大数据学习 之Hive 知识点总结
文章目录
- Hive 数据类型
- 原生数据类型
- 复合数据类型
- Hive SerDe
- SerDe ROW FORMAT
- Hive 默认存储路径
- Hive建表
- 内部表和外部表
- 分区表
- 事务表
- 为什么Hive要支持事务?
Hive 数据类型
- Hive SQL中,数据类型英文字母大小写不敏感;
- 除SQL数据类型外,还支持Java数据类型,比如字符串string ;
- 复杂数据类型的使用通常需要和分隔符指定语法配合使用;
- 如果定义的数据类型和文件不一 致, Hive会尝试隐式转换,但是不保证成功。
原生数据类型
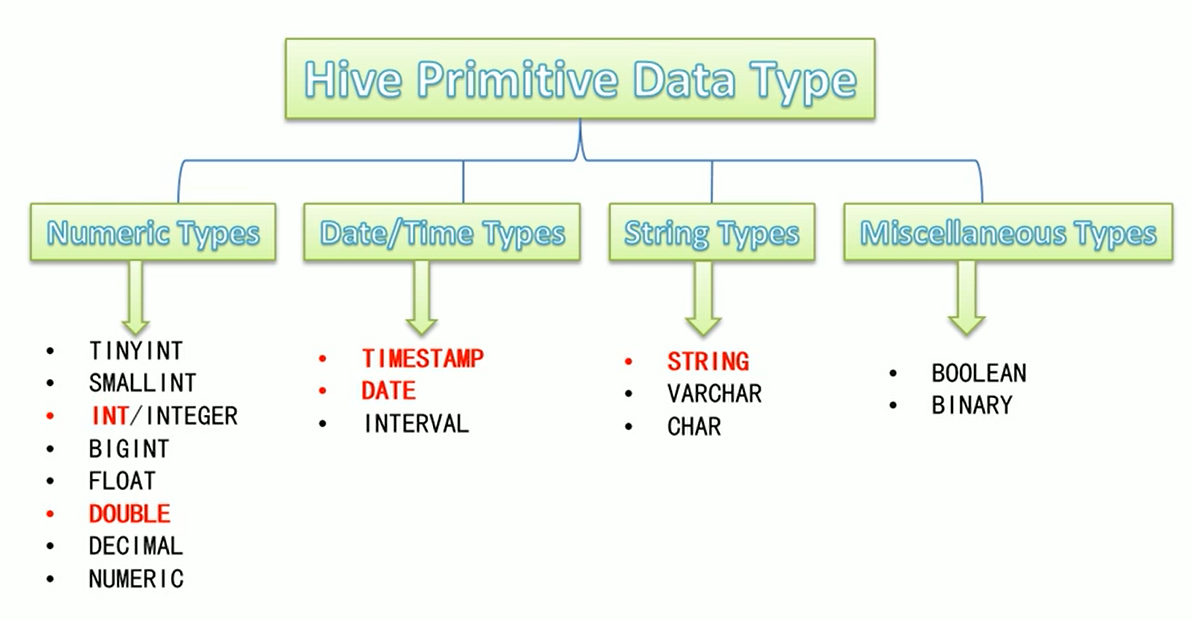
复合数据类型
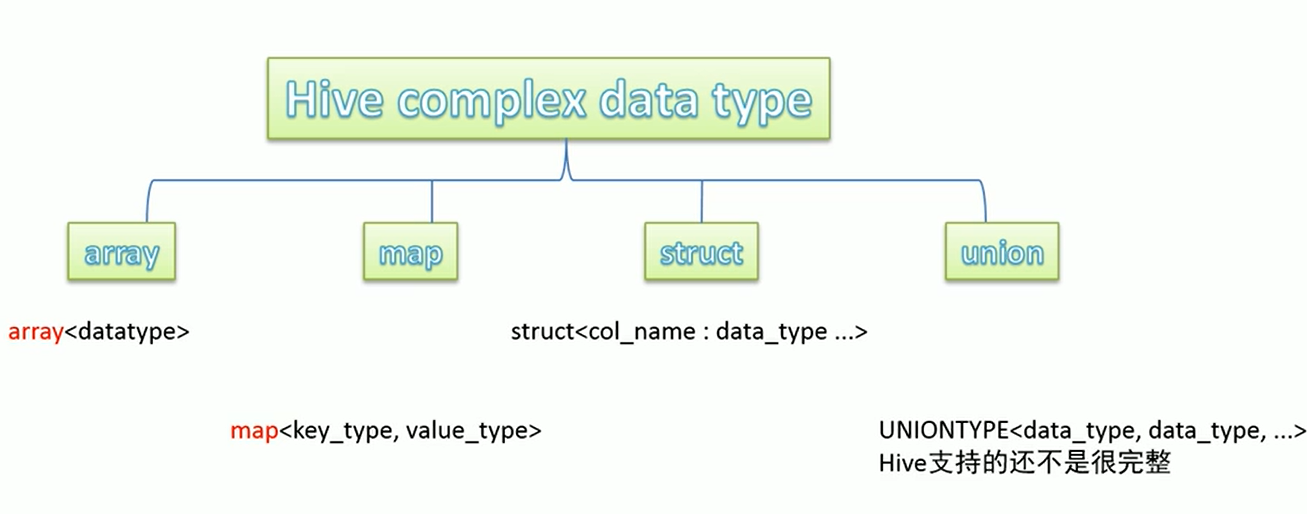
Hive SerDe
在之前,我们知道Hive数据是保存在HDFS上的,而且将结构化文件放到对应的目录,Hive就可以自己解析到数据到数仓中,我们也可以进行HQL操作。
在Hive中,SerDe 是序列化和反序列化的合并,在结构化文件数据=》Hive表数据时,就通过SerDe来进行转换的。
SerDe ROW FORMAT
[ROW FORMAT DELIMITED |SERDE],支持可选项DELIMITED 或 SERDE
- 如果使用
delimited表示使用默认的LazySimpleSerDe类来处理数据。 - 如果数据文件格式比较特殊可以使用
ROW FORMAT SERDE serde_ name指定其他的Serde类来处理数据,甚至支持用户
自定义SerDe类。
同时ROW FORMAT 可以指定结构化数据的分隔符,如果不指定分隔符,默认分隔符是'\001',
Hive 默认存储路径
Hive 默认存储路径是/user/hive/warehouse,但我们也可指定存储路径由$ {HIVE_ HOME} /conf/hive-site. xml配置文件的hive. metas tore. warehouse. dir属性指定,但这样缺乏灵活性。
