zookeeper架构设计及原理分析
zookeeper集群角色
- leader:负责事务操作,负责数据同步
- follower:负责数据读取
- observer:只从leader节点同步数据,但不参与投票选举
集群搭建
准备至少3个服务器:192.168.221.128、192.168.221.129、192.168.221.130
在dataDir目录(可在配置文件查看目录)下创建myid文件,文件内容是id号
修改zoo.cfg
# server.id=ip:port1:port2,第一个端口是数据同步,第二个端口是leader选举server.1=192.168.221.128:2888:3888server.2=192.168.221.129:2888:3888server.3=192.168.221.130:2888:3888server.4=192.168.221.131:2888:3888:observer
开放防火墙端口2181(client连接端口)、2888(数据同步端口)、3888(leader选举端口)
针对observer节点,还需要在zoo.cfg中单独加上标记
peerType=observer
可以通过zkServer.sh status命令查看节点状态

zookeeper弱一致性
zookeeper是弱一致性的,只要过半数据同步成功即代表提交成功,所以有可能有些节点数据还没有同步完成,这时客户端请求获取数据将会读取到不是最新的数据,针对这种情况,zookeeper请求时会携带zxid,对比server上的zxid,如果发现不是最新的zxid,那么请求就会失败,从而保证能够获取到最新的数据
如果想要实现强一致性,可以在获取数据之前,先调用sync()方法对数据进行同步,保证获取到最新数据
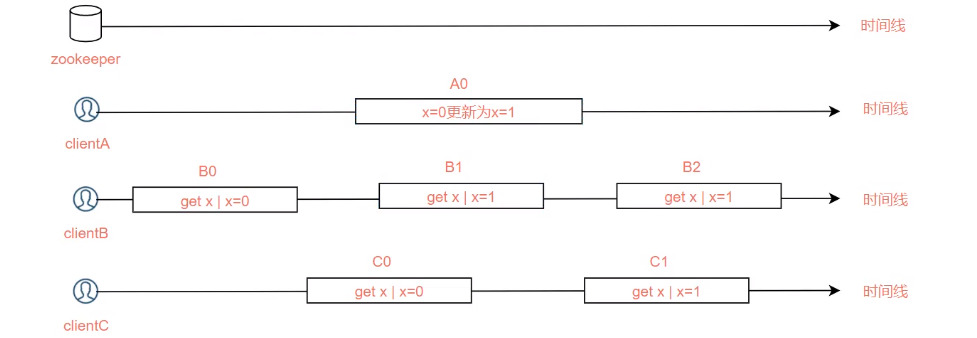
顺序一致性模型
leader选举
zab协议
Zookeeper Atomic Broadcast(原子广播协议),基于paxos算法衍生而来
- 崩溃恢复:leader挂了(心跳监测),需要选举新的leader
- 原子广播:数据同步
leader节点算法设计
确保leader已经提交的事务被提交,丢弃已经跳过的事务
- zxid最高,保证新leader具有已经提交的最新提案
- epoch,每次发出leader选举投票,epoch会递增
leader选举参数顺序
- epoch:优先比较epoch,类似选举轮数,以epoch最大的票数为准
- zxid:其次比较zxid,优先选择拥有最新事务id的节点
- myid:如果前两个参数都相同,那么比较myid,节点id最大的优先
数据存储
log存储事务数据,snapshot存储快照数据



























")


")




还没有评论,来说两句吧...