「数据分析师的网络爬虫」动态页面和Ajax渲染页面抓取
文章目录
- 内容介绍
- Ajax抓取示例
- JS动态加载示例
内容介绍
开发环境为 Python3.6 ,爬虫项目全部内容索引目录
看懂Python爬虫框架,所见即所得一切皆有可能
本文介绍动态页面和Ajax渲染页面数据抓取的示例,以及相应的页面分析过程,你会发现本来想想复杂的网页爬虫居然比那些非动态网页的抓取要更简单。
虽说不会敲代码的 Python数据分析师 不是好的数据分析师,但你不是正儿八经的开发人员,代码敲的那么溜有什么用?学点数据爬虫基础能让繁琐的数据CV工作(Ctrl+C,Ctrl+V)成为自动化就足够了。
Ajax抓取示例
现在越来越多的网页的原始HTML文档不包括任何数据,而是采用Ajax统一加载。发送Ajax请求道网页更新的过程:
- 发送请求。
- 解析内容。
- 渲染网页。
打开浏览器的开发者工具,到Networkk选项卡,使用XHR过滤工具。需要按照对应all_config_file.py文件建立对应相应文件夹修改该配置并且开启相关服务。
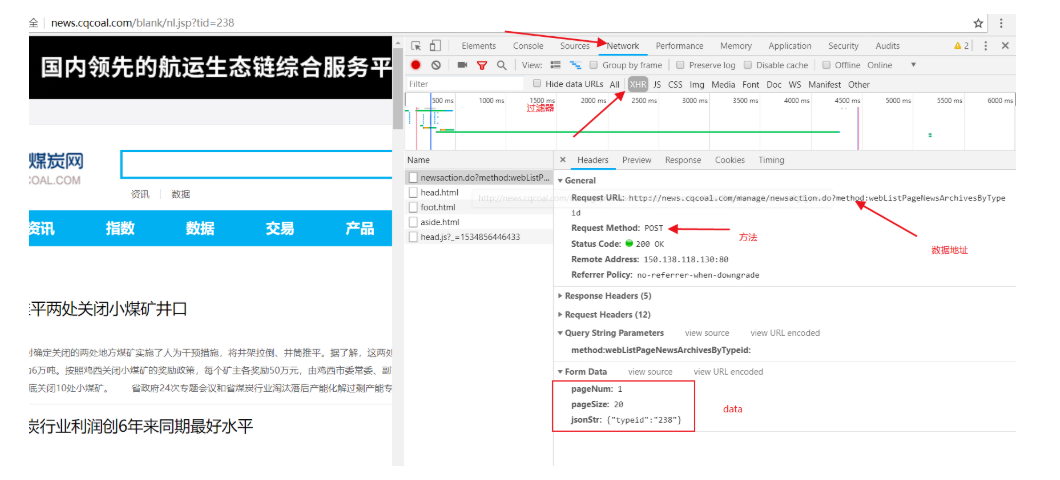
all_config_file.py
#coding=utf-8__author__ = 'Mr数据杨'__explain__ = '各目标网站爬虫脚本配置文件'#加载引用模块import timeimport pymongoimport pandas as pddef news_page_num():page_num=input("输入每个网站页面爬取的页面数:")return int(page_num)def title_error_num():title_error_num=input("输入错误标题爬取最大数:")return int(title_error_num)def body_error_num():body_error_num=input("输入错误页面爬取最大数:")return int(body_error_num)def mongodb_client():# 获取mongoClient对象client = pymongo.MongoClient("localhost", 27017)# 获取使用的database对象db = client.newsprint("加载MongoDB数据库完毕......")return dbdb=mongodb_client()def time_today():# 全局函数time_today = time.strftime('%Y-%m-%d', time.localtime(time.time()))print("加载全局日期函数完毕......")return time_today# 错误日志信息def error_text_title(text,time_today):print("加载错误信息日志完毕......")with open("logs/" + time_today + " news_title_error.txt", "a") as f:f.write(text + '\n')# 错误日志信息def error_text_body(text,time_today):with open("logs/" + time_today + " news_body_error.txt", "a") as f:f.write(text + '\n')# 找到每个爬取网页的链接def get_title_links_from_MongoDB(label, type):result = []for item in db.news_tmp.find({ 'label': label, 'type': type}, { 'url': 1, '_id': 1}):result.append(item)result = pd.DataFrame(result, columns=['url', '_id'])return result
主程序
#加载引用模块import urllibimport urllib.requestimport requestsimport datetimefrom bs4 import BeautifulSoupimport all_config_filefrom all_config_file import error_text_titlefrom all_config_file import error_text_bodyfrom all_config_file import get_title_links_from_MongoDBcqcoal = "http://news.cqcoal.com/manage/newsaction.do?method:webListPageNewsArchivesByTypeid"print("加载目标网址完毕......")db = all_config_file.mongodb_client()time_today = all_config_file.time_today()def cqcoal_title_start(num):def