重磅! | Flink1.14新特性预览
欢迎加博主微信:threeknowbigdata,拉你进大数据群、Flink流计算群
大家好,我是土哥。
目前在某互联网大厂担任大数据算法工程师。
今天在查看Flink源码时,发现Flink1.14修复了很多bug,并且提了很多PR,其中完成了33个重要的新特性及优化。
Bug修复可见部分截图:

Improvement可见部分截图:

新版本预计1-2周之内会发布,下面我将带领大家查看一下 Flink1.14的新特性都有哪些?
1、流批一体优化
流批一体其实从 Flink 1.9 版本开始就受到持续的关注,它作为社区 RoadMap 的重要组成部分,是大数据实时化必然的趋势。但是另一方面,传统离线的计算需求其实并不会被实时任务完全取代,而是会长期存在。
基于这种背景下,Flink 社区认定了实时离线一体化的技术路线是比较重要的技术趋势和方向。
在Flink1.14以前,社区在流批一体方面做了很多的工作。
1.1、流批一体的痛点
重点: Flink 在引擎层面,API 层面和算子的执行层面上做到了真正的流与批用同一套机制运行。但是在任务具体的执行模式上会有 2 种不同的模式。
- 流模式: 对于源源不断的数据流,统一采用流模式,所有计算节点是通过
Pipeline模式去连接的,Pipeline 是指上游和下游计算任务是同时运行的,随着上游不断产出数据,下游同时在不断消费数据。
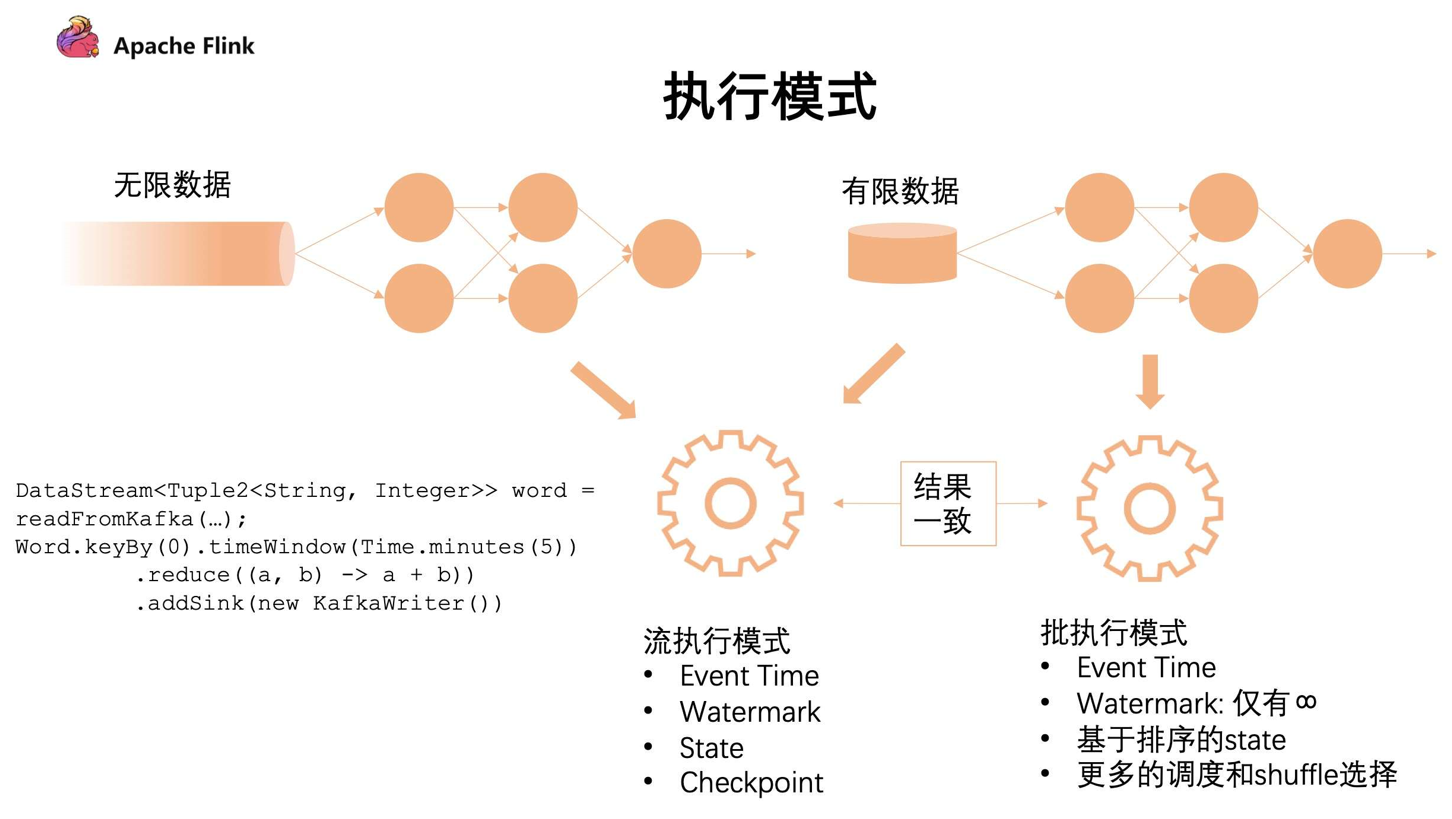
- 批模式:对于有限的数据流,可以把它当成批的执行模式。批的执行模式虽然也有
eventTime,但是对于watermark来说只支持正无穷。对数据和 state 排序后,它在任务的调度和 shuffle 上会有更多的选择。
流批的执行模式最主要的区别在于:批执行模式会有落盘的中间过程,只有当前面任务执行完成,下游的任务才会触发,这个容错机制是通过 shuffle 进行容错的。
两者的区别:
对于流的执行模式来说,它没有落盘的压力,同时容错是基于数据的分段,通过不断对数据进行打点 Checkpoint 去保证断点恢复;
对于批执行模式来说,因为要经过 shuffle 落盘,所以对磁盘会有压力。但是因为数据是经过排序的,所以对批来说,后续的计算效率可能会有一定的提升。同时,在执行时候是经过分段去执行任务的,无需同时执行。在容错计算方面是根据 stage 进行容错。
