Unix/Linux编程:文件IO的内核缓冲
- 出于速度和效率考虑,系统 I/O 调用(即内核)和标准 C 语言库 I/O 函数(即 stdio 函数)在操作磁盘文件时会对数据进行缓冲
- 程序通过缓冲技术来减少系统调用的次数,仅当缓冲区满或者读缓冲区空时才调用内核服务
缓冲技术
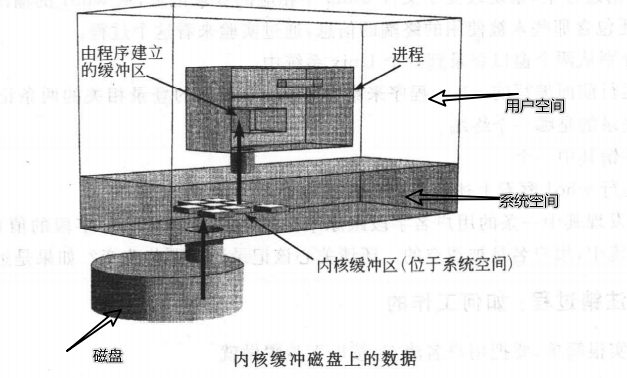
文件IO的内核缓冲:缓冲器高速缓存
read()和write()系统调用在操作磁盘文件时不会直接发起磁盘访问,而是仅仅在用户空间缓冲区与内核缓冲区高速缓存(kernel buffer cache)之间复制数据。
比如,如下调用将3个字节的数据从用户空间内存传递到内核空间的缓冲区中:
write(fd, "abc", 3);
- write()随即返回。在后继某个时刻,内核会将其缓冲区中的数据写入(刷新至)磁盘(也就是说,系统调用与磁盘操作并不同步)。如果在此期间,另一进程试图读取该文件的这几个字节,那么内核将自动从缓冲区高速缓存中提供这些数据,而不是从文件中(读取过期的内容)。
- 同样,对输入而言,内核从磁盘中读取数据并存储到内核缓冲区中,read()调用将从该缓冲区中读取数据,直到把缓冲区中的数据取完。这时,内核会将文件的下一段内容读取缓冲区高速缓存(这里的描述有所简化,对于序列化的文件访问,内核通常会尝试执行预读,以确保在需要之前就将文件的下一数据块读入缓冲区高速缓存中)
采用这一设计,意在使read()和write()调用的操作更为快速,因为它们不需要等待(缓慢的)磁盘操作。同时,这一设计也更加高效,因为这减少了内核必须执行的磁盘传输次数。
总之,如果与文件发生大量的数据传输,通过采用大块空间缓冲数据,以及执行更少的系统调用,可以极大的提高IO性能。(缓冲区大小为 4096 个字节时,需要调用 read()和 write() 24000 次左右,几乎达到最优性能。设置再超过这个值,对性能的提升就不显著了,这是因为与在用户空间和内核空间之间复制数据以及执行实际磁盘 I/O 所花费的时间相比,read()和 write() 系统调用的成本就显得微不足道了)
Linux内核对缓冲区高速缓存的大小没有固定上限。内核会分配尽可能多的缓冲区高速缓存页,而仅受限于两个因素
- :可用的物理内容总量,
- 出于其他目录对物理内存的需求求(例如,需要将正在运行进程的文本和数据页保留在物理内存中)。
如果可用内存不足,则内核会将一些修改过的缓冲区高速缓存页内容刷新到磁盘,并释放其供系统使用。
更确切地说,从内核 2.4 开始,Linux 不再维护一个单独的缓冲区高速缓存。相反,会将文件 I/O 缓冲区于页面高速缓存中,其中还含有诸如内存映射文件的页面。之所以采用“缓冲区高速缓存(buffer cache)”这一术语,因为这是 UNIX 实现中历史悠久的通称
系统在将每个缓冲区中数据向磁盘传递时会把程序阻塞起来。
stdio库的缓冲
当操作磁盘文件时,缓冲大块数据以减少系统调用。C语言函数库的IO函数数(比如,fprintf()、fscanf()、fgets()、fputs()、fputc()、fgetc())就是这么做的。因此,使用stdio库可以使编程者免于自行处理对数据的缓冲,无论是调用write()来输出,还是调用read()来输入。
设置一个stdio流的缓冲模式
调用stebuf()函数,可以控制stdio库使用缓冲的形式。
NAMEsetbuf, setbuffer, setlinebuf, setvbuf - 流缓冲操作SYNOPSIS 总览#include <stdio.h>void setbuf(FILE *stream, char *buf);void setbuffer(FILE *stream, char *buf, size_t size);void setlinebuf(FILE *stream);int setvbuf(FILE *stream, char *buf, int mode , size_t size);DESCRIPTION 描述有三种类型的缓冲策略,它们是无缓冲,块缓冲和行缓冲。