start_type(url, label, typeid, pagenum, type):try:page_num = 1while page_num <= pagenum:print("开始爬取:" + url)page_num += 1user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'headers = { 'User-Agent': user_agent}req = urllib.request.Request(url, headers=headers)response = requests.get(url, headers=headers, timeout=10)post_param = { 'pageNum': pagenum, 'pageSize': '20', 'jsonStr': typeid}# post_param = post_param.format(typeid)return_data = requests.post(url, data=post_param, verify=False)content = return_data.text# print(content)if label == 'news.cqcoal.com':one_page = get_cqcoal_page_news(content, type)print('新闻抓取完毕')except:error = str(url+ " label:" + label + " gd:" + str(typeid) + " pagenum:" + str(pagenum) + " type:" + type + ' 未抓取到')error_text_title(error, time_today)print (error)def get_cqcoal_page_news(content, type):l = content.split("},{")for i in [*range(len(l))]:url = "http://news.cqcoal.com/blank/nc.jsp?mid=" + l[i][l[i].find("id") + 4:l[i].find("typeid") - 2]title = l[i][l[i].find("title") + 8:l[i].find("shorttitle") - 3]typename = l[i][l[i].find("typename") + 11:l[i].find("typeid2") - 3]timeStamp = l[i][(l[i].find("pubdate") + 10):(l[i].find("senddate") - 3)]description = l[i][l[i].find("description") + 14:l[i].find("filename") - 3]timeStamp = int(timeStamp)dateArray = datetime.datetime.utcfromtimestamp(timeStamp)pubdate = dateArray.strftime("%Y-%m-%d")one_page = { 'title': title, 'url': url, 'date': pubdate, 'type': type, 'label': 'news.cqcoal.com'}db.news_tmp.insert_one(one_page)return one_page###news.cqcoal.comdef start_Cqcoal_supply_and_demand():start_type(cqcoal, 'news.cqcoal.com', '{"typeid":"238"}', num, 'supply_and_demand')def start_Cqcoal_price():start_type(cqcoal, 'news.cqcoal.com', '{"typeid":"234"}', num, 'price')def start_Cqcoal_dynamic():start_type(cqcoal, 'news.cqcoal.com', '{"typeid":"235"}', num, 'dynamic')def start_Cqcoal_international():start_type(cqcoal, 'news.cqcoal.com', '{"typeid":"236"}', num, 'international')def start_Cqcoal_comment():start_type(cqcoal, 'news.cqcoal.com', '{"typeid":"14"}', num, 'comment')def start_Cqcoal_transportation():start_type(cqcoal, 'news.cqcoal.com', '{"typeid":"239"}', num, 'transportation')def start_Cqcoal_economics():start_type(cqcoal, 