1.2、流批一体的优化
针对上述问题,Flink 1.14 的优化点主要是针对在流的执行模式下,如何去处理有限数据集。
之前处理无限数据集,和现在处理有限数据集最大的区别在于引入了 “任务可能会结束” 的概念。在这种情况下带来一些新的问题,如下图:
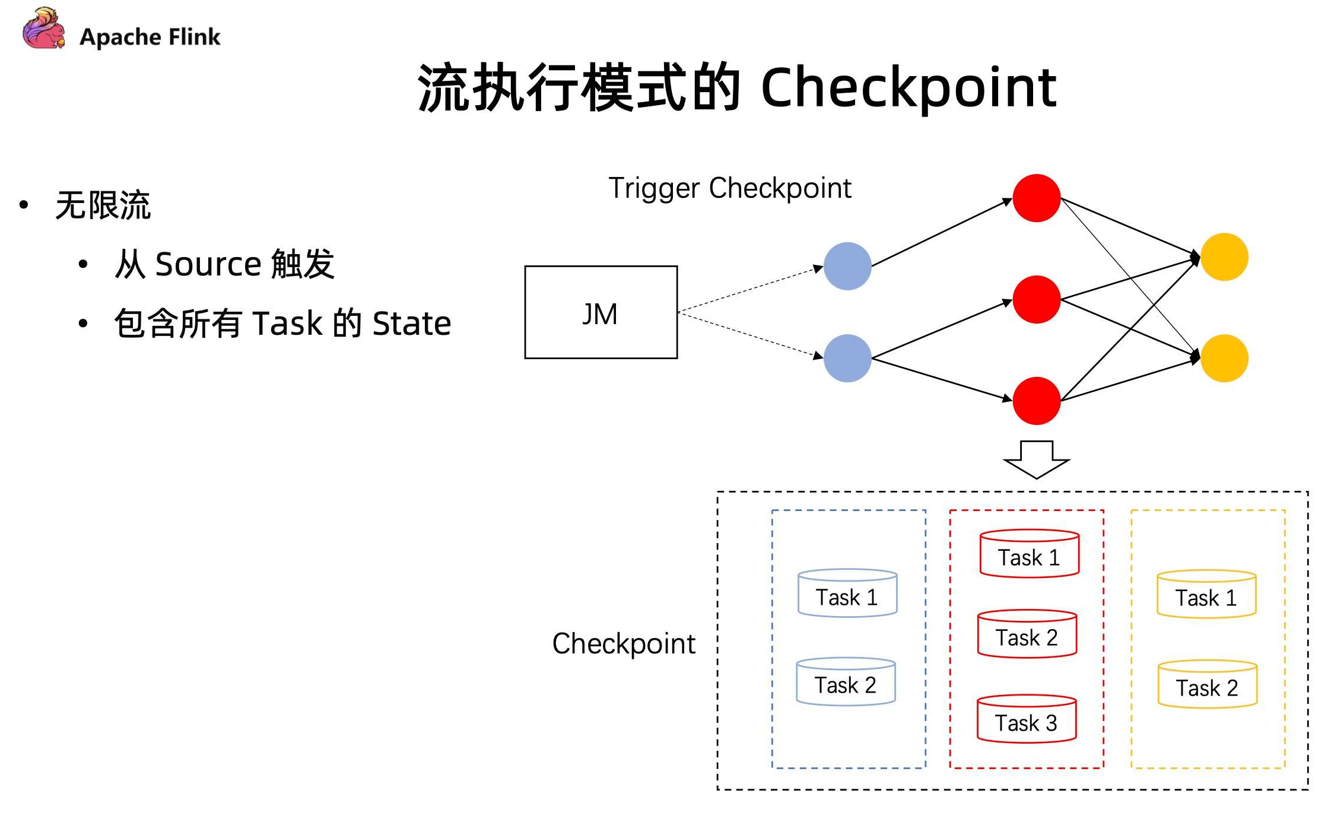
在流的执行模式下的 Checkpoint 机制
- 对于无限流,它的
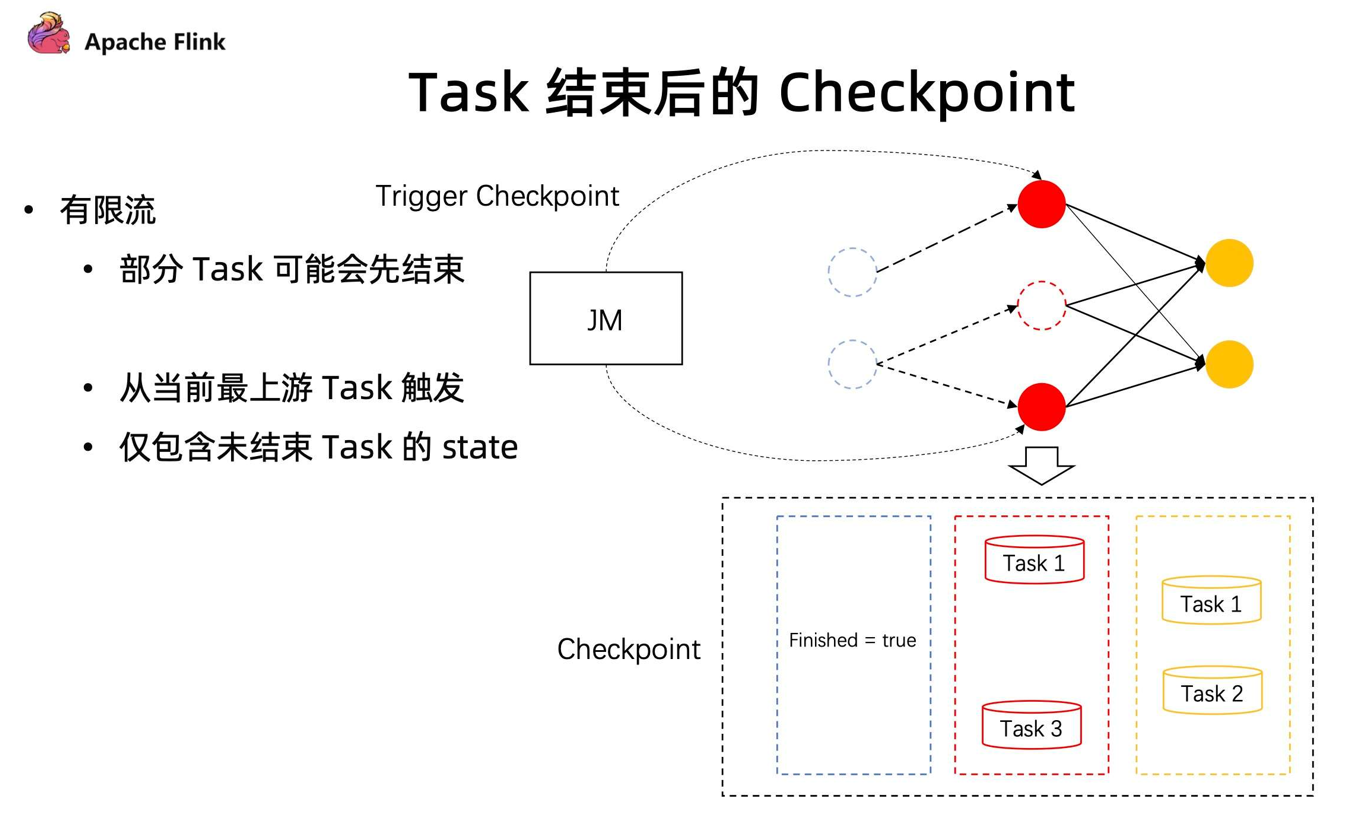
Checkpoint是由所有的 source 节点进行触发的,由 source 节点发送 Checkpoint Barrier ,当 Checkpoint Barrier 流过整个作业时候,同时会存储当前作业所有的 state 状态。 - 但在有限流的 Checkpoint 机制中,Task 是有可能提早结束的。上游的 Task 有可能先处理完任务提早退出了,但下游的 Task 却还在执行中。在同一个 stage 不同并发下,有可能因为数据量不一致导致部分任务提早完成了。
这种情况下,在后续的执行作业中,如何进行 Checkpoint?
