GC算法实现
在了解了上一章中GC算法的基本概念之后,本章将深入到各GC算法的具体实现中。对大多数JVM来说,一般需要选择两种GC算法,一种用于回收新生代内存区,另一种用于回收老年代内存区域。
新生代和老年代GC算法的可能组合如下表所示,如果不指定的话,将会在新生代和老年代中选择默认的GC算法。下表中的GC算法组合是基于Java 8的,在其他Java版本中可能会有所不同。
| 新生代GC算法 | 老年代GC算法 | JVM参数 |
|---|---|---|
| Incremental | Incremental | -Xincgc |
| Serial | Serial | -XX:+UseSerialGC |
| Parallel Scavenge | Serial | -XX:+UseParallelGC -XX:+UseParallelOldGC |
| Parallel New | Serial | N/A |
| Serial | Parallel Old | N/A |
| Parallel Scavenge | Parallel Old | -XX:+UseParallelGC -XX:+UseParallelOldGC |
| Parallel New | Parallel Old | N/A |
| Serial | CMS | -XX:+UseParNewGC -XX:+UseConcMarkSweepGC |
| Parallel Scavenge | CMS | N/A |
| Parallel New | CMS | -XX:+UseParNewGC -XX:+UseConcMarkSweepGC |
| G1 | -XX:+UseG1GC |
如果现在觉得上表看起来觉得很复杂,请别着急。一般常用的是上面加粗的四种组合。剩下的组合一般是已经不用了,或者是不再支持,或者在实际中基本不使用。所以,在接下来的文章中,只介绍上面这四种组合。
- 新生代和老年代的串行GC(Serial GC)
- 新生代和老年代的并行GC(Parallel GC)
- 新生代并行GC(Parallel GC) + 老年代CMS
- 部分新生代老年代的G1
一、串行GC(Serial GC)
串行GC对于新生代使用标记复制(mark-copy)策略,对老年代使用标记清除整理(mark-sweep-compact)策略进行垃圾回收。这些收集器是单线程的,不能并发的对垃圾进行回收。并且在垃圾回收动作时会暂停整个应用线程(stop-the-world)。
这种GC算法无法充分利用硬件资源,即使有多个核,在GC时也只用其中一个。在新生代和老年代启动串行GC的命令如下:
java -XX:+UseSerialGC com.mypackages.MyExecutableClass
这种GC算法一般并不常用,只有在堆内存为几百MB,并且应用运行在单核CPU上时才使用。一般应用都部署在多核的服务器上,如果使用串行GC会在GC时无法充分利用资源,造成性能瓶颈,提高应用延迟和降低吞吐量。
接下来我们看一个串行GC的垃圾收集日志信息,使用如下命令使应用打印出GC日志,
-XX:+PringGCDetails -XX:+PringGCDateStamps -XX:+PringGCTimeStamps
输出日志如下,
2015-05-26T14:45:37.987-0200: 151.126: [GC (Allocation Failure) 151.126: [DefNew:629119K->69888K(629120K), 0.0584157 secs] 1619346K->1273247K(2027264K), 0.0585007 secs][Times: user=0.06 sys=0.00, real=0.06 secs]2015-05-26T14:45:59.690-0200: 172.829: [GC (Allocation Failure) 172.829: [DefNew:629120K->629120K(629120K), 0.0000372 secs]172.829: [Tenured: 1203359K->755802K(1398144K), 0.1855567 secs] 1832479K->755802K(2027264K), [Metaspace:6741K->6741K(1056768K)], 0.1856954 secs] [Times: user=0.18 sys=0.00, real=0.18 secs]
从上面这段日志信息中可以看到进行了两次GC,第一次清理了新生代,第二次清理了新生代和老年代空间。
1、Minor GC
清理新生代内存的GC事件日志如下,
2015-05-26T14:45:37.987-020011 : 151.126222 : [ GC33 (Allocation Failure44 151.126: [DefNew55 : 629119K->69888K66 (629120K)77> , 0.0584157 secs] 1619346K-1273247K88 (2027264K)99, 0.0585007> secs1010] [Times: user=0.06 sys=0.00, real=0.06 secs]1111
对照上面的不同字段进行说明,
(1)2015-05-26T14:45:37.987-0200,发生本次GC动作的时间
(2)151.126,GC事件发生时距离该JVM启动的时间,单位为秒
(3)GC,用于区分是Minor GC还是Full GC。这里表示本次是Minor GC
(4)Allocation Failure,导致本次进行GC的原因。在这里,本次GC是由于无法为新的数据结构在新生代中分配内存空间导致的。
(5)DefNew,垃圾收集器的名称。这个名称表示的是在新生代中进行的单线程,标记-复制,全应用暂停的垃圾收集器
(6)629119K->69888K,表示新生代内存空间在GC前后的大小。
(7)629120K,表示新生代的总大小
(8)1619346K->1273247K,堆内存在GC前后的大小
(9)2027264K,堆内存中可用大小
(10)0.0585007 secs,GC动作的时间,单位为秒
(11)Times: user=0.06 sys=0.00, real=0.06 secs,GC动作的时间,其中
user- 表示在此次垃圾回收过程中,所有GC线程消耗的CPU时间之和sys- 表示GC过程中操作系统调用和系统等等事件所消耗的时间real- 应用暂停的总时间。由于串行GC是单线程的,所以暂停总时间等于user时间和sys时间之和
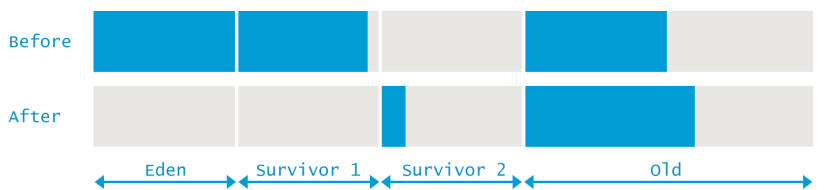
经过上面这些分析后,我们可以更加清楚的从GC日志中获取到当时的详细信息。在GC前,总共使用了1619346K堆内存,其中新生代使用了629119K。通过计算就可以得到老年代使用了990227K。GC后,新生代释放出了559231K内存空间,但是堆的总内存仅仅释放了346099K。也就是说,在本次GC时,有213132K的对象从新生代升级到了老年代区域。
下图形象的表明了本次GC前后内存的变化情况。
2、Full GC
理解了Minor GC事件后,接下来我们看一下第二次GC的日志,
2015-05-26T14:45:59.690-020011 : 172.82922 : [GC (Allocation Failure 172.829: [DefNew: 629120K->629120K(629120K), 0.0000372 secs33] 172.829:[Tenured44: 1203359K->755802K55 (1398144K)66, 0.1855567 secs77 ] 1832479K->755802K88 (2027264K)99, [Metaspace: 6741K->6741K(1056768K)]1010[Times: user=0.18 sys=0.00, real=0.18 secs]1111