当输出流无缓冲时,信息在写的同时出现于目标文件或终端上;当是块缓冲时,字符被暂存,然后一起写入;当是行缓冲时,字符被暂存,直到要输出一个新行符,或者从任何与终端设备连接的流中读取输入时才输出(典型的是 stdin) 。函数 fflush(3)可以用来强制提前输出。通常所有文件都是块缓冲的(参见 fclose(3)) 。当文件I/O操作在文件上发生时,将调用malloc(3),获得一个缓冲。如果流指向一个终端 (通常 stdout都是这样),那么它是行缓冲的。标准错误流 stderr 默认总是无缓冲的。函数 setvbuf 可以用在任何打开的流上,改变它的缓冲。参数 mode 必须是下列三个宏之一:_IONBF 无缓冲_IOLBF 行缓冲_IOFBF 完全缓冲除非是无缓冲的文件,否则参数buf应当指向一个长度至少为size字节的缓冲;这个缓冲将取代当前的缓冲。如果参数 buf 是 NULL,只有这个模式会受到影响;下次read或write操作还将分配一个新的缓冲。函数 setvbuf只能在打开一个流,还未对它进行任何其他操作之前使用。其他三个函数调用是函数 setvbuf 的别名,函数 setbuf 与使用下列语句完全等价:setvbuf(stream, buf, buf ? _IOFBF : _IONBF, BUFSIZ);要么将参数 buf 指定为 NULL 以表示无缓冲要么指向由调用者分配的 BUFSIZ 个字节大小的缓冲区函数 setbuffer 与此相同,但是缓冲的长度由用户决定,而不是由默认值 BUFSIZ 决定。函数 setlinebuf 与使用下列语句完全等价:setvbuf(stream, (char *)NULL, _IOLBF, 0);RETURN VALUE 返回值函数 setvbuf 成功执行时返回 0。它失败时可能返回任何值,CONFORMING TO 标准参考函数 setbuf 和 setvbuf 遵循 ANSI X3.159-1989 (``ANSI C'') 标准。
参数stream标识将要修改哪个文件流的缓冲。
- 打开流之后,必须在调用任何其他stdio函数之前先调用 setvbuf()。
- setvbuf()调用将影响后续在指定流上进行的所有 stdio 操作。
- (不要将 stdio 库所使用的流与 System V 系统的 STREAMS 机制相混淆,Linux 的主线内核中并未实现 System V 系统的 STREAMS)
参数 buf 和 size 则针对参数 stream 要使用的缓冲区,指定这些参数有如下两种方法
- 如果参数 buf 不为 NULL,那么其指向 size 大小的内存块以作为 stream 的缓冲区。因为 stdio 库将要使用 buf 指向的缓冲区,所以应该以动态或静态在堆中为该缓冲区分配一块空间(使用 malloc()或类似函数),而不应是分配在栈上的函数本地变量。否则,函数返回时将销毁其栈帧,从而导致混乱
- 如果buf为NULL,那么stdio库会为stream自动分配一个缓冲区(除非选择非缓冲的IO)。SUSv3 允许,但不强制要求库实现使用 size 来确定其缓冲区的大小
参数mode指定了缓冲类型,并具有如下值之一:
- _IONBF :不对IO进行缓冲。每个stdio库函数将立即调用write()或者read(),并且忽略buf和size参数,可以分别指定两个参数为NULL和0. stderr默认属于这一类型,从而保证错误能够立即输出
- _IOLBF: 采用行缓冲 I/O。指代终端设备的流默认属于这一类型。对于输出流,在输出一个换行符(除非缓冲区已经填满)前将缓冲数据。对于输入流,每次读取一行数
_IOFBF: 采用全缓冲 I/O。单次读、写数据(通过 read()或 write()系统调用)的大小与缓冲区相同。
指代磁盘的流默认采用此模式static char buf[BUFSIZ];
if(setvbuf(stdout, buf, _IOFBF, BUFSIZ) != 0){perror("setvbuf");exit(EXIT_FAILURE);}
刷新stdio缓冲区