在 1.14 中,JobManager 动态根据当前任务的执行情况,去明确 Checkpoint Barrier 是从哪里开始触发。同时在部分任务结束后,后续的 Checkpoint 只会保存仍在运行 Task 所对应的 stage,通过这种方式能够让任务执行完成后,还可以继续做 Checkpoint ,在有限流执行中提供更好的容错保障。
- Task 结束后的两阶段提交协议
我们在部分 Sink 使用上,如下图的 Kafka Sink 上,涉及到 Task 需要依靠 Checkpoint 机制,进行二阶段提交,从而保证数据的 Exactly-once 一致性。
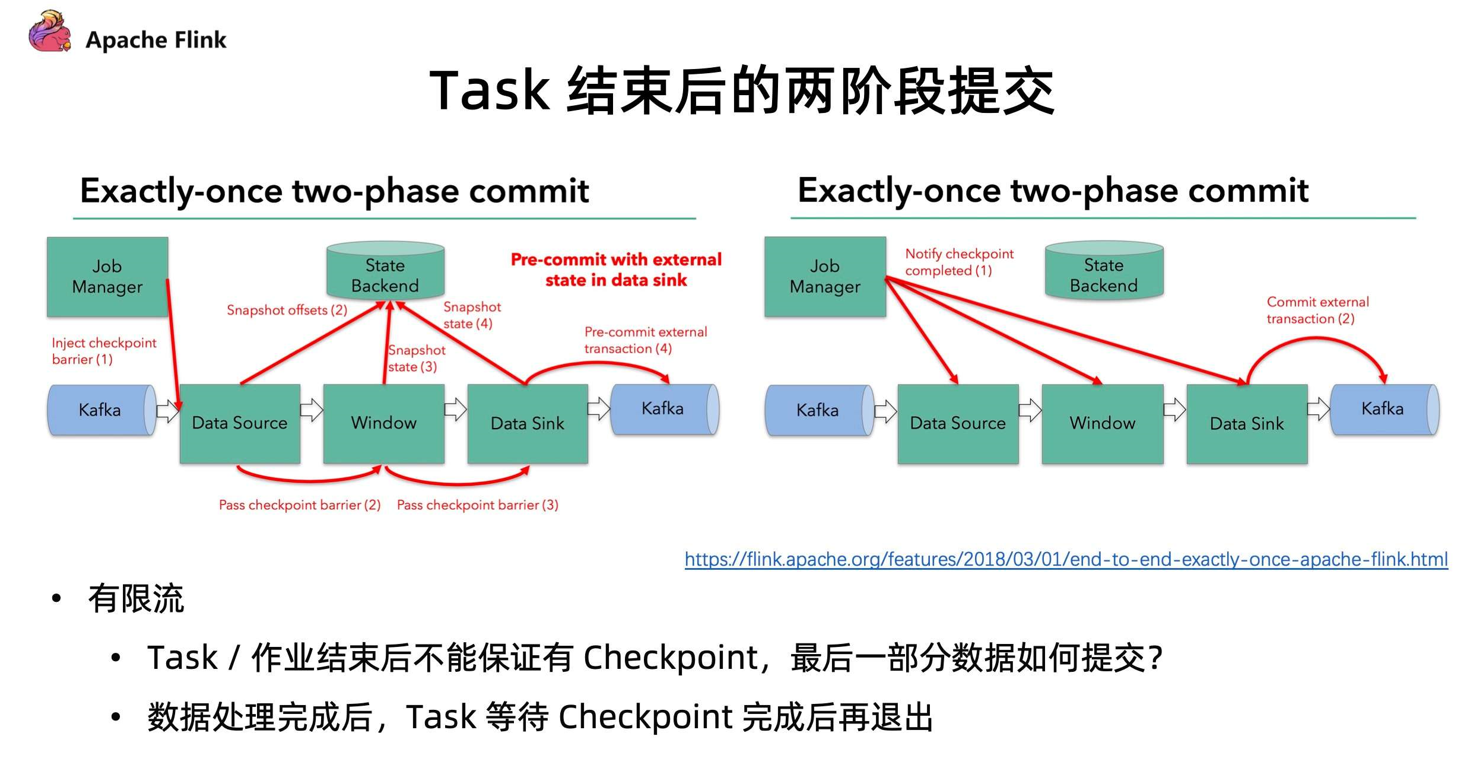
在 Checkpoint 过程中,每个算子只会进行预提交操作。比如数据会提交到外部的临时存储目录下,所有任务都完成这次 Checkpoint 后,会收到一个信号,之后才会执行正式的 commit,把所有分布式的临时文件一次性以事务的方式提交到外部系统。
这种算法在当前有限流的情况下,作业结束后并不能保证有 Checkpoint,那么最后一部分数据如何提交?
在 1.14 中,这个问题得到了解决。Task 处理完所有数据之后,必须等待 Checkpoint 完成后才可以正式的退出,这是流批一体方面针对有限流任务结束的一些改进。