对上面各组数据进行分析,
(1)2015-05-26T14:45:59.690-0200,本次GC事件发生的时间
(2)172.829,GC时JVM的启动总时间,单位为秒。
(3)[DefNew: 629120K->629120K(629120K), 0.0000372 secs,由于分配内存不足导致的一次新生代GC。在本次GC时,首先进行的是新生代的DefNew类型GC,将新生代的内存使用从629120K降低到0。注意在这里,JVM的显示有问题,误认为年轻代内存使用完了。本次GC耗时0.0000372秒
(4)Tenured,老年代垃圾收集器的名称。Tenured表示一个单线程,暂停整个应用线程的标记清除整理的垃圾收集过程。
(5)1203359K->755802K,老年代在垃圾回收前后的内存使用情况
(6)1398144K,老年代总内存数
(7)0.1855567 secs,老年代垃圾回收的耗时
(8)1832479K->755802K,垃圾回收前后总堆内存的变化情况(包括新生代和老年代)
(9)2027264K,JVM堆的可用内存
(10)[Metaspace: 6741K->6741K(1056768K)],元数据区在垃圾回收前后的内存使用情况,从这里可以看出,本次GC时并没有对元数据区的内存进行回收
(11)[Times: user=0.18 sys=0.00, real=0.18 secs],GC事件的耗时,
user- 表示在此次垃圾回收过程中,所有GC线程消耗的CPU时间之和sys- 表示GC过程中操作系统调用和系统等等事件所消耗的时间real- 应用暂停的总时间。由于串行GC是单线程的,所以暂停总时间等于user时间和sys时间之和
本次Full GC与上面的Minor GC区别十分明显,Full GC是会对老年代和元数据区进行垃圾回收的。本次垃圾回收的过程如下图所示,

二、并行GC(Parallel GC)
在这种GC模式下,新生代使用标记复制策略,老年代使用标记清除整理策略。新生代和老年代的GC事件都会导致所有应用线程暂停。新生代和老年代在复制(copy)或整理(compact)阶段都使用多线程,这也是并行GC名称的来由。使用这种GC算法,可以降低垃圾回收的时间消耗。
在垃圾回收时的并行线程数,可以由参数-XX:+ParallelGCThreads=NNN来设置。该参数的默认值是服务器的核数。
使用并行GC,可以用以下三种命令模式:
java -XX:+UseParallelGC com.mypackages.MyExecutableClassjava -XX:+UseParallelOldGC com.mypackages.MyExecutableClassjava -XX:+UseParallelGC -XX:+UseParallelOldGC com.mypackages.MyExecutableClass
并行垃圾收集器一般用在多核服务器上,在多核服务器上使用并行GC,能重复利用硬件资源,提高应用的吞吐量,
- 在垃圾收集过程中,会利用所有的核并行进行垃圾回收动作,降低应用暂停时间
- 在垃圾回收间歇期,垃圾收集器不工作,不会消耗系统资源
另一方面,并行GC的所有阶段都不能被中断,所以这些垃圾收集器仍然有可能在所有应用线程停止时陷入长时间的暂停中。所以,如果要求系统低延迟,那么不建议使用这种垃圾收集器。
接下来,我们看一下并行GC时的日志信息。如下所示,
2015-05-26T14:27:40.915-0200: 116.115: [GC (Allocation Failure) [PSYoungGen: 2694440K->1305132K(2796544K)] 9556775K->8438926K(11185152K), 0.2406675 secs] [Times: user=1.77sys=0.01, real=0.24 secs]2015-05-26T14:27:41.155-0200: 116.356: [Full GC (Ergonomics) [PSYoungGen: 1305132K->0K(2796544K)] [ParOldGen: 7133794K->6597672K(8388608K)] 8438926K->6597672K(11185152K),[Metaspace: 6745K->6745K(1056768K)], 0.9158801 secs] [Times: user=4.49 sys=0.64,real=0.92 secs]
1、Minor GC
接下来详细分析Minor GC时的日志信息。
2015-05-26T14:27:40.915-020011: 116.11522: [GC33 (Allocation Failure44) [PSYoungGen55: 2694440K->1305132K66(2796544K)77] 9556775K->8438926K88(11185152K)99, 0.2406675 secs1010] [Times: user=1.77 sys=0.01, real=0.24 secs]1111
(1)2015-05-26T14:27:40.915-0200,本次GC事件发生的时间
(2)116.115,GC时JVM的启动总时间,单位为秒。
(3)GC,用于区分Minor GC和Full GC。这里表示本次为Minor GC
(4)Allocation Failure,导致本次GC的原因。是由于新生代中无法为新对象分配内存
(5)PSYoungGen,垃圾收集器的名称,这里表示这是一个并行标记复制,暂停全部应用的新生代垃圾收集器
(6)2694440K->1305132K,GC前后新生代的内存空间使用量
(7)2796544K,新生代总内存量
(8)9556775K->8438926K,垃圾回收前后总堆内存的变化情况(包括新生代和老年代)
(9)11185152K,JVM堆的可用内存
(10)0.2406675 secs,GC事件的耗时
(11)[Times: user=1.77 sys=0.01, real=0.24 secs],GC事件的耗时,
user- 表示在此次垃圾回收过程中,所有GC线程消耗的CPU时间之和sys- 表示GC过程中操作系统调用和系统等等事件所消耗的时间real- 应用暂停的总时间。在并行GC中,这个数值应该接近于(user + sys) / GC线程数。即单个核上平均的暂停时间,在这里线程数为8。由于某些过程是不能并行执行的,所以这个值会比刚才求的均值略高。总结一下本次GC过程就是,在GC前整个堆内存使用了9556775K,其中新生代使用了2694440K,那么老年代使用了6862335K。新生代的GC导致新生代释放了1389308K的空间,但是堆的总空间只释放了1117849K。这意味着有271459K的对象从新生代升级到了老年代中,整个过程如下图所示,
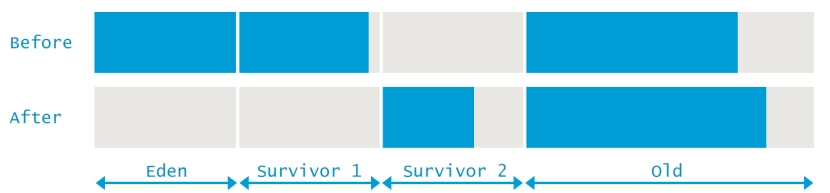
2、Full GC
在理解了新生代的并行GC过程后,我们接下来分析一些并行GC在Full GC时的表现,
2015-05-26T14:27:41.155-020011: 116.35622: [Full GC33 (Ergonomics44) [PSYoungGen: 1305132K->0K(2796544K)]55 [ParOldGen66: 7133794K->6597672K77(8388608K)88] 8438926K->6597672K99(11185152K)1010,[Metaspace: 6745K->6745K(1056768K)]1111, 0.9158801 secs1212] [Times: user=4.49 sys=0.64,real=0.92 secs]1313
(1)2015-05-26T14:27:41.155-0200,本次GC事件发生的时间
(2)116.356,GC时JVM的启动总时间,单位为秒。
(3)Full GC,表示本次是一次Full GC,将会对新生代和老年代的内存空间进行回收