无论当前采用何种缓冲区模式,在任何时候,都可以使用fflush()库函数强制将stdio输出流中的数据刷新到内核缓冲区。此函数会刷新指定stream的输出缓冲区
NAMEfflush - 刷新一个流SYNOPSIS 总览#include <stdio.h>int fflush(FILE *stream);DESCRIPTION 描述函数 fflush 强制在所给的输出流或更新流 stream 上,写入在用户空间缓冲的所有数据,使用流的底层写功能函数。流的打开状态不受影响。如果参数 stream 是 NULL, fflush 刷新 所有 打开的流。要使用非锁定的对应版本,参见 unlocked_stdio(3) 。RETURN VALUE 返回值成功执行返回 0,否则返回 EOF 并设置全局变量 errno 来指示错误发生。
- 若参数 stream 为 NULL,则 fflush()将刷新所有的 stdio 缓冲区。
- 也能将 fflush()函数应用于输入流,这将丢弃业已缓冲的输入数据。(当程序下一次尝试从流中读取数据时,将重新装满缓冲区。)
- 当关闭相应流时,将自动刷新其 stdio 缓冲区
若打开一个流同时用于输入和输出,则 C99 标准中提出了两项要求。首先,一个输出操作不能紧跟一个输入操作,必须在二者之间调用 fflush()函数或是一个文件定位函数(fseek()、fsetpos()或者 rewind())。其次,一个输入操作不能紧跟一个输出操作,必须在二者之间调用一个文件定位函数,除非输入操作遭遇文件结尾。
控制文件IO的内核缓冲
强制刷新内核缓冲区到输出文件这是可能的。而且有时很有必要。在描述用于控制内核缓冲的系统调用之前,有必要先熟悉一下 SUSv3 中的相关定义。
同步 I/O 数据完整性和同步 I/O 文件完整性
SUSv3将同步IO(synchronized I/O completion)完成定义为:某一IO操作,要么已经完成到磁盘的数据传递,要么被诊断为不成功。
SUSv3定义了两种不同类型的synchronized I/O completion:
synchronized I/O data integrity completion:旨在确保针对文件的一次更新传递了足够的信息(到磁盘),以便于之后对数据的读取
- 就读操作而言,这意味着被请求的文件数据已经(从磁盘)传递给了进程。如果存在任何影响到所请求数据的挂起写操作,那么在执行读操作之前,会将这些数据传递到磁盘
就写操作而言,这意味着写请求所指定的数据已经传递(到磁盘)完毕,而且用于获取数据的所有文件元数据也已经传递(到磁盘)完毕。
- 此处的要点在于要获取文件数据,并非需要传递所有经过修改的文件元数据属性。
- 发生修改的文件元数据中需要传递的属性之一是文件大小(如果写操作确实扩展了文件)。
- 相形之下,如果是文件时间戳发生了变化,就无需在下次获取数据前将其传递到磁盘 ——- 如果是诸如最近修改时间戳之类的元数据属性发生了变化,那么是无需传递到磁盘的
- Synchronized I/O file integrity completion:是synchronized I/O data integrity completion的超集。该IO完成模式的区别在于对文件的一次更新过程中,要将所有更新的文件元数据都传递到磁盘上,即使有些在后续对文件数据的读操作中并不需要
二者之间的区别涉及用于描述文件的元数据(数据的数据),也就是内核针对文件而存储的数据。
用于控制文件IO内核缓冲的系统调用
sync、fsync、fdatasync
问: 为什么引入sync、fsync、fdatasync
- 传统的UNIX实现在内核中设有缓冲区高速缓存或页面高速缓存,大多数磁盘I/O都通过缓冲进行。当将数据写入文件时,内核通常先将该数据复制到其中一个缓冲区中,如果该缓冲区尚未写满,则并不将其排入输出队列,而是等待其写满或者当内核需要重用该缓冲区以便存放其他磁盘块数据时,再将该缓冲排入输出队列,然后待其到达队首时,才进行实际的I/O操作。这种输出方式被称为延迟写(delayed write)