2、CheckPoint优化
2.1、现有checkpoint机制痛点
目前 Flink 触发 Checkpoint 是依靠barrier 在算子间进行流通,barrier 随着算子一直往下游进行发送,当算子下游遇到 barrier 的时候就会进行快照操作,然后再把 barrier 往下游继续发送。对于多路的情况我们会把 barrier 进行对齐,把先到 barrier 的这一路数据暂时性的 block,等到两路 barrier 都到了之后再做快照,最后才会去继续往下发送 barrier。
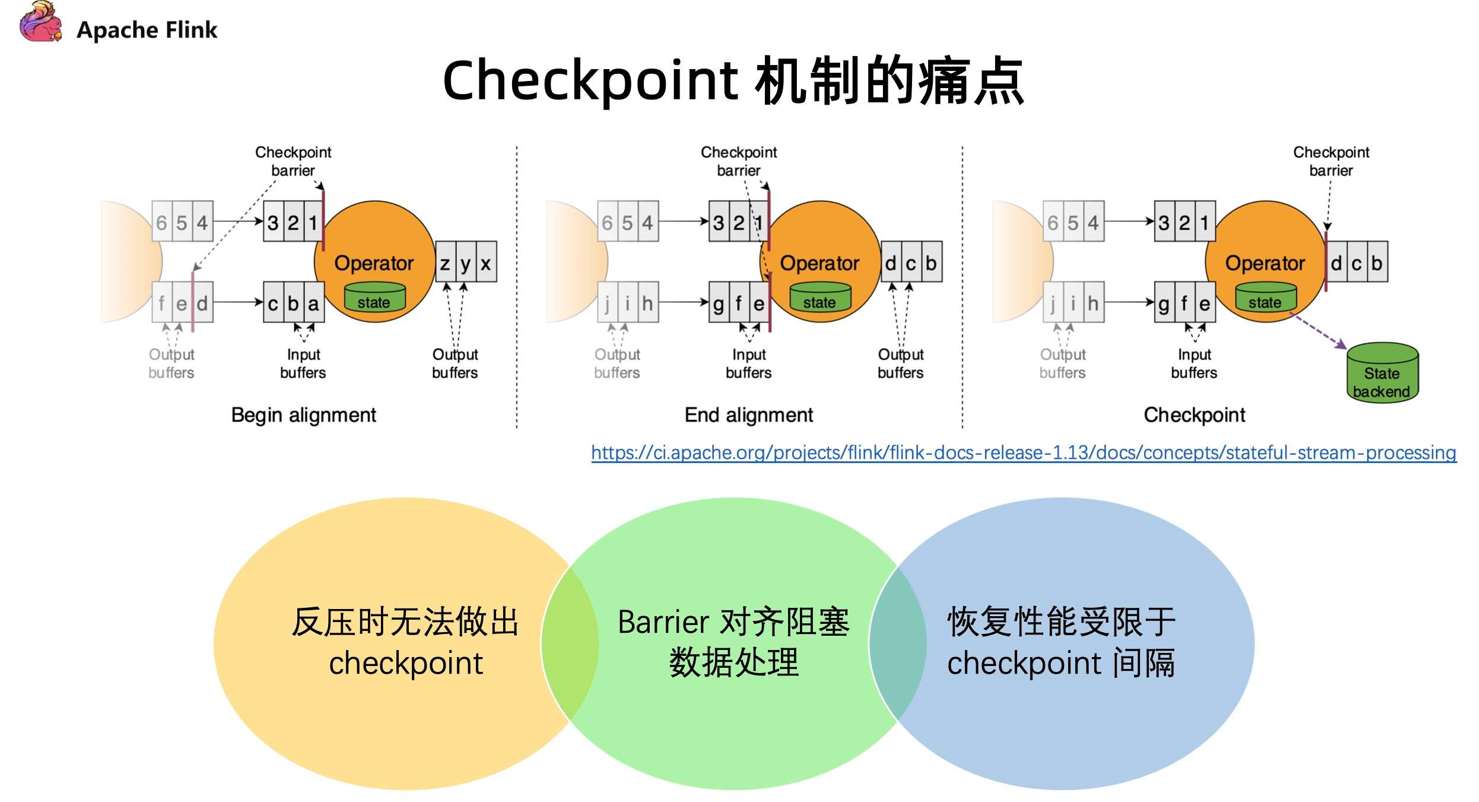
现有的 Checkpoint 机制存在以下问题:
- 反压时无法做出
Checkpoint:在反压时候barrier无法随着数据往下游流动,造成反压的时候无法做出 Checkpoint。但是其实在发生反压情况的时候,我们更加需要去做出对数据的Checkpoint,因为这个时候性能遇到了瓶颈,是更加容易出问题的阶段; - Barrier 对齐阻塞数据处理 :阻塞对齐对于性能上存在一定的影响;
- 恢复性能受限于