(4)Ergonomics,本次GC的触发原因。这里是由于JVM认为此刻是一次适合进行垃圾回收的时间
(5)[PSYoungGen: 1305132K->0K(2796544K)],垃圾收集器的名称。PSYoungGen表示这是一次新生代中进行的标记复制,暂停全部应用的新生代GC。新生代的内存空间使用量从1305132K降低到0。一般来说,进行了一次Full GC后,新生代的内存空间将会被全部清理。
(6)ParOldGen,老年代中的垃圾收集器类型。在这里ParOldGen表示在老年代中使用的标记清除整理,暂停全部应用的老年代垃圾收集器。
(7)133794K->6597672K,老年代垃圾回收前后的内存使用情况
(8)8388608K,老年代的总内存大小
(9)8438926K->6597672K,垃圾回收前后总堆内存的变化情况(包括新生代和老年代)
(10)11185152K,JVM堆的总内存
(11)[Metaspace: 6745K->6745K(1056768K)],元数据区在垃圾回收前后的内存使用情况,从这里可以看出,本次GC时并没有对元数据区的内存进行回收
(12)0.9158801 secs,本次GC的耗时,单位为秒
(13)[Times: user=4.49 sys=0.64,real=0.92 secs],GC事件的耗时,
user- 表示在此次垃圾回收过程中,所有GC线程消耗的CPU时间之和sys- 表示GC过程中操作系统调用和系统等等事件所消耗的时间real- 应用暂停的总时间。在并行GC中,这个数值应该接近于(user + sys) / GC线程数。即单个核上平均的暂停时间,在这里线程数为8。由于某些过程是不能并行执行的,所以这个值会比刚才求的均值略高。
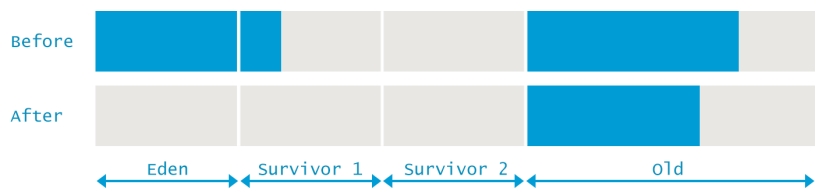
并行GC过程中的Full GC也与Minor GC有些不同。Full GC不仅会对新生代进行垃圾回收,也会清理老年代和元数据区。在Full GC前后,JVM各区内存变化情况如下图所示,
三、并发标记清除CMS(Concurrent Mark and Sweep)
CMS垃圾收集器在新生代使用stop-the-world的并行标记复制算法,在老年代使用并发的标记清除算法。
这种收集器可以避免在回收老年代空间时出现的长时间暂停。这主要是由于:(1)不对老年代的空间进行整理,而是使用一个空闲列表(free-lists)来管理这些被回收的空间。(2)标记清除阶段与应用并行进行。这意味着CMS垃圾收集器在回收老年代空间时完全不会停止应用线程,并且使用多线程来完成这些操作。默认情况下,并发线程数为当前机器物理核的1/4。
要使用CMS垃圾收集器的话,可以使用如下参数
java -XX:+UseConcMarkSweepGC com.mypackages.MyExecutableClass
如果应用运行在多核机器上,并且对系统的延迟性能要求比较高,那么就很适合使用这种垃圾收集器。但是,由于CMS垃圾收集器在大部分时候总会有一些CPU资源正在进行GC操作,所以势必会降低系统的吞吐量。
接下来我们看一些CMS在垃圾回收时生成的日志信息,
2015-05-26T16:23:07.219-0200: 64.322: [GC (Allocation Failure) 64.322: [ParNew: 613404K->68068K(613440K), 0.1020465 secs] 10885349K->10880154K(12514816K), 0.1021309 secs][Times: user=0.78 sys=0.01, real=0.11 secs]2015-05-26T16:23:07.321-0200: 64.425: [GC (CMS Initial Mark) [1 CMS-initial-mark:10812086K(11901376K)] 10887844K(12514816K), 0.0001997 secs] [Times: user=0.00 sys=0.00,real=0.00 secs]2015-05-26T16:23:07.321-0200: 64.425: [CMS-concurrent-mark-start]2015-05-26T16:23:07.357-0200: 64.460: [CMS-concurrent-mark: 0.035/0.035 secs] [Times:user=0.07 sys=0.00, real=0.03 secs]2015-05-26T16:23:07.357-0200: 64.460: [CMS-concurrent-preclean-start]2015-05-26T16:23:07.373-0200: 64.476: [CMS-concurrent-preclean: 0.016/0.016 secs][Times: user=0.02 sys=0.00, real=0.02 secs]2015-05-26T16:23:07.373-0200: 64.476: [CMS-concurrent-abortable-preclean-start]2015-05-26T16:23:08.446-0200: 65.550: [CMS-concurrent-abortable-preclean: 0.167/1.074secs] [Times: user=0.20 sys=0.00, real=1.07 secs]2015-05-26T16:23:08.447-0200: 65.550: [GC (CMS Final Remark) [YG occupancy: 387920 K(613440 K)]65.550: [Rescan (parallel) , 0.0085125 secs]65.559: [weak refs processing,0.0000243 secs]65.559: [class unloading, 0.0013120 secs]65.560: [scrub symbol table,0.0008345 secs]65.561: [scrub string table, 0.0001759 secs][1 CMS-remark:10812086K(11901376K)] 11200006K(12514816K), 0.0110730 secs] [Times: user=0.06 sys=0.00,real=0.01 secs]2015-05-26T16:23:08.458-0200: 65.561: [CMS-concurrent-sweep-start]2015-05-26T16:23:08.485-0200: 65.588: [CMS-concurrent-sweep: 0.027/0.027 secs] [Times:user=0.03 sys=0.00, real=0.03 secs]2015-05-26T16:23:08.485-0200: 65.589: [CMS-concurrent-reset-start]2015-05-26T16:23:08.497-0200: 65.601: [CMS-concurrent-reset: 0.012/0.012 secs] [Times:user=0.01 sys=0.00, real=0.01 secs]
1、Minor GC
在上面的GC日志中,最前面就能看到一次回收新生代空间的Minor GC,接下来我们详细分析一些这段GC日志的每一部分具体含义
2015-05-26T16:23:07.219-020011: 64.32222: [GC33 (Allocation Failure44) 64.322: [ParNew55: 613404K->68068K66(613440K)77, 0.1020465 secs88] 10885349K->10880154K99(12514816K)1010, 0.1021309 secs1111][Times: user=0.78 sys=0.01, real=0.11 secs]1212
