OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks
OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks

文章目录
- OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks
- 参考
- Introduction
- Classification
- **Multi-Scale Classification(参考3)**
- **offset池化**
- Localization
- Detection
参考
- 1.OverFeat 详解
- 2.解读OverFeat
- 3.论文笔记:OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks
Introduction
- 它用一个共享的CNN来同时处理图像分类,定位,检测三个任务,可以提升三个任务的表现。
- 它用CNN有效地实现了一个多尺度的,滑动窗口的方法,来处理任务。
- 提出了一种方法,通过累积预测来求bounding boxes(而不是传统的非极大值抑制)(没太懂)。
Classification
分类问题提出了两个模型:fast model 和 additional model
- fast model 的结构如下,其中第二层的input size理论上是接上层,而上层算出来是28,因此我怀疑是作者的失误
- 然后说说网络,没有使用归一化(normalization)以及重叠池化(overlap pooling)
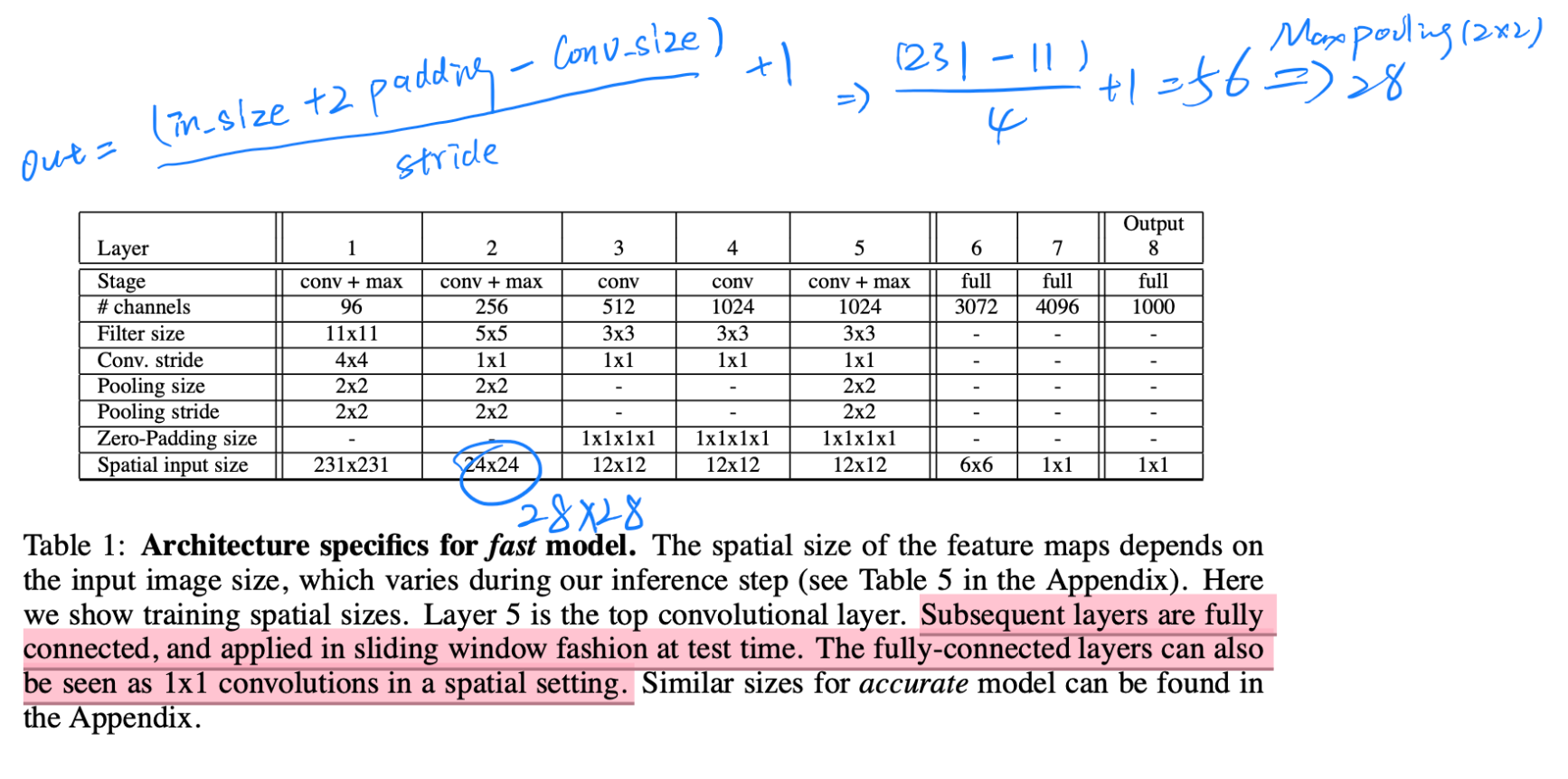
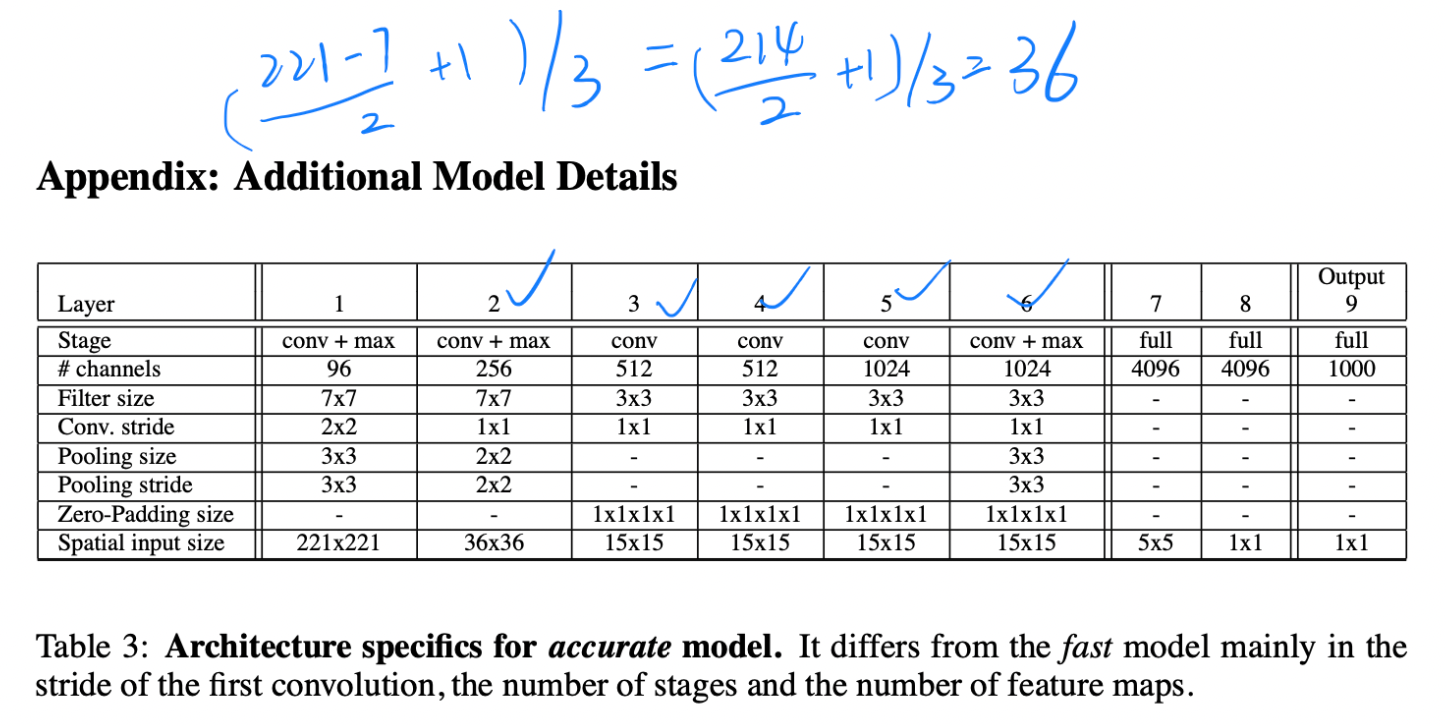
- 相对的,additional model是对的,相对于fast model 它拥有更深的backbone,同时第一层的Conv.stride从4变成2,也是提升精度的方式(但相对的计算量变大),也因此输出的feature map也会稍大一点,有利于后续操作的精度(分类)。
Multi-Scale Classification(参考3)