Checkpoint间隔 :在做恢复的时候,延迟受到多大的影响很多时候是取决于 Checkpoint 的间隔,间隔越大,需要 replay 的数据就会越多,从而造成中断的影响也就会越大。但是目前 Checkpoint 间隔受制于持久化操作的时间,所以没办法做的很快。
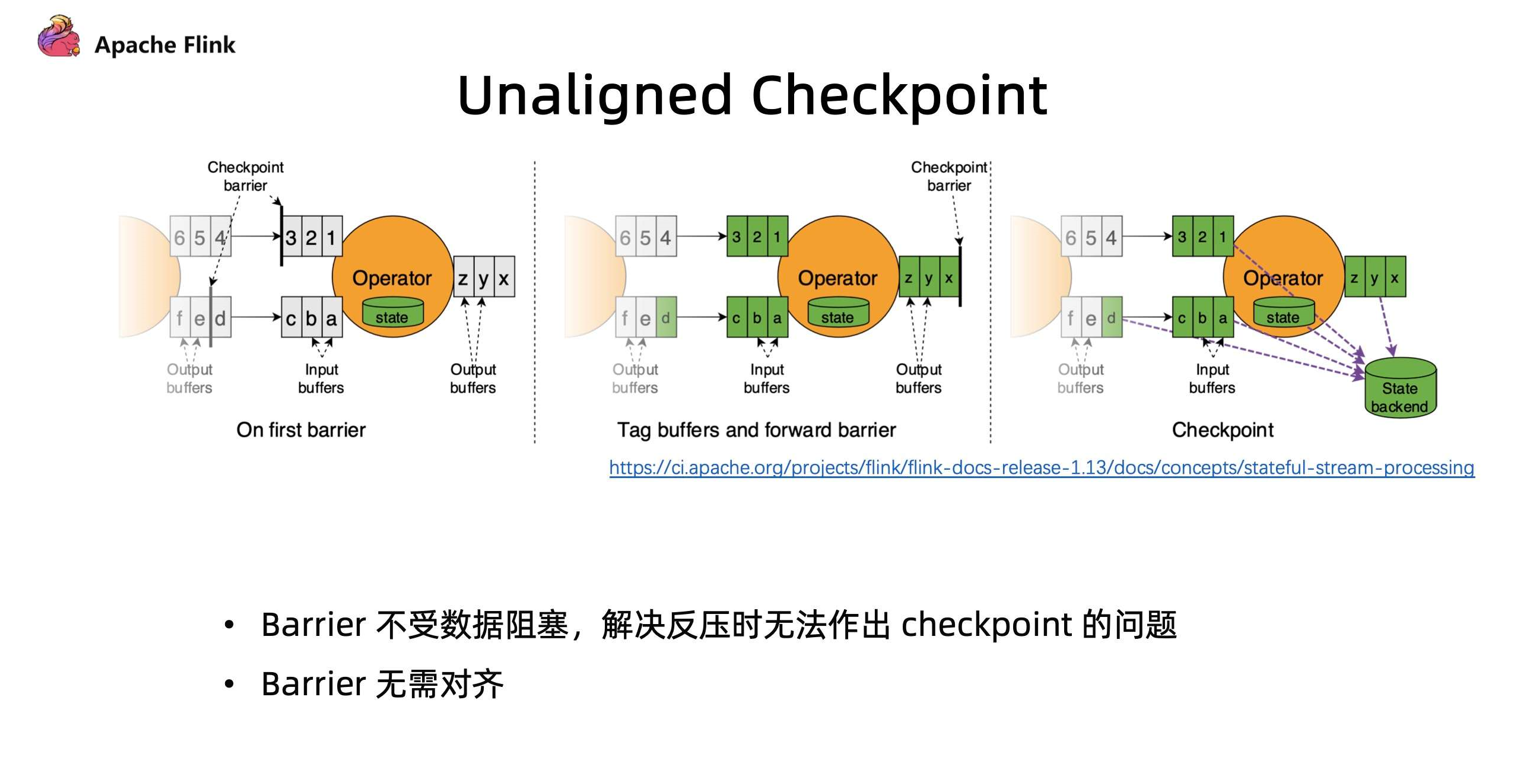
2.2、Flink1.13提出 Unaligned Checkpoint
- 针对Checkpoint痛点,Flink1.14以前就一直在持续优化,(未对齐)
Unaligned Checkpoint就是其中一个机制。barrier算子在到达 input buffer 最前面的时候,就会开始触发 Checkpoint 操作。它会立刻把 barrier 传到算子的 OutPut Buffer 的最前面,相当于它会立刻被下游的算子所读取到。通过这种方式可以使得 barrier 不受到数据阻塞,解决反压时候无法进行 Checkpoint 的问题。 - 当我们把
barrier发下去后,需要做一个短暂的暂停,暂停的时候会把算子的State和input output buffer中的数据进行一个标记,以方便后续随时准备上传。对于多路情况会一直等到另外一路 barrier 到达之前数据,全部进行标注。 - 通过这种方式做 Checkpoint 的时候,不需要对 barrier 进行对齐,