(1)2015-05-26T16:23:07.219-0200,本次GC事件发生的时间
(2)64.322,GC时JVM的启动总时间,单位为秒
(3)GC,区分Minor GC和Full GC的标识,在这里表示这是一次Minor GC
(4)Allocation Failure,本次GC的触发原因。在这里是由于新生代无法为新生成的对象分配内存空间
(5)ParNew,垃圾收集器的名称。在这里表示这是一次在新生代中进行的并行标记复制,stop-the-world的垃圾回收。一般与老年代中的并发标记清除垃圾收集器配合使用。
(6)613404K->68068K,新生代垃圾回收前后的内存使用情况
(7)613440K,新生代的总内存大小
(8)0.1020465 secs,在W/O final cleanup阶段的总耗时
(9)10885349K->10880154K,垃圾回收前后总堆内存的变化情况(包括新生代和老年代)
(10)12514816K,JVM堆的总内存
(11)0.1021309 secs,新生代垃圾回收过程中在标记和复制存活对象阶段的耗时。包括与ConcurrentMarkSweep收集器的通信消耗,提升足够老的对象到老年代,以及最终在垃圾收集周期中对不再使用对象进行清理的耗时
(13)[Times: user=0.78 sys=0.01, real=0.11 secs],GC事件的耗时,
user- 表示在此次垃圾回收过程中,所有GC线程消耗的CPU时间之和sys- 表示GC过程中操作系统调用和系统等等事件所消耗的时间real- 应用暂停的总时间。在并行GC中,这个数值应该接近于(user + sys) / GC线程数。即单个核上平均的暂停时间,在这里线程数为8。由于某些过程是不能并行执行的,所以这个值会比刚才求的均值略高。从上面的分析过程中可以看出,在本次垃圾回收前,堆内存总共使用了10885349K,其中新生代使用了613404K,那么老年代使用了10271945K。垃圾收集后,新生代空间的使用量减少了545336K,但是整个堆内存空间使用量仅仅减少了5195K。也就是说,在新生代中有540141K的由于存活时间太长,被移动到老年代空间中。
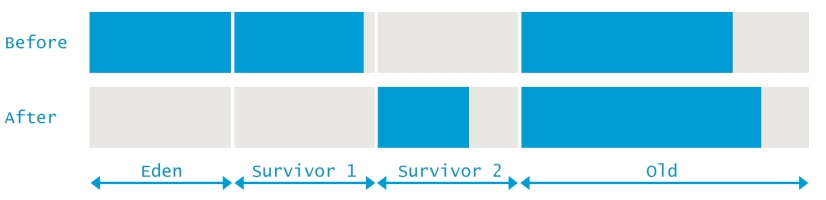
2、Full GC
接下来要分析的Full GC的日志,与前面看到的日志不同。CMS的Full GC日志信息由老年代中并发执行的不同垃圾回收阶段组成。
2015-05-26T16:23:07.321-0200: 64.425: [GC (CMS Initial Mark) [1 CMS-initial-mark:10812086K(11901376K)] 10887844K(12514816K), 0.0001997 secs] [Times: user=0.00 sys=0.00,real=0.00 secs]2015-05-26T16:23:07.321-0200: 64.425: [CMS-concurrent-mark-start]2015-05-26T16:23:07.357-0200: 64.460: [CMS-concurrent-mark: 0.035/0.035 secs] [Times:user=0.07 sys=0.00, real=0.03 secs]2015-05-26T16:23:07.357-0200: 64.460: [CMS-concurrent-preclean-start]2015-05-26T16:23:07.373-0200: 64.476: [CMS-concurrent-preclean: 0.016/0.016 secs][Times: user=0.02 sys=0.00, real=0.02 secs]2015-05-26T16:23:07.373-0200: 64.476: [CMS-concurrent-abortable-preclean-start]2015-05-26T16:23:08.446-0200: 65.550: [CMS-concurrent-abortable-preclean: 0.167/1.074secs] [Times: user=0.20 sys=0.00, real=1.07 secs]2015-05-26T16:23:08.447-0200: 65.550: [GC (CMS Final Remark) [YG occupancy: 387920 K(613440 K)]65.550: [Rescan (parallel) , 0.0085125 secs]65.559: [weak refs processing,0.0000243 secs]65.559: [class unloading, 0.0013120 secs]65.560: [scrub symbol table,0.0008345 secs]65.561: [scrub string table, 0.0001759 secs][1 CMS-remark:10812086K(11901376K)] 11200006K(12514816K), 0.0110730 secs] [Times: user=0.06 sys=0.00,real=0.01 secs]2015-05-26T16:23:08.458-0200: 65.561: [CMS-concurrent-sweep-start]2015-05-26T16:23:08.485-0200: 65.588: [CMS-concurrent-sweep: 0.027/0.027 secs] [Times:user=0.03 sys=0.00, real=0.03 secs]2015-05-26T16:23:08.485-0200: 65.589: [CMS-concurrent-reset-start]2015-05-26T16:23:08.497-0200: 65.601: [CMS-concurrent-reset: 0.012/0.012 secs] [Times:user=0.01 sys=0.00, real=0.01 secs]
接下来会分阶段对这些日志信息进行详细的分析。
阶段一:初始标记(Initial Mark)
这一步是CMS垃圾收集过程中两次stop-the-world的其中一次。目的是找到垃圾收集器的roots对象。
2015-05-26T16:23:07.321-0200: 64.425$^1$: [GC (CMS Initial Mark$^2$) [1 CMS-initial-mark:10812086K$^3$(11901376K)$^4$] 10887844K$^5$(12514816K)$^6$, 0.0001997 secs] [Times: user=0.00 sys=0.00,real=0.00 secs]$^7$
(1)2015-05-26T16:23:07.321-0200: 64.425,GC事件的开始时间,最后面的数字表示该JVM的启动时间。后续日志信息中这个时间串都表示相同含义。
(2)CMS Initial Mark,标识本次垃圾收集的阶段。initial mark阶段的目的是找到垃圾收集器的roots对象。
(3)10812086K,当前使用的老年代内存空间
(4)11901376K,当前老年代可用内存空间
(5)10887844K,当前使用的整个堆内存空间
(6)12514816K,当前堆可用空间
(7)0.0001997 secs] [Times: user=0.00 sys=0.00,real=0.00 secs],初始标记阶段的耗时,也由user,sys和real三部分组成。
阶段二:并发标记(Concurrent Mark)
这个阶段垃圾收集器将会遍历老年代中的所有对象,然后标记其中哪些对象仍然存活。判断对象是否存活将参考当前对象是否直接或间接的被上一阶段中找出的Roots对象所引用。这一阶段的动作将与应用线程并行进行。