'news.cqcoal.com', 'road_price}', num, 'economics')def start_Cqcoal_policy():start_type(cqcoal, 'news.cqcoal.com', '{"typeid":"230"}', num, 'policy')def start_Cqcoal_correlation():start_type(cqcoal, 'news.cqcoal.com', '{"typeid":"237"}', num, 'correlation')def start_Cqcoal_expert():start_type(cqcoal, 'news.cqcoal.com', '{"typeid":"232"}', num, 'expert')start_Cqcoal_transportation()start_Cqcoal_supply_and_demand()start_Cqcoal_price()start_Cqcoal_policy()start_Cqcoal_international()start_Cqcoal_expert()start_Cqcoal_economics()start_Cqcoal_dynamic()start_Cqcoal_correlation()start_Cqcoal_comment()def cqcoal_body_start():def get_new_body(label, type):link_list = get_title_links_from_MongoDB(label, type)if label == 'news.cqcoal.com':try:for url in link_list['url']:news_body, news_body_1 = get_news_Cqcoal_text(url,label, type)if news_body is not None:db.news_tmp.update({ 'url': url}, { "$set": { 'newsbody': news_body}})db.news_tmp.update({ 'url': url}, { "$set": { 'newsbody_1': news_body_1}})print("网站:" + label + " 类型:" + type + "内容爬取完毕!")except:error = str(url + " error:" + ' label:' + label + " type:" + type)#error_text(error)print(error)def get_news_Cqcoal_text(url,label, type):# html = urllib.request.urlopen(url,timeout=5)id = url.split('=')[1]url = 'http://news.cqcoal.com/manage/newsaction.do?method:getNewsAddonarticle'post_param = { 'id': id}# return_data = requests.post(url,data =post_param, verify = False)try:return_data = requests.post(url, data=post_param, verify=False, timeout=120)except:print("error label:", url, " Time out!")error = str(url + " error:" + ' label:' + label + " type:" + type)error_text_body(error, time_today)return None, Nonereturn_data = return_data.texttry:newsBody = return_data[return_data.find("body") + 7:return_data.find("xh") - 3]newsBody_1 = return_data[return_data.find("body") + 7:return_data.find("xh") - 3]print(url + " 记录爬取完毕")return newsBody, newsBody_1except:print("error label:", url, " type:", type)error = str(url + " error:" + ' label:' + label + " type:" + type)error_text_body(error, time_today)return None, None###news.cqcoal.comdef start_body_Cqcoal_transportation():get_new_body('news.cqcoal.com', 'transportation')def start_body_Cqcoal_supply_and_demand():get_new_body('news.cqcoal.com', 