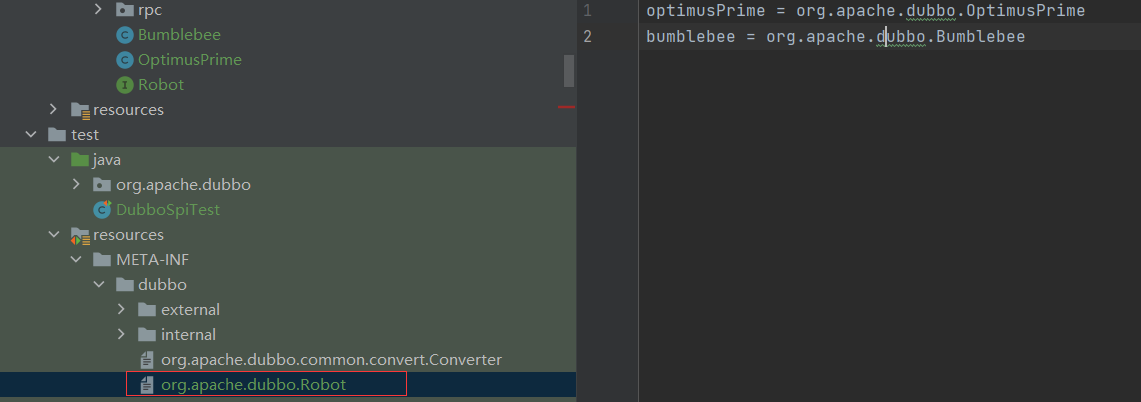
Dubbo SPI 的相关逻辑被封装在了 ExtensionLoader 类中,通过 ExtensionLoader,我们可以加载指定的实现类。Dubbo SPI 所需的配置文件需放置在 META-INF/dubbo 路径下,配置内容如下
optimusPrime = org.apache.spi.OptimusPrimebumblebee = org.apache.spi.Bumblebee
同时在Robot接口我们需要加入注解@SPI
测试使用
@Testpublic void sayHello() {ExtensionLoader<Robot> extensionLoader = ExtensionLoader.getExtensionLoader(Robot.class);Robot optimusPrime = extensionLoader.getExtension("optimusPrime");optimusPrime.sayHello();Robot bumblebee = extensionLoader.getExtension("bumblebee");bumblebee.sayHello();}
测试也是OK的
dubbo spi源码分析
源码版本:2.7.9
我们从 ExtensionLoader 的 getExtension 方法作为入口,对拓展类对象的获取过程进行详细的分析
public T getExtension(String name) {return getExtension(name, true);}public T getExtension(String name, boolean wrap) {if (StringUtils.isEmpty(name)) {throw new IllegalArgumentException("Extension name == null");}if ("true".equals(name)) {// 获取默认的拓展实现类return getDefaultExtension();}// Holder,顾名思义,用于持有目标对象final Holder<Object> holder = getOrCreateHolder(name);Object instance = holder.get();if (instance == null) {synchronized (holder) {instance = holder.get();if (instance == null) {// 创建拓展实例instance = createExtension(name, wrap);// 设置实例到 holder 中holder.set(instance);}}}return (T) instance;}
上面代码主要是基于一个双重检查的单例去获取对象。
下面我们看看instance = createExtension(name, wrap);的核心逻辑
@SuppressWarnings("unchecked")private T createExtension(String name, boolean wrap) {// 从配置文件中加载所有的拓展类,可得到“配置项名称”到“配置类”的映射关系表Class<?> clazz = getExtensionClasses().get(name);if (clazz == null) {throw findException(name);}try {T instance = (T) EXTENSION_INSTANCES.get(clazz);if (instance == null) {// 通过反射创建实例EXTENSION_INSTANCES.putIfAbsent(clazz, clazz.newInstance());instance = (T) EXTENSION_INSTANCES.get(clazz);}// 向实例中注入依赖injectExtension(instance);if (wrap) {List<Class<?>> wrapperClassesList = new ArrayList<>();if (cachedWrapperClasses != null) {wrapperClassesList.addAll(cachedWrapperClasses);wrapperClassesList.sort(WrapperComparator.COMPARATOR);Collections.reverse(wrapperClassesList);}if (CollectionUtils.isNotEmpty(wrapperClassesList)) {// 循环创建 Wrapper 实例for (Class<?> wrapperClass : wrapperClassesList) {Wrapper wrapper = wrapperClass.getAnnotation(Wrapper.class);if (wrapper == null|| (ArrayUtils.contains(wrapper.matches(), name) && !ArrayUtils.contains(wrapper.mismatches(), name))) {// 将当前 instance 作为参数传给 Wrapper 的构造方法,并通过反射创建 Wrapper 实例。// 然后向 Wrapper 实例中注入依赖,最后将 Wrapper 实例再次赋值给 instance 变量instance = injectExtension((T) wrapperClass.getConstructor(type).newInstance(instance));}}}}initExtension(instance);return instance;} catch (Throwable t) {throw new IllegalStateException("Extension instance (name: " + name + ", class: " +type + ") couldn't be instantiated: " + t.getMessage(), t);}}
创建扩展类的核心步骤如下:
- 通过 getExtensionClasses 获取所有的拓展类
- 通过反射创建拓展对象
- 向拓展对象中注入依赖(Dubbo IOC)
- 将拓展对象包裹在相应的 Wrapper 对象中(Dubbo AOP)
后续IOC和AOP源码由于篇幅关系就不在这里展开说明了,不过官网有详细说明,这里给出官网说明链接
dubbo官网关于duubo spi源码解析


































还没有评论,来说两句吧...