使用了全卷积,我个人感觉就是相对于全链接保留了局部特征(如果是FC的话,就直接reshape成1列,然后学习,不如这个有针对性),同时在多尺度分类的时候全卷积只需要执行一次(而如果用FC的话没有局部关系就得执行多次,因为同一个点的weight可能不同),下面是参考3中的说法
- 上图中各层的输入大小是训练时的,由于在测试时会输入6张不同尺寸的图,所以大小肯定都不一样的。
- **全卷积是什么:**上图中后三层的全连接层实际上使用的是全卷积,全连接层是可以转为全卷积的,举例来说,全连接层的输入shape为551024的feature map,输出为4096的话,参数个数就是5510244096,这个时候转为全卷积层,那么卷积的参数就是,卷积核大小为55*1024,卷积核个数为4096,二者的参数量是一样的。
- **全卷积导致了什么:**如下图所示,对14*14的图像进行卷积操作,在得到5*5的feature map后的这一步,如果使用全连接,就会把它压平再全连接,这样就破坏了feature map的图像位置关系,直接转为一列特征。但是如果使用的是全卷积,最后会得到1*1*C的feature map,C是channel数,也是类别的大小。这个时候如果来了一张16*16的图像,经过全卷积后就会得到2*2*C的feature map,这个时候可以对这个2*2的4个值做一个取最大或平均,就会变成一个值了,以此类推,来了更大的图像,最后得到的feature map就是3*3*C,4*4*C,5*5*C的大小,输出的大小和输入的大小相关,但总是可以对这个输出map池化(取最大)来得到这个类别的值。
- **全卷积的好处:**下图中第一个图是训练时用14*14的图像,最后产生一个输出,下面的图是测试时,可以用16*16的图像产生了“2*2”个输出,以此类推我们可以在测试时使用更大的图像(使用多scale),产生“更多”的输出进行(取最大)预测。这个做法相对于传统的滑动窗口(用14*14大小,步长为2的滑动窗口在16*16的图像上执行4次卷积操作进行分类)的优点是,只需要执行一次,保证了效率同时可以建模用各种不同尺度图像,不局限于固定的裁剪翻转方式(相对于alexNet测试阶段的做法),而且消除了很多冗余计算,提高了模型的鲁棒性又保证了效率。

