解决 ShardingSphere 第一次请求慢的喷血日子
学习起因:整合了 ShardingSphere 的项目第一次访问的时候很慢,第二次访问的时候速度就快了,然后老大让我去一探究竟,然后下面就是探索的血泪史。

通过 Arthas 生成火焰图,定位到慢在 ShardingSphere sql 解析,第一次请求使用 ANTLR 解析 SQL 耗时较长,而第二次请求由于缓存原因耗时很小
curl -O https://arthas.aliyun.com/arthas-boot.jarjava -jar arthas-boot.jarprofiler startprofiler stop

相关源码:
private SQLStatement parse0(final String sql, final boolean useCache) {if (useCache) {Optional<SQLStatement> cachedSQLStatement = cache.getSQLStatement(sql);// 缓存存在一样的sql,就从缓存里取,sql 是还含有占位符 ?的 sqlif (cachedSQLStatement.isPresent()) {return cachedSQLStatement.get();}}ParseTree parseTree = new SQLParserExecutor(databaseTypeName, sql).execute().getRootNode();SQLStatement result = (SQLStatement) ParseTreeVisitorFactory.newInstance(databaseTypeName, VisitorRule.valueOf(parseTree.getClass())).visit(parseTree);if (useCache) {cache.put(sql, result);}return result;}
神奇的现象:解析一条 sql 的平均时间为 500 ms,但在没有缓存的情况下,第二条 sql 的解析时间为 25 ms左右
long start = System.currentTimeMillis();String databaseType = "MySQL";SQLParserEngine parseEngine = SQLParserEngineFactory.getSQLParserEngine(databaseType);String sql = "select 'X'";parseEngine.parse(sql, true);System.out.println("第一次解析 sql 耗时:" + (System.currentTimeMillis() - start));long start2 = System.currentTimeMillis();SQLParserEngine parseEngine2 = SQLParserEngineFactory.getSQLParserEngine(databaseType);String sql2 = "select * from t_order_n where sharding_id=? and parent_order_no=?";parseEngine2.parse(sql2, true);System.out.println("第二次解析 sql 耗时:" + (System.currentTimeMillis() - start2));