- 延迟写减少了磁盘读写次数,但是却降低了文件内容的更新速度,使得欲写到文件中的数据在一段时间内并没有写到磁盘上。当系统发生故障时,这种延迟可能造成文件更新内容的丢失。为了保证磁盘上实际文件系统与缓冲区高速缓存中内容的一致性,UNIX系统提供了sync、fsync和fdatasync三个函数。
问: 相关API
#include <unistd.h>/** 功能: 将所有修改过的块缓冲区排入写队列,然立即返回,无需等待实际写操作结束* 通常称为update的系统守护进程会周期性地(一般每隔30秒)调用sync函数。这就保证了定期冲洗内核的块缓冲区。命令sync(1)也调用sync函数。*/void sync (void)/** 功能:fsync函数只对由文件描述符filedes指定的单一文件起作用(针对文件描述符fd的数据部分和文件属性同步),并且等待写磁盘操作结束,然后返回。fsync可用于数据库这样的应用程序,这种应用程序需要确保将修改过的块立即写到磁盘上。* 返回值:成功返回0,失败返回-1*/int fsync (int __fd)/** 功能:fdatasync函数类似于fsync,但它只影响文件的数据部分* 返回值:成功返回0,失败返回-1*/int fdatasync (int __fildes)
sync:
- sync()系统调用会使包含更新文件信息的所有内核缓冲区(即数据块、指针块、元数据等)刷新到磁盘上
- 在 Linux 实现中,sync()调用仅在所有数据已传递到磁盘上(或者至少高速缓存)时返回。然而,SUSv3 却允许 sync()实现只是简单调度一下 I/O 传递,在动作未完成之前即可返回。
fsync():
- fsync()系统调用将使缓冲数据和打开文件描述符fd相关的所有元数据都刷新到磁盘上。调用 fsync()会强制使文件处于 Synchronized I/O file integrity completion 状态。
- 仅在对磁盘设备(或者至少是其高速缓存)的传递完成后,fsync()调用才会返回。
fdatasync():
- fdatasync()系统调用的运作类似于 fsync(),只是强制文件处于 synchronized I/O data integrity completion 的状态。
- fdatasync()可能会减少对磁盘操作的次数,由fsync()调用请求的两次变为一次。比如,如果修改了文件数据,而文件大小不变,那么调用fdatasync()只强制进行了数据更新。相比之下,fsync()调用会强制将元数据传递到磁盘上
- 对某些应用而言,以这种方式来减少磁盘 I/O 操作的次数是很有用的,比如对性能要求极高,而对某些元数据(比如时间戳)的准确性要求不高的应用。当应用程序同时进行多处文件更新时,二者存在相当大的性能差异,因为文件数据和元数据通常驻留在磁盘的不同区域,更新这些数据需要反复在整个磁盘上执行寻道操作
始于内核 2.6.17,Linux 提供了非标准的系统调用 sync_file_range(),当刷新文件数据时,该调用提供比 fdatasync()调用更为精准的控制。调用者能够指定待刷新的文件区域,并且还能指定标志,以控制该系统调用在遭遇写磁盘时是否阻塞。更详细的信息请参阅sync_file_range(2)手册页
如内容发生变化的内核缓冲区在30s内未经显示方式同步到磁盘上,则一条长期运行的内核线程会确保将其刷新到磁盘上。这一做法是为了规避缓冲区与相关磁盘文件内容长期出于不一致状态的问题(以至于在系统崩溃时发生数据丢失)。在 Linux 2.6 版本中,该任务由pdflush 内核线程执行。(在 Linux 2.4 版本中,则由 kupdated 内核线程执行。)
文件/proc/sys/vm/dirty_expire_centisecs 规定了在 pdflush 刷新之前脏缓冲区必须达到的“年龄”(以 1%秒为单位)。位于同一目录下的其他文件则控制了 pdflush 操作的其他方面。
问: 对于提供事务支持的数据库,在事务提交时,都要确保事务日志(包含该事务所有的修改操作以及一个提交记录)完全写到硬盘上,才认定事务提交成功并返回给应用层。
那么: 在unix操作系统上,怎样保证对文件的更新内容成功持久化到硬盘?