'supply_and_demand')def start_body_Cqcoal_price():get_new_body('news.cqcoal.com', 'price')def start_body_Cqcoal_policy():get_new_body('news.cqcoal.com', 'policy')def start_body_Cqcoal_international():get_new_body('news.cqcoal.com', 'international')def start_body_Cqcoal_expert():get_new_body('news.cqcoal.com', 'expert')def start_body_Cqcoal_dynamic():get_new_body('news.cqcoal.com', 'dynamic')def start_body_Cqcoal_economics():get_new_body('news.cqcoal.com', 'economics')def start_body_Cqcoal_correlation():get_new_body('news.cqcoal.com', 'correlation')def start_body_Cqcoal_comment():get_new_body('news.cqcoal.com', 'comment')start_body_Cqcoal_transportation()start_body_Cqcoal_supply_and_demand()start_body_Cqcoal_price()start_body_Cqcoal_policy()start_body_Cqcoal_international()start_body_Cqcoal_expert()start_body_Cqcoal_economics()start_body_Cqcoal_dynamic()start_body_Cqcoal_correlation()start_body_Cqcoal_comment()
JS动态加载示例
浏览器渲染引擎:渲染引擎的职责就是渲染,即在浏览器窗口中显示所请求的内容。浏览器向服务器发送请求,得到服务器返回的资源文件后,经过需要渲染引擎的处理,将资源文件显示在浏览器窗口中。
目前使用较为广泛的渲染引擎有两种:
- webkit——使用者有Chrome, Safari
- Geoko——使用者有Firefox
渲染主流程:渲染引擎首先通过网络获得所请求文档的内容,通常以8K分块的方式完成。下面是渲染引擎在取得内容之后的基本流程:
- 解析html以构建dom树 -> 构建render树 -> 布局render树 -> 绘制render树渲染引擎开始解析html,并将标签转化为内容树中的dom节点。如果遇到JS,那么此时会启用单独连接进行下载,并且在下载后进行解析。
- 接着,它解析外部CSS文件及style标签中的样式信息。这些样式信息以及html中的可见性指令将被用来构建另一棵树——render树。
- Render树由一些包含有颜色和大小等属性的矩形组成,它们将被按照正确的顺序显示到屏幕上。
- Render树构建好了之后,将会执行布局过程,它将确定每个节点在屏幕上的确切坐标。
- 再下一步就是绘制,即遍历render树,并使用UI后端层绘制每个节点。
渲染动态网页,有两种选择:
- 自己从头实现一个浏览器渲染引擎,在合适的时机返回构建的dom树或render树。
- 这需要进行大量的工作,需要考虑html、js、css等不同格式文件的解析方式以及解析顺序等。
以36氪主页抓取为实例。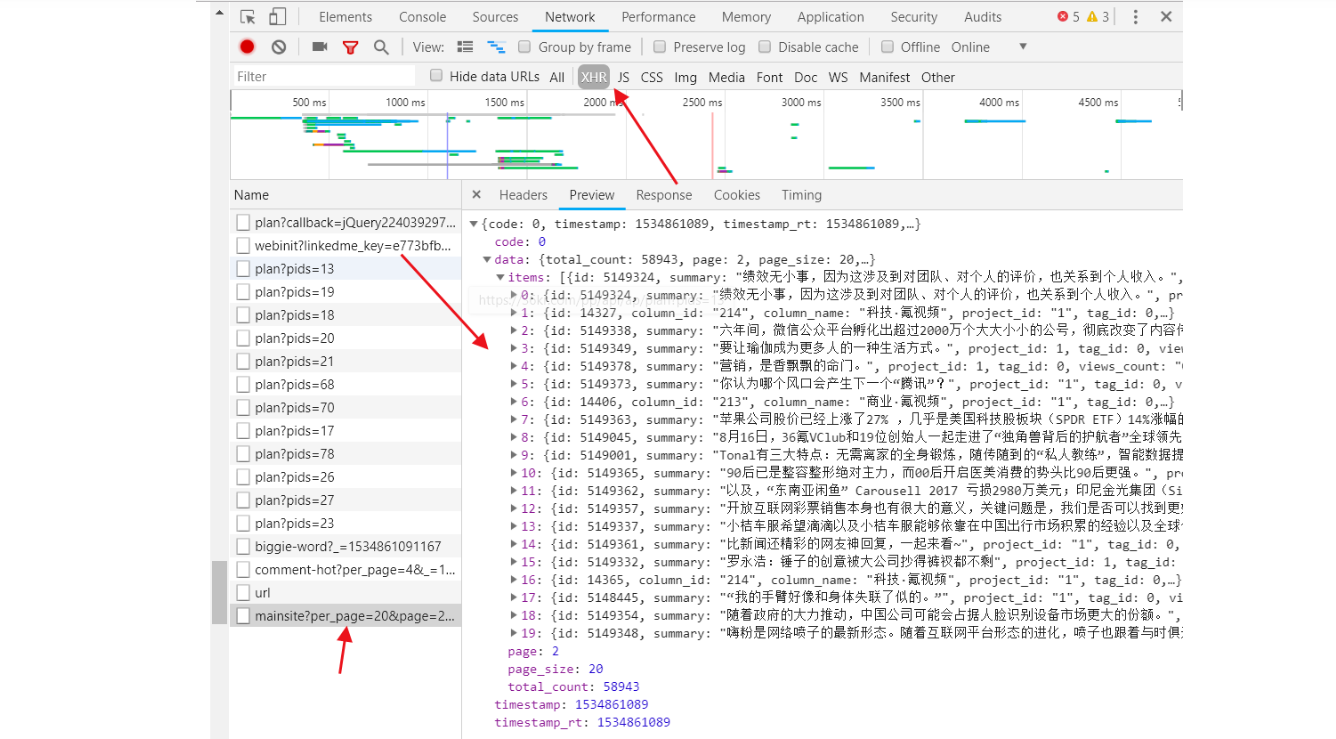
import warningswarnings.filterwarnings("ignore")import timeimport requestsimport pymongoimport pandas as pdimport refrom lxml import etree# 获取mongoClient对象client = pymongo.MongoClient("localhost", 27017)# 获取使用的database对象db = client.newstoday=time.strftime('%Y.%m.