2015-05-26T16:23:07.321-0200: 64.425: [CMS-concurrent-mark-start]2015-05-26T16:23:07.357-0200: 64.460: [CMS-concurrent-mark$^1$: 0.035/0.035 secs$^2$] [Times:user=0.07 sys=0.00, real=0.03 secs]$^3$
(1)CMS-concurrent-mark,CMS垃圾收集器的并发标记阶段。遍历老年代中所有对象,标记其中存活的对象,这一阶段并发执行,并且不会stop-the-world
(2)0.035/0.035 secs,这一阶段的持续时间,分别是运行时间和相应的实际时间
(3)[Times:user=0.07 sys=0.00, real=0.03 secs],记录了并发标记阶段从开始到结束的总时间。在并发标记阶段,这段信息没什么参考价值,因为这段时间内不仅并发标记在进行,程序也在并行运行。
阶段三:并发预清理(Concurrent Preclean)
这一阶段也是一个并发阶段,与应用线程并发运行,不会将应用线程暂停。当阶段二在并发标记时,随着应用的运行,也可能会改变某些对象的引用状况。比如标记为存活的对象,或许已经被遗弃,比如被遗弃的对象又被重新使用等。这些引用状况发生变化的对象将被JVM标记为drity(即所谓的Card Marking)。在并发预清理阶段,这些对象将被标记为存活,即使可能会出现将垃圾对象也标记为存活。此外, 本阶段也会执行一些必要的细节处理,并为 Final Remark 阶段做一些准备工作。
2015-05-26T16:23:07.357-0200: 64.460: [CMS-concurrent-preclean-start]2015-05-26T16:23:07.373-0200: 64.476: [CMS-concurrent-preclean$^1$: 0.016/0.016 secs$^2$][Times: user=0.02 sys=0.00, real=0.02 secs]$^3$
(1)CMS-concurrent-preclean,表示此次为并发预清理阶段,找出在阶段二中标记过之后引用状态发生变化的对象
(2)0.016/0.016 secs,本阶段的耗时
(3)[Times: user=0.02 sys=0.00, real=0.02 secs],记录了并发与清理阶段从开始到结束的总时间。在并发预处理阶段,这段信息没什么参考价值,因为这段时间内不仅并发预处理在进行,程序也在并行运行。
阶段四:并发可取消预清理(Concurrent Aboartable Preclean)
这一阶段同样不会暂停应用线程,主要用于尽可能少的减少Final Remark阶段的工作量,以减少stop-the-world的时间。这一阶段会循环重复相同的动作,直到循环次数,有用工作量,消耗的系统时间达到预定值为止。
2015-05-26T16:23:07.373-0200: 64.476: [CMS-concurrent-abortable-preclean-start]2015-05-26T16:23:08.446-0200: 65.550: [CMS-concurrent-abortable-preclean$^1$: 0.167/1.074secs$^2$] [Times: user=0.20 sys=0.00, real=1.07 secs]$^3$
(1)CMS-concurrent-abortable-preclean,表示这是并发可取消的预清理步骤
(2)0.167/1.074secs,这一阶段的耗时,运行时间和对应的实际时间。从这里看到运行时间比时间时间小很多。而通常情况下,由于有多核并行,real时间会比user时间小。但是在这里是由于垃圾回收线程等待了将近1秒钟没做任何动作,但是只消耗了0.167秒的CPU时间来进行实际操作。
(3)[Times: user=0.20 sys=0.00, real=1.07 secs],并发阶段这里的数值仍然没有多大的参考价值。
阶段五:最终标记(Final Remark)
这是CMS垃圾收集器各阶段中第二个也是最后一个stop-the-world阶段。这一阶段的目的是确定老年代中最终具体存活有哪些对象。这意味着在这一阶段需要遍历老年代区域中(包括阶段三中的dirty对象)所有能直接或间接被GC Roots对象所引用的对象。
通常CMS垃圾收集器会在新生代有足够空间的情况下尝试执行最终标记阶段。这主要是为了防止与新生代GC导致的stop-the-world事件连续发生。即尽量避开与新生代GC连续执行。
这一阶段的日志稍微复杂一些,
2015-05-26T16:23:08.447-0200: 65.550$^1$: [GC (CMS Final Remark$^2$) [YG occupancy: 387920 K(613440 K)$^3$]65.550: [Rescan (parallel), 0.0085125 secs]$^4$65.559: [weak refs processing,0.0000243 secs]65.559$^5$: [class unloading, 0.0013120 secs]65.560$^6$: [scrub symbol table,0.0008345 secs]65.561: [scrub string table, 0.0001759 secs$^7$][1 CMS-remark:10812086K(11901376K)$^8$] 11200006K(12514816K)$^9$, 0.0110730 secs$^{10}$] [Times: user=0.06 sys=0.00,real=0.01 secs]$^{11}$
(1)2015-05-26T16:23:08.447-0200: 65.550,发生本次事件的时间,以及本次事件发生时JVM的启动时间
(2)CMS Final Remark,标记本次是Final Remark阶段。这一阶段会stop-the-world,用于标记出老年代中所有存活对象
(3)YG occupancy: 387920 K(613440 K),新生代的内存使用量,以及新生代总内存量
(4)[Rescan (parallel), 0.0085125 secs],这一步将在应用暂停时并发标记出所有存活对象。在这里耗时为0.0085125秒
(5)[weak refs processing,0.0000243 secs]65.559,这里处理弱引用对象,耗时为0.0000243秒,发生在JVM启动后的第65.559秒
(6)[class unloading, 0.0013120 secs]65.560,清理未使用的类信息,并记录好耗时和发生时间
(7)scrub string table, 0.0001759 secs,清理持有class级别元数据的symbol和string表,总耗时为0.0001579秒
(8)10812086K(11901376K),老年代内存使用量和总量
(9)11200006K(12514816K),堆内存使用量和总量
(10)0.0110730 secs,本阶段的耗时
(11)[Times: user=0.06 sys=0.00,real=0.01 secs],本阶段的耗时,由user,sys和real三部分组成。
经过以上五步标记阶段后,老年代中所有存活对象都已经被标记过,接下来垃圾收集器将回收其中不再使用的对象,并清理老年代的内存空间。
阶段六:并发清除(Concurrent Sweep)
与应用线程一起并发进行,不需要stop-the-world。这一阶段的目的是清除不再使用的对象,回收这些对象占用的内存空间。
2015-05-26T16:23:08.458-0200: 65.561: [CMS-concurrent-sweep-start]2015-05-26T16:23:08.485-0200: 65.588: [CMS-concurrent-sweep$^1$: 0.027/0.027 secs$^2$] [Times:user=0.03 sys=0.00, real=0.03 secs]$^3$