- write不够,需要fsync
一般情况下,对硬盘(或者其他持久存储设备)文件的write操作,更新的只是内存中的页缓存(page cache),而脏页面不会立即更新到硬盘中,而是由操作系统统一调度,如由专门的flusher内核线程在满足一定条件时(如一定时间间隔、内存中的脏页达到一定比例)内将脏页面同步到硬盘上(放入设备的IO请求队列)。
因为write调用不会等到硬盘IO完成之后才返回,因此如果OS在write调用之后、硬盘同步之前崩溃,则数据可能丢失。虽然这样的时间窗口很小,但是对于需要保证事务的持久化(durability)和一致性(consistency)的数据库程序来说,write()所提供的“松散的异步语义”是不够的,通常需要OS提供的同步IO(synchronized-IO)原语来保证:
int fsync (int __fd)
fsync的功能是确保文件fd所有已修改的内容已经正确同步到硬盘上,该调用会阻塞等待直到设备报告IO完成。
PS:如果采用内存映射文件的方式进行文件IO(使用mmap,将文件的page cache直接映射到进程的地址空间,通过写内存的方式修改文件),也有类似的系统调用来确保修改的内容完全同步到硬盘之上:
int msync(void *addr, size_t length, int flags)
msync需要指定同步的地址区间,如此细粒度的控制似乎比fsync更加高效(因为应用程序通常知道自己的脏页位置),但实际上(Linux)kernel中有着十分高效的数据结构,能够很快地找出文件的脏页,使得fsync只会同步文件的修改内容。
- fsync的性能问题,与fdatasync
除了同步文件的修改内容(脏页),fsync还会同步文件的描述信息(metadata,包括size、访问时间st_atime & st_mtime等等),因为文件的数据和metadata通常存在硬盘的不同地方,因此fsync至少需要两次IO写操作,fsync的man page这样说:
"Unfortunately fsync() will always initialize two write operations : one for the newly written data and another one in order to update the modification time stored in the inode. If the modification time is not a part of the transaction concept fdatasync() can be used to avoid unnecessary inode disk write operations."
多余的一次IO操作,有多么昂贵呢?根据Wikipedia的数据,当前硬盘驱动的平均寻道时间(Average seek time)大约是3~15ms,7200RPM硬盘的平均旋转延迟(Average rotational latency)大约为4ms,因此一次IO操作的耗时大约为10ms左右。这个数字意味着什么?下文还会提到。
Posix同样定义了fdatasync,放宽了同步的语义以提高性能:
int fdatasync(int fd);
fdatasync的功能与fsync类似,但是仅仅在必要的情况下才会同步metadata,因此可以减少一次IO写操作。那么,什么是“必要的情况”呢?根据man page中的解释:
"fdatasync does not flush modified metadata unless that metadata is needed in order to allow a subsequent data retrieval to be corretly handled."