%d',time.localtime(time.time()))def main(page_num):#开始爬取数据设定抓取页面数字n=int(page_num)def start_crawler(pro,col,adress):i=1while i<= n:t = time.time()url = "https://36kr.com/api/search-column/{}?per_page=20&page={}&_=".format(pro,i)+str(int(t))i+=1post_param = { 'per_page':'20',\'page':str(i),\'_':int(t)}time.sleep(2)user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'headers = { 'User-Agent' : user_agent }return_data = requests.get(url,data =post_param, verify = False)one_page = get_news_link_to_mongodb(return_data,col,url,adress)print (adress+" "+col+' 新闻标题抓取完毕')def get_news_link_to_mongodb(return_data,col,url,adress):content = return_data.json().get('data').get('content')for i in return_data.json().get('data').get('items'):one_page = { 'title': i["title"], \'url_html': "https://36kr.com/p/"+str(i["id"])+".html",\'url_json': "https://36kr.com/p/"+str(i["id"])+".json",\'summary':i["summary"],\'tags': re.sub(r'[0-9"\[\]]','',i["extraction_tags"]).replace(",,"," ").replace(",",""),\'label':col,\'adress':adress,\'work_date':time.strftime('%Y.%m.%d',time.localtime(time.time()))}db.kr36.insert_one(one_page)print("已经完成抓取 "+adress+" "+col+" 板块页面:"+url)def news_body_start(label,adress,today):url_list = []for item in db.kr36.find({ 'label': label,'adress':adress,'work_date':today}, { 'url_json': 1}):url_list.append(item)url_list = pd.DataFrame(url_list, columns=['url_json'])for i in url_list["url_json"]:html = requests.get(i)a=html.json().get('props').get('detailArticle|post').get('content')sel = etree.HTML(a)clear_content = sel.xpath('string(//*)')db.kr36.update({ 'url_json': i}, { "$set": { 'newsbody': clear_content}})print(i+" 抓取完毕")print (adress+" "+label+" "+"新闻主体抓取完毕")start_crawler('23','大公司',"36kr")start_crawler('221','消费',"36kr")start_crawler('225','娱乐',"36kr")start_crawler('218','前沿技术',"36kr")start_crawler('219','汽车交通',"36kr")start_crawler('208','区块链',"36kr")start_crawler('103','技能get',"36kr")news_body_start("大公司","36kr",today)news_body_start("消费","36kr",today)news_body_start("娱乐","36kr",today)news_body_start("前沿技术","36kr",today)news_body_start("汽车交通","36kr",today)news_body_start("区块链","36kr",today)news_body_start("技能get","36kr",today)#导出模块name = { 'adress':'36kr'}search_res = db.kr36.find(name)list_=[]for i in search_res:list_.append(i)ddf=pd.DataFrame(list_,columns=["title","url_html","tags","labels","adress","summary","newsbody"])ddf.to_csv("36氪首页news.csv",encoding="utf_8_sig")if __name__ == '__main__':page_num=input("输入需要抓取的页数")main(page_num)





























-- volatile关键字解析")




还没有评论,来说两句吧...