MySQL MVCC 底层原理总结
MySQL MVCC 底层原理总结
- 什么是 MVCC?
- 原理
- 重要字段
- 版本的组成
- 什么是 ReadView?
- 假如我再次修改,如何增加版本?
- 判断当前数据是否可见的 4 大准则
- 隔离级别如何进行事务控制的
- 读未提交
- 读已提交
- 可重复读
- 串行化
什么是 MVCC?
全称Multi-Version Concurrency Control,即多版本并发控制,主要是为了提高数据库的并发性能。
每当数据在进行修改操作时,MySQL 会将所有的修改操作串联,形成一种数据的版本链条。根据事务隔离级别的不同,能够访问到的最新数据也不同,以此进行控制。
原理
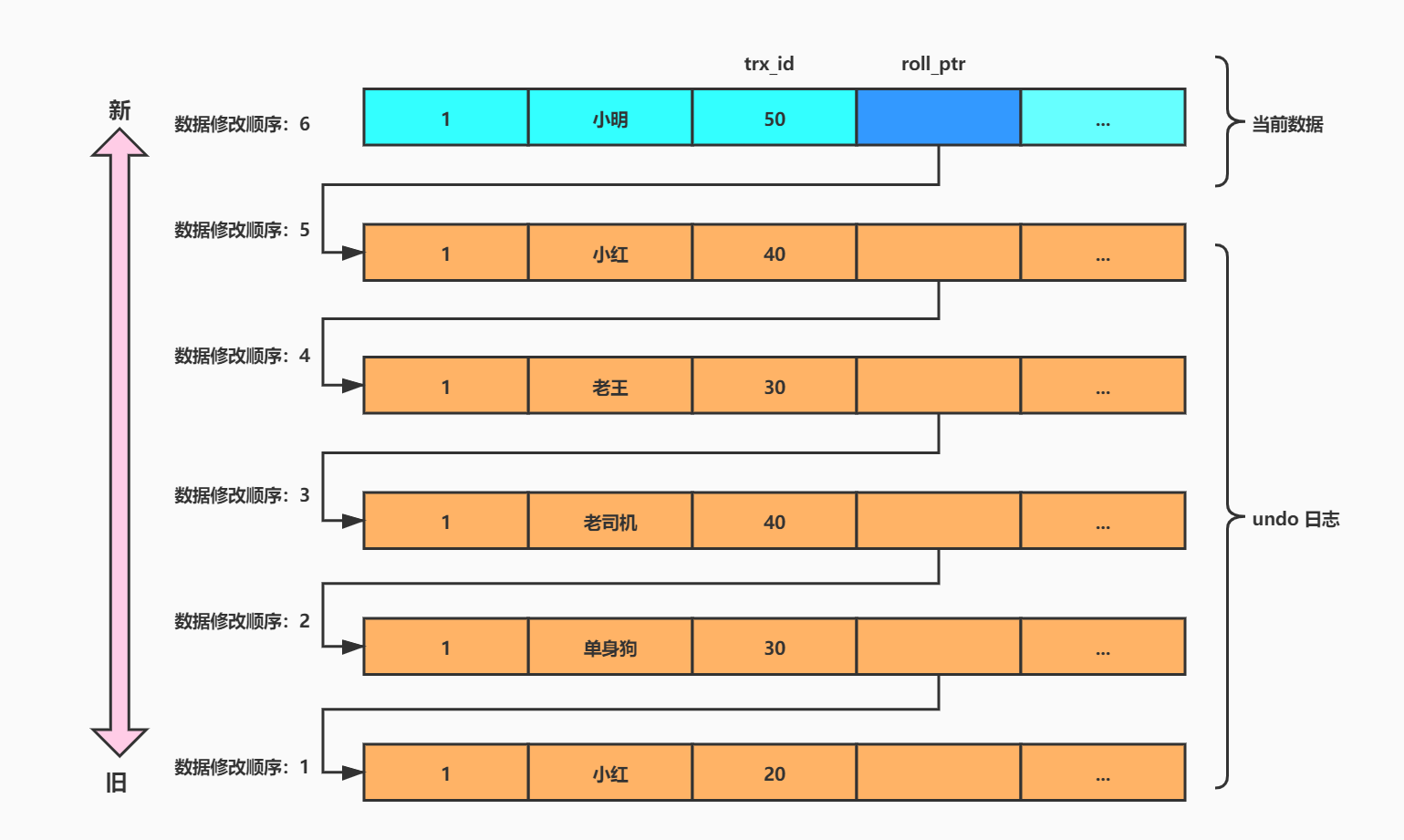
重要字段
- trx_id: 当前事务的 ID
- roll_ptr: 回滚指针,指向下一个最新的 undo 日志版本
版本的组成
当前最新数据上存储有 roll_ptr 字段,指向下一个最新的 undo 日志版本
undo 日志上各条数据的回滚指针也会依次指向下一个版本的数据,以此形成一个版本链条
什么是 ReadView?