PS:open时的参数O_SYNC/O_DSYNC有着和fsync/fdatasync类似的语义:使每次write都会阻塞等待硬盘IO完成。(实际上,Linux对O_SYNC/O_DSYNC做了相同处理,没有满足Posix的要求,而是都实现了fdatasync的语义)相对于fsync/fdatasync,这样的设置不够灵活,应该很少使用。
- 使用fdatasync优化日志同步
文章开头时已提到,为了满足事务要求,数据库的日志文件是常常需要同步IO的。由于需要同步等待硬盘IO完成,所以事务的提交操作常常十分耗时,成为性能的瓶颈。
在Berkeley DB下,如果开启了AUTO_COMMIT(所有独立的写操作自动具有事务语义)并使用默认的同步级别(日志完全同步到硬盘才返回),写一条记录的耗时大约为5~10ms级别,基本和一次IO操作(10ms)的耗时相同。
我们已经知道,在同步上fsync是低效的。但是如果需要使用fdatasync减少对metadata的更新,则需要确保文件的尺寸在write前后没有发生变化。日志文件天生是追加型(append-only)的,总是在不断增大,似乎很难利用好fdatasync。
且看Berkeley DB是怎样处理日志文件的:
- 1.每个log文件固定为10MB大小,从1开始编号,名称格式为“log.%010d”
- 2.每次log文件创建时,先写文件的最后1个page,将log文件扩展为10MB大小
- 3.向log文件中追加记录时,由于文件的尺寸不发生变化,使用fdatasync可以大大优化写log的效率
- 4.如果一个log文件写满了,则新建一个log文件,也只有一次同步metadata的开销
使所有写同步:O_SYNC
调用open()函数时如果指定O_SYNC标志,则会使所有后继输出同步(synchronous):
fd = open(pathname, O_WRONLY, O_SYNC);
调用open()后,每个write()调用会自动将文件数据和元数据刷新到磁盘上(即,按照Synchronized I/O file integrity completion 的要求执行写操作)
早期 BSD 系统曾使用 O_FSYNC 标志来提供 O_SYNC 标志的功能。在 glibc 库中,将O_FSYNC 定义为与 O_SYNC 标志同义
注意:采用 O_SYNC 标志(或者频繁调用 fsync()、fdatasync()或 sync())对性能的影响极大
总之,如果需要强制刷新内核缓冲区,那么在设计应用程序时应该考虑是否可以使用大尺寸的write()缓冲区,或者在调用fsync()或fdatasync()时谨慎行事,而不是在打开文件时就使用 O_SYNC 标志
O_DSYNC 和 O_RSYNC 标志
SUSv3 规定了两个与同步 I/O 有关的、更为细化的打开文件状态标志:O_DSYNC 和O_RSYNC。
- O_SYNC 标志,遵从 synchronized I/O file integrity completion(类似于 fsync()函数)
- O_DSYNC 标志要求写操作按照 synchronized I/O data integrity completion 来执行(类似fdatasync())。
O_RSYNC 标志是与 O_SYNC 标志或 O_DSYNC 标志配合一起使用的,将这些标志对写操作的作用结合到读操作中。
- 如果在打开文件时同时指定 O_RSYNC 和 O_DSYNC 标志,那么就意味着会遵照 synchronized I/O data integrity completion 的要求来完成所有后续读操作
- 如果在打开文件时同时指定 O_RSYNC 和 O_SYNC 标志,则意味着会遵照 synchronized I/O file integrity completion 的要求来完成所有后续读操作
IO缓冲总结
下图概况了stdio函数库和内核所采用的缓冲(针对输出文件),以及对各种缓冲类型的控制机制。
- 首先通过stdio库将用户传递到stdio缓冲区,该缓冲区位于用户态内存区。
- 当缓冲区满了,stdio库会调用write()系统调用,将数据传递到内核高速缓冲区(位于内核态内存区)
- 最终,内核发起磁盘操作,将数据传递到磁盘
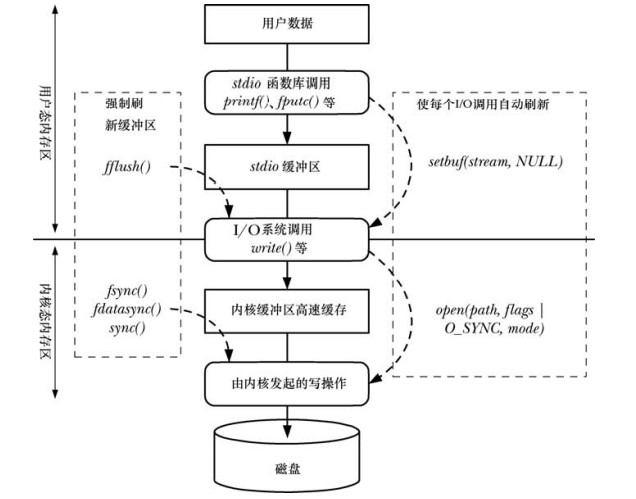
- 左侧所示为于任何时刻显示强制刷新各类缓冲区的调用
右侧所示为促使刷新自动化的调用:
- 通过禁用stdio库的缓冲
- 在文件输出类的系统调用中启动同步,从而使每个write()调用立即刷新到磁盘



























SpringCloud学习笔记之案例搭建")






还没有评论,来说两句吧...