充满好奇的我去剖析源码,然后发现 shardingJDBC 第一次解析 sql 主要慢在用工厂类创建单例对象,第二次解析时不用重新创建对象。
下面测试的代码是从 org.apache.shardingsphere.sql.parser.SQLParserEngine#parse 中抽离出来的
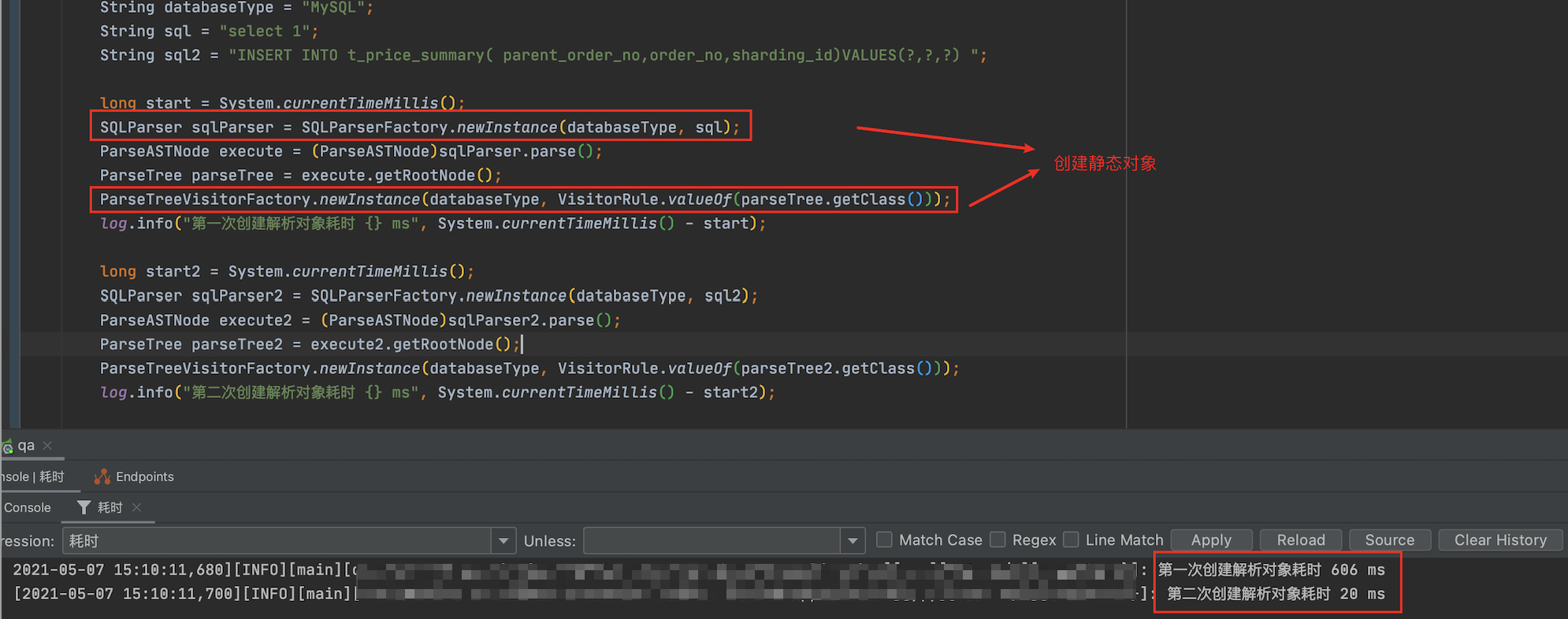
解决方案1:项目一启动就提前用 Antrl 去解析一条公共的sql :selec ‘x’,或者提前实例化相关对象
@PostConstructpublic void load() {// 提前解析一条公共的 sqlString databaseType = "MySQL";SQLParserEngine parseEngine = SQLParserEngineFactory.getSQLParserEngine(databaseType);String sql = "select 'X'";parseEngine.parse(sql, true);// 提前实例化相关对象SQLParser sqlParser = SQLParserFactory.newInstance(databaseType, sql);ParseASTNode execute = (ParseASTNode)sqlParser.parse();ParseTree parseTree = execute.getRootNode();ParseTreeVisitorFactory.newInstance(databaseType, VisitorRule.valueOf(parseTree.getClass()));}
解决方案2:预热 sql。启动过程中从存储捞取 SQL ( 当然项目初始上线必然为空 ) 进行 SQL 解析并使用反射填充缓存,而在容器销毁之前则同样通过反射将这个期间内收集到 SQL 保存作为后续的预加载。此外,考虑到平滑发布的必要性,启动过程加载及时抛错;同时只在启动和销毁的只执行一次,因此性能和并发并无问题。
@Configuration@ConditionalOnProperty(value = {"warmer.enable"},havingValue = "true")public class WarmerConfiguration {public static String prefix;@Value("${spring.application.name}")public void setPrefix(String name) {prefix = name;}@Bean@ConditionalOnClass(RedissonClient.class)@ConditionalOnBean(RedissonClient.class)@ConditionalOnMissingBean(WarmerStorage.class)public WarmerStorage warmerStorage(RedissonClient redissonClient) {return new RedissonWarmerStorage(redissonClient);}@Bean@DependsOn("shardingDataSource")public Warmer4SQL warmer4SQL(WarmerStorage warmerStorage) {return new Warmer4SQL(warmerStorage);}// fixme 需要考虑 sql 的数量和长度问题@Slf4jpublic static class Warmer4SQL implements ApplicationContextAware, InitializingBean {private WarmerStorage warmerStorage;public Warmer4SQL(WarmerStorage warmerStorage) {this.warmerStorage = warmerStorage;}private static Map<String, SQLParseEngine> ENGINES;private static Field cacheInSQLParseEngine;private static Field cacheInSQLParseResultCache;private static volatile boolean init = false;static {try {Field _ENGINES = SQLParseEngineFactory.class.getDeclaredField("ENGINES");_ENGINES.setAccessible(true);ENGINES = (Map<String, SQLParseEngine>) _ENGINES.get(null);cacheInSQLParseEngine = SQLParseEngine.class.getDeclaredField("cache");cacheInSQLParseEngine.setAccessible(true);cacheInSQLParseResultCache = SQLParseResultCache.class.getDeclaredField("cache");cacheInSQLParseResultCache.setAccessible(true);classesInClassLoader = ClassLoader.class.getDeclaredField("classes");classesInClassLoader.setAccessible(true);init = true;} catch (Exception e) {log.warn("cannot get fields because of !", e);}}@PostConstructpublic void load() {if (!init) return;long start = System.currentTimeMillis();log.info("loading at {}", start);loadSQL();long end = System.currentTimeMillis();log.info("loaded at {}, consumed {} milliseconds", end, end - start);}private void loadSQL() {ENGINES.keySet().forEach(databaseTypeName -> {Set<String> sqls = warmerStorage.load(databaseTypeName);log.info("the amount of sql fetched from storage is {}", sqls.size());sqls.forEach(sql -> ENGINES.get(databaseTypeName).parse(sql, true));log.debug("the details of sql fetched from storage are {}", sqls);});}// 异常已由 postProcessBeforeDestruction 处理@PreDestroypublic void save() {if (!init) return;long start = System.currentTimeMillis();log.info("saving at {}", start);saveSQL();long end = System.currentTimeMillis();log.info("saved at {}, consumed {} milliseconds", end, end - start);}private void saveSQL() {ENGINES.keySet().forEach(databaseTypeName -> {Set<String> sqls = getParsedSQL(databaseTypeName);log.info("the amount of sql going to be saved is {}", sqls.size());warmerStorage.save(databaseTypeName, sqls);log.debug("the details of sql going to be saved are {}", sqls);});}@SneakyThrowsprivate Set<String> getParsedSQL(String databaseTypeName) {return ((Cache) cacheInSQLParseResultCache.get(cacheInSQLParseEngine.get(ENGINES.get(databaseTypeName)))).asMap().keySet();}}}
在项目启动类加入上述代码后,发现第一次还是有点慢,重新生成火焰图,发现慢在了 sql 路由

解决方案:项目启动前执行一次完整的查询,即 sql解析,改写,路由,执行
@PostConstructpublic void load() throws Exception {Connection connection = dataSource.getConnection();String sql = "select 'X'";PreparedStatement preparedStatement = connection.prepareStatement(sql);preparedStatement.execute();}
结果:从 678 ms 变成 379 ms


























 gcc 升级")



")



还没有评论,来说两句吧...