动作识别《X3D: Expanding Architectures for Efficient Video Recognition》
开源代码:https://github.com/facebookresearch/SlowFast
核心思想:
论文的核心思想是在考虑计算量和准确率的折中前提下,只沿着时间维度进行扩展并不一定比沿着其他维度扩展模型效果更好,尤其在低计算量的限制下,沿着其他维度进行扩展可能准确率提升更快。
X3D方法尝试从不从的维度对2D卷积进行扩展,使其适用于3D时空数据处理,扩展的维度包括时间维度大小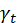 、采样帧率
、采样帧率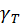 、输入的分辨率大小
、输入的分辨率大小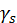 、卷积核的数量
、卷积核的数量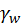 、时间维度的卷积设置
、时间维度的卷积设置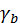 以及网络的深度
以及网络的深度 。
。

坐标下降方法参考:https://zhuanlan.zhihu.com/p/129279351
借鉴机器学习中的特征选择方法:
1、前向特征选择:不断加入新特征直至性能不在提升
2、后向特征选择:不断移除无关特征直至性能出现明显下降
对于将2D网络扩展到3D网络,作者提出以下问题:
1、3D网络的最佳采样策略是什么?是长视频的稀疏采样,还是短视频的密集采样?
2、对于视频分类任务,是否需要细粒度的空间分辨率特征?当空间分辨率达到一定条件时,视频分类的性能会不会达到饱和?
3、是采用高帧率(时间维度长)低通道数(width小)还是采用低帧率(时间维度短)高通道数(width大)的模型性能更好?
4、当增加网络宽度时,是增加ResBlock的宽度还是增加ResBlock的bottleneck层的宽度?
5、为了保证具有足够的感受野大小,在增加网络深度的同时要不要增加输入的图像分辨率大小?
X2D**网络:**
各个维度的扩展参数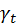 、
、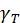 、
、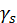 、
、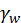 、
、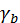 、
、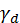 全都为1.
全都为1.

X2D**网络特性:**
- 残差模块中的3D卷积模块3x3x3采用了与MobileNetV1使用的深度可分离卷积来降低卷积模块的参数量和计算量pytorch卷积操作nn.Conv中的groups参数用法解释
- 上图中的第一个卷积层conv1是对RGB图像进行逐个通道卷积,那么对于RGB三通道图像,卷积之后输出24个通道,是不是只需要8组3x1的卷积核就可以,这点没太理解???
- X2D在时间维度上与SlowFast网络保持一致,网络的每一步中不会改变时间维度的大小,也就是说不会在时间维度上使用pooling池化或者conv卷积操作
X3D**网络(对X2D进行维度扩充):**
各个扩展维度解释:
X-Fast:在保证采样视频片段长度的情况下,增加采样频率,从而增加时间维度的分辨率,也就是增加输入到网络的时间维度大小。
X-Temporal:同时增加采样的视频片段长度和采样频率,从而增加输入到网络的时间维度大小。
X-Spatial:增加输入到网络的图像分辨率大小
X-Depth:通过增加ResNet每个ResBlock层数来增加网络深度
X-Width:统一的增加各卷积层的输出通道数,来增加网络的宽度
X-Bottleneck:增加每个残差模块bottleneck卷积层的输出通道数
模型扩展后的评价指标:
J指标度量网络性能,如准确率
C指标度量网络的计算量,如浮点运算次数
前向扩展:每次只改变一个参数,保持其余参数不变,逐步增加模型的计算量和模型复杂度
后向压缩:如果模型正向扩展之后的计算量超过了限制,则反向压缩再次对扩展的参数进行修正以降低模型的计算量
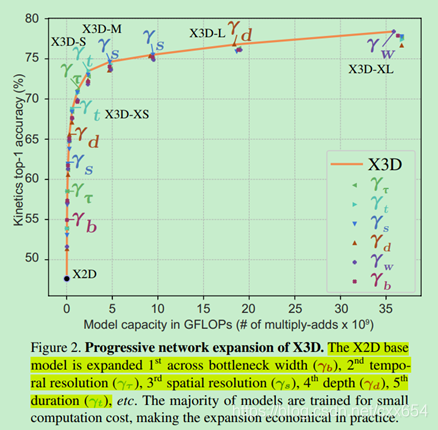

扩展网络参数实验结果:
1、扩展任何维度和X2D对比都能带来性能的提升
2、首先带来性能提升的并不是直觉上以为的temporal时间维度,而是扩展ResBlock残差模块的输出通道数带来的提升更大
3、之后才是扩展输入网络的帧数,也就是扩展时间维度大小带来的提升更大
4、然后是扩展输入网络的图像分辨率大小
5、X3D和SlowFast网络的Fast分支类似,采用了更高的时间维度分辨率(输入的时间维度大小)和更低的网络宽度(输出通道数)




























还没有评论,来说两句吧...