唯一需要做的停顿就是在整个过程中对所有 buffer 和 state 标注。这种方式可以很好的解决反压时无法做出 Checkpoint ,和 Barrier 对齐阻塞数据影响性能处理的问题。
2.3、Generalized Incremental Checkpoint
Flink 1.14 提出通过Generalized Incremental Checkpoint(广义增量检查点)减少 Checkpoint 间隔,
如下图所示,在 Incremental Checkpoint 当中,先让算子写入 state 的 changelog。写完后才把变化真正的数据写入到 StateTable 上。state 的 changelog 不断向外部进行持久的存储化。在这个过程中我们其实无需等待整个 StateTable 去做一个持久化操作,我们只需要保证对应的 Checkpoint 这一部分的 changelog 能够持久化完成,就可以开始做下一次 Checkpoint。StateTable 是以一个周期性的方式,独立的去对外做持续化的一个过程。
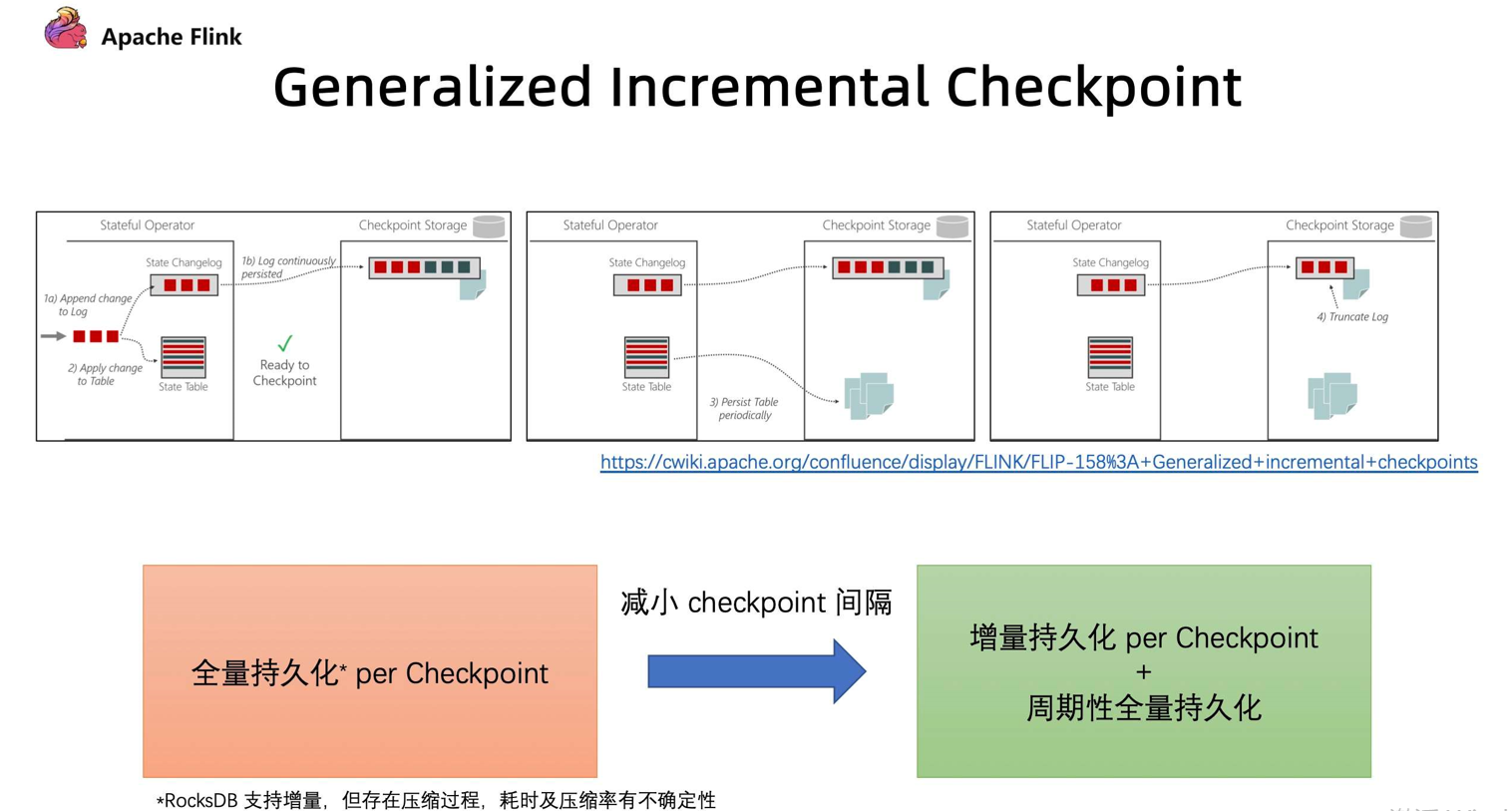
这两个过程进行拆分后,就有了从之前的需要做全量持久化 (Per Checkpoint)变成 增量持久化 (Per Checkpoint) + 后台周期性全量持久化,从而达到同样容错的效果。在这个过程中,每一次 Checkpoint 需要做持久化的数据量减少了,从而使得做 Checkpoint 的间隔能够大幅度减少。
其实在 RocksDB 也是能支持 Incremental Checkpoint 。但是有两个问题:
RocksDB 的 Incremental Checkpoint 是依赖它自己本身的一些实现,当中会存在一些数据压缩,压缩所消耗的时间以及压缩效果具有不确定性,这个是和数据是相关的;只能针对特定的 StateBackend 来使用,目前在做的Generalized Incremental Checkpoint实际上能够保证的是,它与StateBackend是无关的,从运行时的机制来保证了一个比较稳定、更小的 Checkpoint 间隔。
Generalized Incremental Checkpoint 有望在1.14。1 中完成。


























")

")
")




还没有评论,来说两句吧...