(1)CMS-concurrent-sweep,标记本次是并发清除阶段,清除不再使用的对象,回收这些对象占用的空间
(2)0.027/0.027 secs,这一阶段的耗时
(3)[Times:user=0.03 sys=0.00, real=0.03 secs],这一阶段的耗时,由user,sys和real三部分组成
阶段七:并发重置(Concurrent Reset)
并发执行阶段,重置CMS算法内部使用的数据结构,为下一次垃圾回收作准备。
2015-05-26T16:23:08.485-0200: 65.589: [CMS-concurrent-reset-start]2015-05-26T16:23:08.497-0200: 65.601: [CMS-concurrent-reset$^1$: 0.012/0.012 secs$^2$] [Times:user=0.01 sys=0.00, real=0.01 secs]$^3$
(1)CMS-concurrent-reset,标识并发重置阶段。这一阶段主要用于重置CMS算法内部使用的数据结构,为下一次垃圾回收周期做准备
(2)0.012/0.012 secs,本阶段的耗时
(3)[Times:user=0.01 sys=0.00, real=0.01 secs],本阶段的耗时,由user,sys和real三部分组成
总结一下,CMS垃圾收集器尽量将大部分工作移到必须stop-the-world阶段之外并发进行,大大降低了应用暂停时间。但是CMS垃圾收集器的缺点也是很明显的,垃圾收集后在老年代中会有很多内存碎片。并且CMS垃圾收集器可能会造成不可预期的暂停,尤其是在堆内存比较大的时候。
四、G1(Garbage First)
实现G1(Garbage First,垃圾优先)垃圾收集器的主要目的是想将垃圾回收过程中导致的Stop-The-World维持在一个可控范围内,对暂停时间可预期,可配置。可以为G1收集器设置一个性能调优目标,可以要求垃圾收集器在给定的y毫秒时间内stop-the-world的暂停时间不超过x毫秒。例如,在给定1秒时间内,由于垃圾收集导致的应用暂停时间不能超过5毫秒。G1收集器会尽可能的去达到设定的调优目标,但是并不保证完全实现设定值。所以,可以称G1收集器为软实时(soft real-time)。
与其他垃圾收集器相比,G1有一些独特的设计。首先,堆空间不再被划分为连续新生代和老年代,而是将堆空间划分为一定数量(一般为2048)个小的堆区域(heap regions)。在这些堆区域中可以存储对象。每一个区域可能都是一个Eden区,Survivor区,或者是Old区。在逻辑上,G1的小堆区中所有的Eden区和Survivor区可以统称为新生代,所有Old区可以统称为老年代。如下图所示:

这种设计可以避免GC时需要同时回收整个堆空间,在每次GC时,只需要回收所有Region中的一部分小堆区即可,即所谓的回收集(collection set)。所有Young区会在每次暂停时进行回收,部分Old区也有可能在暂停时被回收,
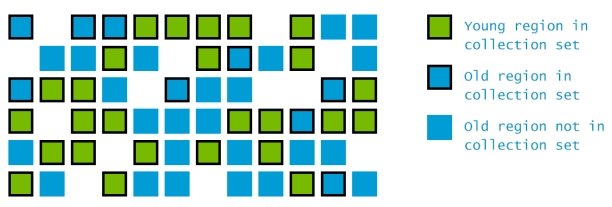
G1的另一点不同之处是,在GC的并发阶段,G1收集器会预估一下每个region中可能存活的对象有多少。那些被预估出可能包含很多垃圾的Region会被归入回收集中,优先进行收集。这也是G1收集器所谓的垃圾优先(garbage-first)的由来。
如果想要设置JVM使用G1收集器的话,使用如下参数
java -XX:+UseG1GC com.mypackages.MyExecutableClass
1、Evacuation Pause: Fully Young
在应用刚启动时,由于还没有过GC的记录,G1无法获取到任何关于GC的相关信息。所以在最开始,G1收集器会在Fully Young模式下运行。当新生代装满后,应用线程会被暂停,Young堆区中的对象会被复制到Survivor堆区,或者在还没有Survivor区时会将存活对象复制到一些空闲的堆区中,这些被选中的堆区就成为了Survivor堆区。
这一复制存活对象到Survivor堆区的过程被称为是转移过程,这一过程和前面介绍的其他新生代垃圾收集过程类似。转移过程中生成的日志文件非常大,所以,为了简单起见会从转移过程生成的日志文件中截取出一部分日志来分析这一过程。另外,由于日志记录太多,这里面涉及到的并行阶段和其他阶段的日志将会被拆分成多个部分来解析。
0.134: [GC pause (G1 Evacuation Pause) (young), 0.0144119 secs]11
[Parallel Time: 13.9 ms, GC Workers: 8]22
…33
[Code Root Fixup: 0.0 ms]44
[Code Root Purge: 0.0 ms]55
[Clear CT: 0.1 ms]
[Other: 0.4 ms]66
…77
[Eden: 24.0M(24.0M)->0.0B(13.0M)88 Survivors: 0.0B->3072.0K99 Heap: 24.0M(256.0M)->21.9M(256.0M)]1010
[Times: user=0.04 sys=0.04, real=0.02 secs]1111
(1)0.134: [GC pause (G1 Evacuation Pause) (young), 0.0144119 secs],G1垃圾收集器的转移暂停阶段。开始于JVM启动后的第134毫秒。暂停的总CPU时间为0.0144秒。
(2)[Parallel Time: 13.9 ms, GC Workers: 8],表示此次暂停的实际时间为13.9毫秒,有8个线程并行。
(3)…,这里省略的部分在后面分析
(4)[Code Root Fixup: 0.0 ms],释放用于管理并行活动的内部数据结构。耗时一般都为0。
(5)[Code Root Purge: 0.0 ms],清理更多的数据结构,这一阶段耗时也几乎为0,但并不一定为0。
(6)[Other: 0.4 ms],其他并行活动的耗时
(7)…,省略部分参考后面分析
(8)[Eden: 24.0M(24.0M)->0.0B(13.0M),Eden堆区在本阶段前后的空间使用和总空间变化
(9)Survivors: 0.0B->3072.0K,Survivor堆区在本阶段前后内存使用变化
(10)Heap: 24.0M(256.0M)->21.9M(256.0M)],堆总容量和使用量前后变化情况
(11)[Times: user=0.04 sys=0.04, real=0.02 secs],GC事件的耗时,由以下几部分组成:
- user - 垃圾收集器在本阶段的总CPU耗时
- sys - GC过程中, 系统调用和系统等待事件所消耗的时间
real - 应用暂停的真实时间。由于GC时是并行执行的,所以这个时间是由
(user时间 + sys时间) / 线程数来确定的。在这里,使用了8线程。由于并不是所有阶段都是并行执行的,所以,这个值可能比计算的稍大。除此之外,还有一些复杂的工作由几个专用的线程在执行,这部分的日志如下所示:
[Parallel Time: 13.9 ms, GC Workers: 8] 11
[GC Worker Start (ms)22: Min: 134.0, Avg: 134.1, Max: 134.1, Diff: 0.1]
[Ext Root Scanning (ms)33: Min: 0.1, Avg: 0.2, Max: 0.3, Diff: 0.2, Sum: 1.2]
[Update RS (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Processed Buffers: Min: 0, Avg: 0.0, Max: 0, Diff: 0, Sum: 0]
