3.MySQL数据库的基本操作和常用sql语句
一、基本概念
1.1 什么是数据库(database/db)
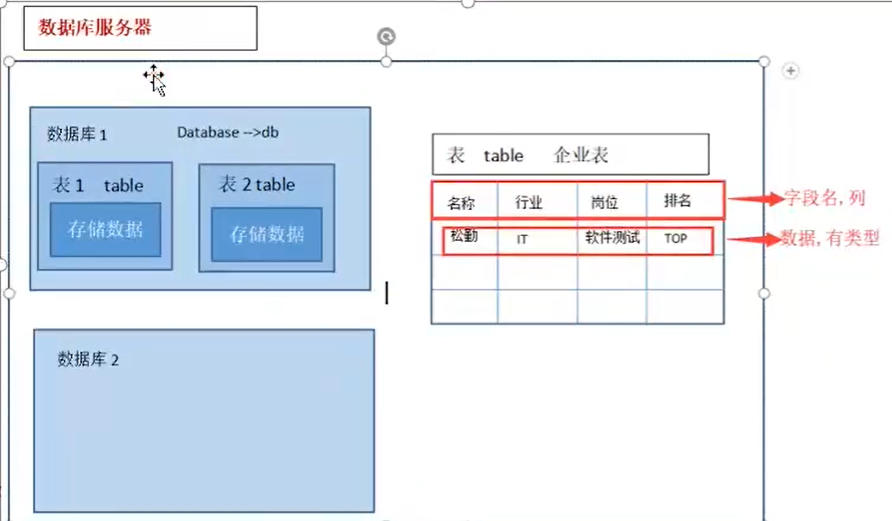
数据库是存放数据的仓库,包括文档、视频、图片、密码等
数据库管理系统是用来连接数据库的工具,可以操作增删改查功能
1.2 数据库的基本操作

二、数据库操作
2.1 查询操作-查
2.1.1 SQL select 语句
SELECT语句用于从表中选取数据,结果被存储在一个结果表中(称为结果集)
语法:
SELECT 列名称 FROM 表名称;
以及
SELECT * from test0709;
数据库语法结尾是;
注释使用–或者//或者#
--显示所有数据库show databases;--使用其中一个数据库user test;show tables;//查看库中所有的表//*是匹配任何值,from不分大小写,后面加表名select * from test0709;
2.1.2 查询操作的通配符