offset池化
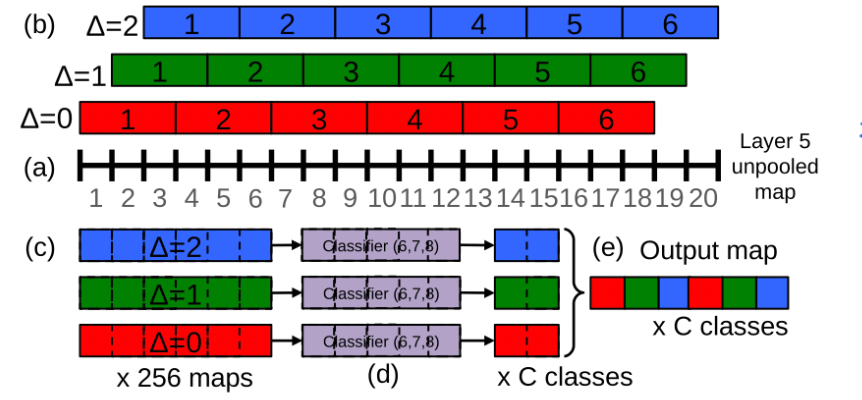
offset池化就是首先将池化核偏移一定值(可设置,文中是{0,1,2}),然后进行池化,下图是对一个一维的20个像素点的feature map进行池化,池化的时候向下取整(一般的池化是向上,即20/3=6—2,不够的2独自池化一次,算一个),得到6个结果,然后交叉输出map
Localization
- 在原有的分类layer基础上并行一个回归网络,同时多尺度train,最后合并得出预测结果。
- 回归框训练时候采用l2 loss,且IOU<0.5的框不参加训练
合并策略(不同于NMS):Combining Predictions
- 我的理解是:选取前k个框(每个尺度),然后进行合并这里box_merge的目的是将两个box合并成一个框,因为match_score是计算算的是两box中心点的距离,越小说明越接近,于是在B中删除原有的两个框然后加上新merge出来的框

Detection
- 检测的训练和分类的训练差不多,只是分类最后输出的是1*1的一个输出,而检测产生的是n*n的spatial输出,一张图像的多个位置被同时训练。
- 和定位任务相比,最主要的不同是需要预测一个背景类,考虑一个图像没有物体时。

























——开发流程")






还没有评论,来说两句吧...