[Scan RS (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Code Root Scanning (ms)44: Min: 0.0, Avg: 0.0, Max: 0.2, Diff: 0.2, Sum: 0.2]
[Object Copy (ms)55: Min: 10.8, Avg: 12.1, Max: 12.6, Diff: 1.9, Sum: 96.5]
[Termination (ms)66: Min: 0.8, Avg: 1.5, Max: 2.8, Diff: 1.9, Sum: 12.2]
[Termination Attempts77: Min: 173, Avg: 293.2, Max: 362, Diff: 189, Sum: 2346]
[GC Worker Other (ms)88: Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.1]
GC Worker Total (ms)99: Min: 13.7, Avg: 13.8, Max: 13.8, Diff: 0.1, Sum: 110.2]
[GC Worker End (ms)1010: Min: 147.8, Avg: 147.8, Max: 147.8, Diff: 0.0]
(1)[Parallel Time: 13.9 ms, GC Workers: 8],表示在13.9毫秒时间内,以下活动由8个线程在并行执行
(2)GC Worker Start (ms),这8个线程开始执行的最早,最晚,以及平均时间。这里的时间是距离JVM启动的毫秒数。如果最小值和最大值相差比较多,则表示有其他线程在占用这些线程资源
(3)Ext Root Scanning (ms),遍历外部根节点的耗时。外部根节点指的是classloader,或者JNI引用,或者JVM系统等。“Sum”统计的是CPU时间
(4)Code Root Scanning (ms),遍历堆内引用的根节点的耗时
(5)Object Copy (ms),从待回收堆区复制存活对象的耗时
(6)Termination (ms),GC线程用于确认自身可以安全停止的耗时,这段时间上面也不做,停止之后该线程就终止运行了
(7)Termination Attempts,GC线程尝试停止的次数。如果尝试停止时发现还有事情没做完,或者停止时间太早,则会尝试失败
(8)GC Worker Other (ms),一些其他的不值得在GC日志中单独列出来的工作
(9)GC Worker Total (ms),GC工作线程的工作总时间
(10)GC Worker End (ms),GC线程完成停止的时间。一般来说,时间应该基本相近,否则意味着有一些GC线程被其他线程占用导致被挂起。
另外,在转移阶段还有一些其他活动的GC日志,我们再看下面这一段,
[Other: 0.4 ms]11
[Choose CSet: 0.0 ms]
[Ref Proc: 0.2 ms]22
[Ref Enq: 0.0 ms]33
[Redirty Cards: 0.1 ms]
[Humongous Register: 0.0 ms]
[Humongous Reclaim: 0.0 ms]
[Free CSet: 0.0 ms]44
(1)[Other: 0.4 ms],其他GC活动,大部分也是并行的
(2)[Ref Proc: 0.2 ms],处理非强引用的耗时。主要清除这些非强引用或者决定不需要清除这些非强引用
(3)[Ref Enq: 0.0 ms],将需要保留的非强引用移动到合适的引用队列中的耗时
(4)[Free CSet: 0.0 ms],将回收集中释放的小堆区进行回收,这样下一次分配时又可以重新使用
2、并发标记(Concurrent Marking)
G1垃圾收集器使用了很多CMS中的概念,哪怕在某些阶段的执行过程有所不同,但是其最终目的仍然是差不多的。所以如果对CMS不熟悉的话,最好先了解一下CMS的原理,再来继续研究G1收集器的执行过程。G1并发标记过程会使用Snapshot-At-The-Beginning来记录在标记开始时各对象的引用状态,这里的Snapshot会包含所有对象,哪怕那些对象此时是垃圾对象(这些垃圾对象在后续过程中有可能被重新标记为存活对象)。基于这些信息可以很方便的构造出回收集来。
这些信息接下来就会被用来对Old堆区进行垃圾回收,如果可以判断出某个堆区中全是垃圾对象,或者在stop-the-world的转移暂停阶段某些Old堆区中既包含垃圾对象又包含存活对象,那么这个过程可以并发的进行。
如果堆空间使用量超过某阈值,就会触发并发标记阶段。默认情况下这一阈值为45%。可以通过参数InitiatingHeapOccupancyPercent参数来设置。类似于CMS,G1中的并发标记过程也由若干阶段组成,其中某些阶段可以完全并发进行,某些阶段需要在应用线程暂停的情况下进行。
阶段一:初始化标记(Initial Mark)
这一阶段标记出所有可以从GC roots对象直接访问到的对象。在CMS中,这一阶段需要在stop-the-world时进行。但是G1中,这一阶段会在转移暂停阶段进行。在转移暂停阶段输出的GC日志第一行就能看到初始标记的信息,
1.631: [GC pause (G1 Evacuation Pause) (young) (initial-mark), 0.0062656 secs]
- 1
阶段二:根堆区扫描(Root Region Scan)
这一阶段会将可以从根堆区(Root Regions)访问到的对象都标记出来。所谓的根堆区是指那些非空的小堆区,以及那些在标记阶段会对它们进行回收的区域。由于在并发标记阶段移动对象可能会造成一些其他的麻烦,所以这一阶段需要在下一次转移暂停阶段开始时结束。如果转移暂停阶段需要提前开始,它会向堆根区扫描过程发送一个终止信号,然后等堆根区扫描结束就开始转移暂停阶段。目前的堆根区一般是指,在下一次转移暂停阶段会被回收的新生代区域。
1.362: [GC concurrent-root-region-scan-start]1.364: [GC concurrent-root-region-scan-end, 0.0028513 secs]
- 1
- 2
阶段三:并发标记(Concurrent Mark)
这一阶段和CMS中的并发标记阶段很类似,遍历对象图中的所有对象,并在bitmap中标记出那些课访问的对象。为了保证与snapshot-at-the-beginning中的记录一致,G1垃圾收集器会将所有应用线程中对某些对象的引用发生的变更都记录下来,以便后续跟踪。
为了达到这一目的,G1使用了一个Pre-Write机制。在G1的并发标记阶段还在进行时,每当某对象中的字段引用发生变更时,都会在log缓存中进行记录。
1.364: [GC concurrent-mark-start]1.645: [GC concurrent-mark-end, 0.2803470 secs]
阶段四:重新标记(Remark)
这个阶段和CMS中类似,也会导致stop-the-world。这个暂停过程,主要是用来将标记过程完成。但是对于G1垃圾收集器来说,只会造成一个简短的暂停。在这个简短暂停过程中,在不会有应用线程继续更新引用变更log的情况下,对这个log中记录的引用变动作处理,并且标记出那些在并发标记过程中没有标记为存活,但是在后续应用线程执行中又变成存活状态的对象。这一阶段同样也会进行一些额外的清理工作,比如对引用的处理,或者类的卸载(class unloading)
1.645: [GC remark 1.645: [Finalize Marking, 0.0009461 secs] 1.646: [GC ref-proc, 0.0000417 secs] 1.646:[Unloading, 0.0011301 secs], 0.0074056 secs] [Times: user=0.01 sys=0.00, real=0.01 secs]