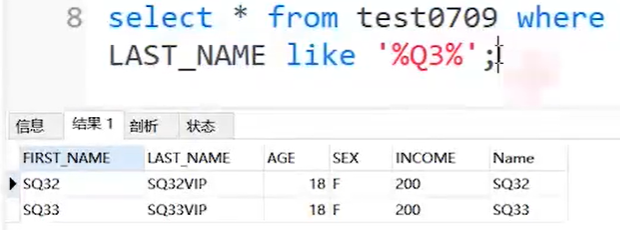
“%”通配符
select * from test0709 where LAST_NAME like '%Q3%';--查找last_name中含有“Q3”字符的数据
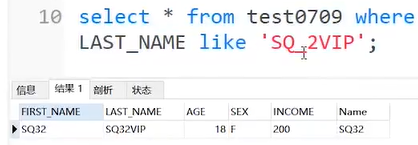
“-”通配符
select * from test0709 where LAST_NAME like 'SQ_2VIP';--“-”智能匹配一个字符
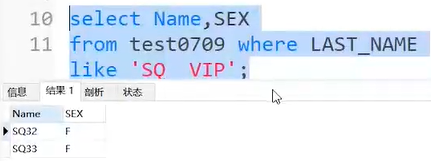
查询部分列表的语句
select Name,SEX from test0709 where LAST_NAME like 'SQ VIP';
2.2 增加操作-增
2.2.1 insert into 语句
INSERT INTO语句用于向表格中插入新的行
语法:
insert into 表名称(字段名1,字段名2,...) values (值1,值2,...)
也可以指定所要插入数据的列:
insert into table_name(列1,列2,...) values (值1,值2,...)
示例:
向表中添加一个属性:
alter table +table的名字+ add + 字段名字 + 数据类型+分号
例如:
alter table testTable add font varchar(20) , add age int ;
解析:在表testTable中插入了2个字段,font和age
2.2.2 大批量插入数据
例:
可以有主键,将主键设置为自增长
2.3 删除操作-删
2.3.1 delete语句
delete语句用于删除表中的行
语法:
delete from 表名 where 列名 = 值
示例:
注:delete后没有,select后面有*
错误结果:
注:此时是因为有两条同样的数据
2.3.2 安全模式的确认
set SQL_SAFE_UPDATES = 0;//此时表示可以删除数据
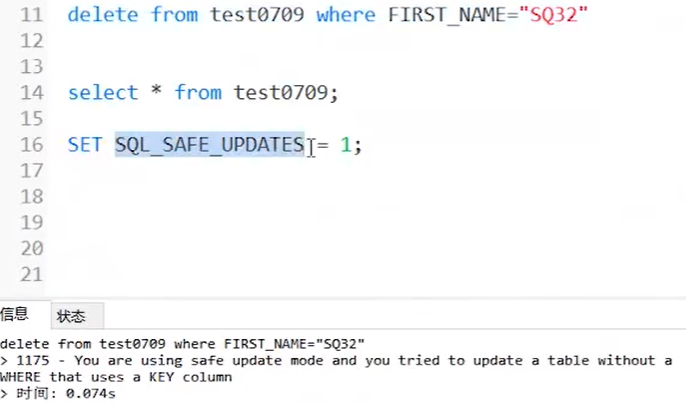
这个错误是因为数据库更新本来应该为0,此时为1
2.4 更新操作-改
update 语句
update语句用于修改表中的数据
语法:
update 表名 set 列名 = 新值 where 列名 = 某值;
示例:
注意安全模式的确认
2.5 查询操作补充
2.5.1 查找指定的几行数据
select * from test0709 limit 5;
2.5.2 查询列别显示别名
select FIRST_NAME as "姓",LAST_NAME as "名" from test0709;
2.5.3 计算符合条件的平均年龄,且显示为别名
select avg(age) as "平均年龄" from test0709;
三、数据库连接
3.1连接查询
3.1.1 内连接查询-inner join
关键字:inner join on
语句:
select * from a_table a inner join b_table b on a.a_id = b.b_id;
说明:组合两个表中的记录,返回关联字段相符的记录,也就是返回两个表的交集(阴影)部分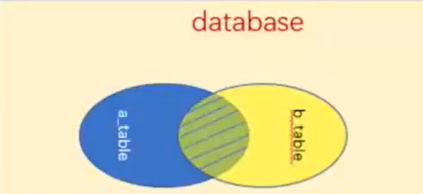
示例: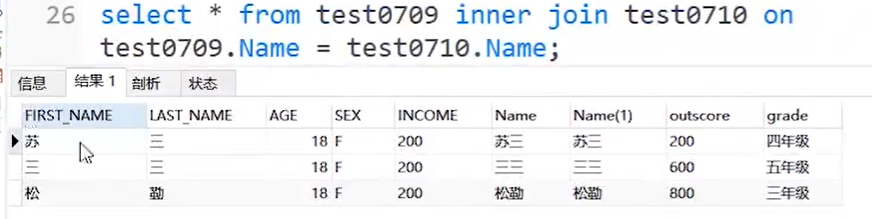
3.1.2 外连接查询
①左外连接-left join
关键字:left join on /left outer join on
语句:
select * from a_table a left join b_table b on a.a._id = b.b_id;
说明:left join,左(外)连接,左表(a_table)的记录将会全部表示出来,而右表(b_table)只会显示符合搜索条件的记录,右边记录不足的地方均为NULL
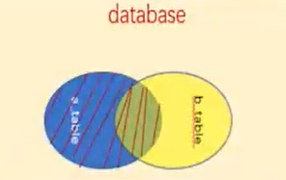
示例: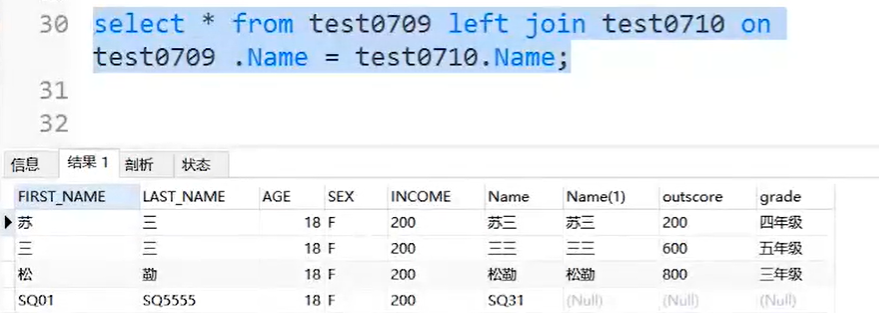
②右外连接-right join
关键字:right join on /right outer join on
语句:
select * from a_table a right join b_table b on a.a._id = b.b_id;
说明:right join,右(外)连接,右表(b_table)的记录将会全部表示出来,而左表(a_table)只会显示符合搜索条件的记录,左边记录不足的地方均为NULL
示例:
四、数据库常见面试题
4.1 主键、外键、超键、候选键?
主键:用户选做元组表示的候选键为主键,不加说明时,键就是主键