每一个事务在启动时,都会生成一个 ReadView,用来记录一些内容
ReadView 存储的内容:
- m_ids: 当前系统中活跃的事务(说明事务未提交)
- min_trx_id: 当前活跃事务中最小的那个
- max_trx_id: 下一个即将生成的事务 ID(并非当前活跃事务中最大的)
- creat_trx_id:生成 RV 的事务ID(这样就指定当前的 RV 属于哪个事务)
假如我再次修改,如何增加版本?
假如再次修改,修改的数据就会替换当前最新数据
而之前的数据就会下沉到 undo 日志的头部,可以理解为头插法
判断当前数据是否可见的 4 大准则
MySQL 根据四大准则,顺着版本链向下,找到第一个满足条件的数据,就是当前事务能看到的数据
- 如果 ReadView 中的 creator_trx_id 值 = trx_id 属性值 ,数据可见
理解: trx_id 属性值与 ReadView 中的 creator_trx_id 值相同,说明该版本是当前事务中的操作数据 - 如果ReadView 中的 min_trx_id 值 > trx_id 属性值 ,数据可见
理解:min_trx_id 比 trx_id 大,首先说明 trx_id 肯定不在存活事务范围内,其次说明 trx_id 事务是早发生的,并且结束,已经 commit 的事务 - 如果ReadView 中的 max_trx_id < trx_id 属性值,数据不可见
理解:最大的都比 trx_id 小,说明肯定是当前事务之后才启动的事务,因此肯定不可见 - 如果 min_trx_id <= trx_id <= max_trx_id。如果 trx_id 在存活事务范围内,数据不可见;如果不属于存活的事务,数据可见
理解:存活说明事务没结束因此不可见,不存活说明事务已经结束,因此可见。
PS:ReadView 中的参数才是当前事务的指标,而版本链上的 trx_id 是历史版本,别弄反了
隔离级别如何进行事务控制的
读未提交
读未提交能够读取到其他事务未提交的数据,因此很简单,直接读最新数据就行了。
读已提交
每次读取时候,都会重新读取 ReadView 数据,后续根据 4 大标准判断
举例:
- 首先启动事务A(trx_id:1)
- 启动事务B(trx_id:2),此时事务B 对应的存活事务 m_ids=[1,2],min_trx_id=1,max_trx_id=3
- 事务A 执行更新操作,未提交事务
- 事务B 查询,此时事务B 对应的存活事务 m_ids=[1,2],因此不会查到事务A 的修改
- 事务A 提交事务
- 事务B 查询,根据 读已提交 隔离状态下,每次都会去更新 RV,此时事务B 对应的 RV:m_ids=[2],min_trx_id=2,max_trx_id=3
- 事务B 查询数据,此时事务A(1 NOT IN [2])不再是存活事务,因此能查到事务A的修改
可重复读
只有第一次读取时读取 ReadView 数据,后续根据 4 大标准判断
举例:
- 首先启动事务A(trx_id:1)
- 启动事务B(trx_id:2),此时事务B 对应的存活事务 m_ids=[1,2],min_trx_id=1,max_trx_id=3
- 事务A 执行更新操作,未提交事务
- 事务B 查询,此时事务B 对应的存活事务 m_ids=[1,2],因此不会查到事务A 的修改
- 事务A 提交事务
- 事务B 查询,根据 可重复读 隔离状态下,仅第一次读取 RV,后续不会更新 ,此时事务B 对应的 RV:m_ids=[1,2],min_trx_id=1,max_trx_id=3
- 事务B 查询数据,此时事务A(1 IN [1,2]),不满足准则 4,因此不能查到事务A的修改
串行化
不管读还是写操作,都会直接加锁,不存在并发问题
由于 Innodb 在可重复读阶段就已经解决大多数幻读问题,因此一般不使用此隔离级别


































还没有评论,来说两句吧...