Hadoop-MapReduce计数器和数据清洗
计数器应用

数据清洗(ETL)
在运行核心业务 MapReduce 程序之前,往往要先对数据进行清洗,清理掉不符合用户要求的数据。清理的过程往往只需要运行 Mapper 程序,不需要运行 Reduce 程序。
简单实操(实际使用会复杂的多,但是基本处理是一致的):
目的:去除日志中字段单词数小于等于20的日志
日志文件中最后一行数据为

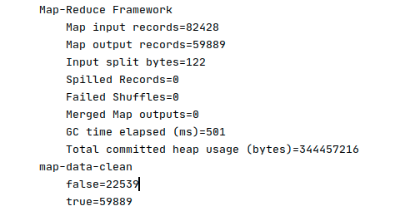
本日志文件有82428行数据。
期望输出的数据:每行字段单词数均大于20;
分析:在Map阶段对输入的数据根据规则进行过滤清洗
Mapper
public class DataCleanMapper extends Mapper<LongWritable, Text, Text, NullWritable> {@Overrideprotected void map (LongWritable key, Text value, Context context) throws IOException, InterruptedException {String line = value.toString();// 解析数据boolean result = parseLog(line, context);if (!result) {return;}context.write(value, NullWritable.get());}private boolean parseLog (String line, Context context) {String[] fileds = line.split(" ");if (fileds.length > 20) {// 引入计数器context.getCounter("map-data-clean", "true").increment(1);return true;}context.getCounter("map-data-clean", "false").increment(1);return false;}}
Driver中需要将ReduceTask数量设置为0
// 设置reduceTask的数量为0job.setNumReduceTasks(0);
运行之后,查看计数器如下:

























")



")


还没有评论,来说两句吧...