外键:如果模式R中的属性k是其他模式的主键,那么k在模式R中称为外键
超键:在关系中能唯一标识元素属性的集称为关系模式的超键
候选键:不含有多余属性的超键称为候选键。在候选键中再删除属性,就不是键了
例:学生成绩信息表中有(学号、姓名、年龄、系别、专业等)
超键:学生表中含有学号和身份证号的任意组合都是此表的超键。如:(学号)、(学号,姓名)、(学号、性别)等
假设学生姓名唯一,没有重名现象
候选键:
主键:是候选键中的一个,是人为规定的,如:学生表中,通常会让“学号”做主键,学号能唯一标识这个元组
外键:如:还有一个教师表,每个教师都有自己的编号,假设老师编号在老师这个层次中是主键,在学生表中就是外键
4.2 为什么用自增列作为主键?
1、如果我们定义了主键,那么InnoDB会选择主键作为聚集索引;如果没有显式定义主键,则InnoDB会选择第一个不包含有NULL值的唯一索引作为主键索引、如果也没有这样的唯一索引,则InnoDB会选择内置6字节长的ROWID作为隐含的聚集索引(ROWID随着行记录的写入而主键递增,这个ROWID不像ORACLE的ROWID那样可引用,是隐含的)。
2、数据记录本身被存于主索引 (一颗B+Tree)的叶子节点上。这就要求同一个叶子节点内(大小为一个内存页或磁盘页)的各条数据记录按主键顺序存放,因此每当有一条新的记录插入时,MySQL会根据其主键将其插入适当的节点和位置,如果页面达到装载因子(InnoDB默认为15/16),则开辟一个新的页(节点)
3、如果表使用自增主键,那么每次插入新的记录,记录就会顺序添加到当前索引节点的后续位置,当一页写满,就会自动开辟一个新的页
4、如果使用非自增主键(如果身份证号或学号等),由于每次插入主键的值近似于随机,因此每次新纪录都要被插到现有索引页得中间某个位置,此时MySQL不得不为了将新记录插到合适位置而移动数据,甚至目标页面可能已经被回写到磁盘上而从缓存中清掉,此时又要从磁盘上读回来,这增加了很多开销,同时频繁的移动、分页操作造成了大量的碎片,得到了不够紧凑的索引结构,后续不得不通过OPTIMIZE TABLE来重建表并优化填充页面。
4.3 触发器的作用?
【1】可在写入数据表前,强制检验或转换数据
【2】触发器发生错误时,移动的结果会被撤销
【3】部分数据库管理系统可以针对数据定义语言(DDL)使用触发器,称为DDL触发器
【4】可依照特定的情况,替换移动的指令(INSTEAD OF)
触发器的优点:
可通过数据库中的相关表实现级联更改,不过,通过级联引用完整性约束可以更有效地执行这些更改。
可以强制用比CHECK约束定义的约束更为复杂的约束。与CHECK约束不同,触发器可以引用其它表中的列。
4.4 什么是存储过程?用什么来调用?
存储过程是一个预编译的SQL语句,优点是允许模块化的设计,就是说只需要创建一次,以后再该程序中可以调用多次。
如果某次操作需要执行多次SQL,使用存储过程比单纯SQL语句执行要快,可以用一个命令对象来调用存储过程
4.5 存储过程的优缺点?
优点:
【1】重复使用:存储过程可以重复使用,从而可以减少数据库开发人员的工作量
【2】减少网络流量:存储过程位于服务器上,调用的时候只需要传递存储过程的名称以及参数就可以,因此降低了网络传输的数据量
【3】安全性:参数化的存储过程可以防止SQL注入式攻击,而且可以将Grant、Deny以及Revake权限应用于存储过程
缺点:
【1】更改比较繁琐:如果更改范围达到需要对输入存储过程的参数进行更改,或者要更改由其返回的数据,则仍然需要更新程序集中的代码以添加参数、更新 GetValue()调用等,这时比较繁琐
【2】可移植性差:由于存储过程中将应用程序绑定到SQL Server,因此使用存储过程封装业务逻辑将限制应用程序的可移植性
4.6 存储过程与函数的区别?
一、含义不同
存储过程:是SQL语句和可选控制流语句的预编译集合,以一个名称存储并作为一个单元处理
函数:是由一个或多个SQL语句组成的子程序,可用于封装代码以便重新使用,函数限制较多,如:不能用临时表,只能用表变量等
二、使用条件不同
存储过程:可以在单个存储过程中执行一系列SQL语句,而且可以从自己的存储过程内引用其他存储过程,这可以简化一系列复杂语句
函数:自定义函数诸多限制,有许多语句不能使用,许多功能不能实现,函数可以直接引用返回值,永彪变量返回记录集。但是,用户定义函数不能用于执行一组修改全局数据库状态的操作
三、执行方式不同
存储过程:可以返回参数,如:记录集,函数只能返回值或者表对象,存储过程的参数有in、out、inout三种,声明时不需要返回值类型
函数:函数参数只要in,且函数需要描述返回值类型,且函数中必须包含一个有效的return语句


























——SURF特征提取算法详解")

——FAST算法解析")





还没有评论,来说两句吧...