阶段五:清理(Cleanup)
这一阶段主要为接下来即将要进行的对象转移阶段做准备。统计出所有小堆区中的存活对象,并且对这些小堆区按存活对象数进行排序。也为下一次标记阶段作必要的整理工作,维护并发标记的内部状态。
最终,所有不包含存活对象的小堆区在这一阶段都被回收了。对空的小堆区回收和对存活率的计算都是并发进行的。这个阶段需要在短暂的stop-the-world过程中进行,日志如下
1.652: [GC cleanup 1213M->1213M(1885M), 0.0030492 secs] [Times: user=0.01 sys=0.00, real=0.00 secs]
如果某些小堆区只包含垃圾对象,则日志格式可能会有点不同,如下所示,
1.872: [GC cleanup 1357M->173M(1996M), 0.0015664 secs] [Times: user=0.01 sys=0.00, real=0.01 secs]1.874: [GC concurrent-cleanup-start]1.876: [GC concurrent-cleanup-end, 0.0014846 secs]
3、Evacuation Pause: Mixed
如果上一步并发清除能够完全释放老年代中所有的小堆区当然是最理想的情况,但是这一状况并不经常发生。当并发标记过程顺利完成后,G1垃圾收集器会触发一个混合回收过程,这个混合回收过程不仅会回收新生代堆区的空间,也会回收老年代堆区中的垃圾对象。
混合转移暂停阶段并不经常紧接着并发标记阶段进行。混合转移暂停阶段的触发有一系列的条件。例如,如果不能保证可以释放出很大一部分Old堆区空间时,是不会轻易进行这一步的。
所以,在并发标记阶段后会进行很多次纯新生代的转移暂停,偶尔执行一次混合转移暂停。
将会添加到回收集中的Old堆区的确切数量,以及它们添加到回收集中的顺序,也是由一些条件来决定的。这些条件包括,对应用的性能要求,并发标记过程垃圾回收的效率,以及其他的JVM配置参数。混合垃圾回收的过程和前面已经分析过的纯新生代GC过程很类似,但是在这里我们再提出一个概念记录集(remembered sets,注意与collection sets进行区分)。
记录集是用来实现各堆区独立进行回收的。举例来说,当回收堆区A,B和C时,我们需要知道是否有从D区或E区指向A,B和C区的引用存在。但是,如果要遍历整个堆中的所有引用情况将会是一个极其耗时的过程。那么G1收集器针对这种情况进行了一些优化。G1中使用的记录集非常类似于其他GC算法中独立回收新生代区域的Card Table。
如下图所示,每一个堆区都有一个记录集,在记录集中记录了所有从外部过来的引用。这些引用在处理的时候会被当成另外的GC roots。注意,并发标记阶段中标出的Old堆区中的垃圾对象,即使有外部引用指向它们,在这个过程中也会直接被忽略掉,并且其实引用者也是一个垃圾对象。

接下来的过程和其他垃圾收集器也基本类似,多路GC线程并发的找出哪些对象是存活对象,哪些对象是垃圾对象。
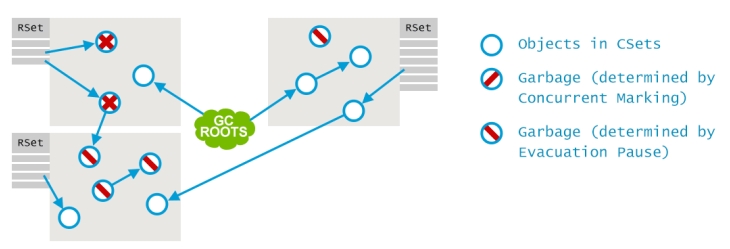
最终,这些存活的对象会被移动到survivor堆区中,如果有必要的话,也会根据需要创建survivor堆区。这一过程之后,其他堆区就被清空了,可以进行下一轮的对象分配。
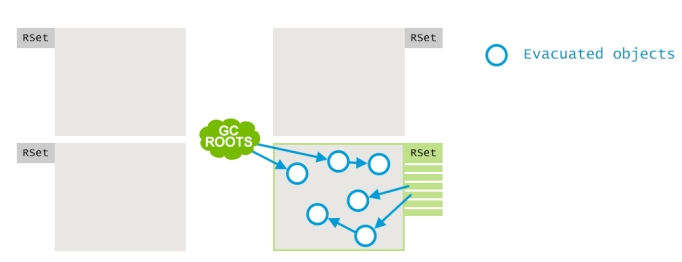
为了在应用运行阶段来维持这么一个记录集,G1垃圾收集器使用了一个Post-Write策略。如果某个对象的属性引用更新了,并且是一个跨堆区的引用,那么就会在目标堆区的记录集中记录一次这个引用。为了降低Post-Write的性能消耗,更新记录集的过程是异步进行的,并且还做了一些优化。大致上是这样的:Post-Write将脏的card信息(dirty card information)记录到一个本地buffer中,然后会有一个特定的GC线程找到这个dirty card information,并且将其记录到引用堆区的记录集中。
在混合转移过程中,输出的日志信息如下,
[Update RS (ms)11: Min: 0.7, Avg: 0.8, Max: 0.9, Diff: 0.2, Sum: 6.1]
[Processed Buffers22: Min: 0, Avg: 2.2, Max: 5, Diff: 5, Sum: 18]
[Scan RS (ms)33: Min: 0.0, Avg: 0.1, Max: 0.2, Diff: 0.2, Sum: 0.8]
[Clear CT: 0.2 ms]44
[Redirty Cards: 0.1 ms]55
(1)[Update RS (ms),由于记录集会被并发的处理,所以我们需要保证在真正进行垃圾回收前,要完成被缓存的cards都已经被处理完成。如果这个值比较高,那说明并发GC线程无法处理当前的高负荷了。这可能是由于当时出现了大量字段的引用变动,或者CPU资源不足
(2)[Processed Buffers,每个worker线程处理了多少本地buffer
(3)[Scan RS (ms),遍历记录集中记录的外部引用的耗时
(4)[Clear CT: 0.2 ms],清除card table中的cards的耗时。清除过程仅仅是移除脏状态,这个状态是用来标识一个字段是否被更新过,供记录集使用
(5)[Redirty Cards: 0.1 ms],标记card table中的dirty对象位置的耗时
4、总结
通过上面的分析,应该对G1的功能有了一定的了解。但是上面的过程分析中还是对G1的实现细节做了一些省略,比如说G1如何处理超大对象等。综合来看,G1是HotSpot JVM中最好的垃圾收集器。并且HotSopt对G1收集器一直在持续的做优化。
可以看到,G1垃圾收集器解决了CMS收集器中出现的若干问题,包括应用暂停时间的可预期以及避免了堆内存碎片等。对一个应用来说,如果对CPU资源不作限制,而主要关注其延迟性能时,非常适合使用G1垃圾收集器。然而,延迟性能的优化并不是无代价的,由于会有额外的write barriers的存在和使用更多的守护线程,G1的吞吐量会有所降低。所以,如果应用对吞吐量有很高的要求,或者CPU资源比较紧张时,CMS可能会更加适合。
在应用中如何选择合适的GC算法,最终还是得靠实践来证明。接下来一章中将会分析性能调优的一些参考。
并且,从Java 9开始,G1垃圾收集器很可能会成为默认的GC。
五、 Shenandoah
到目前为止,已经分析了HotSopt JVM中的所有可用于生产的GC算法了。这里将会简要分析另一种垃圾收集器,超低延迟垃圾收集器(Ultra-Low-Pause-Time Garbage Collector)。它的设计目标主要是用于大型多核大堆内存的服务器应用。目标是用于管理100GB的堆内存,以及要求暂停低于10毫秒的应用。实现这一目标是以牺牲吞吐量为代价的,这种几乎无暂停的GC算法的实现,要求在吞吐量上的性能降低不能超过10%。
在这种GC算法没有正式发布之前,不会对其做更深入的研究,但是可以预期到这种算法仍然会用到前面提到的一些垃圾回收的基本思想。比如说并发标记,增量收集等。但是它又有一些不同,比如说不再将堆内存划分为不同的年代而只是使用单个空间。Shenandoah并不是一个基于分代理论的垃圾收集器,这也使得它可以不使用card table和记录集了。它仍然使用forwarding pointers以及read barrier,这使得它可以对存活对象进行并发的复制,降低了GC次数和GC时间消耗。
有关更多Shenandoah的信息,可以参考博客: https://rkennke.wordpress.com/。
文章来源:https://blog.csdn.net/dabokele/article/details/60601818

























盒子模型,边框,内外边距,盒子模型布局,ps基本操作,列表样式,圆角边框,盒子阴影")








还没有评论,来说两句吧...