Hive支持在建表的时候指定,通过Location去指定,该路径必须是HDFS上的
Hive建表
内部表和外部表
默认情况下,就是建立的内部表,当删除内部表时,它会删除数据以及表的元数据。
create table t_archer(id int comment "ID",name string comment "英雄名称",hp_max int comment "最大生命",mp_max int comment "最大法力",attack_max int comment "最高物攻",defense_max int comment "最大物防",attack_range string comment "攻击范围",role_main string comment "主要定位",role_assist string comment "次要定位") comment "王者荣耀射手信息"row format delimitedfields terminated by "\t";
同时,若出现复杂数据类型,我们可以指定三种分隔符来应对复杂情况下分隔符
fields terminated by ',' --字段之间分隔符collection items terminated by '-' --集合元素之间分隔符map keys terminated by ':'; --集合元素kv之间分隔符;
创建外部表,需要使用external 关键字,当删除外部表时,它只会删除表的元数据,也就是说hive只能管理表的元数据
create external table student_ext(num int,name string,sex string,age int,dept string)row format delimitedfields terminated by ','location '/stu';
分区表
分区表可以实现指定文件扫描,而不是多个文件全要扫描一遍.
再考虑十个文件组成了一张hive表,如果说某个文件里正好已经分区好是我们想要的范围,那么创建分区表,并查询的时候指定查询分区,能够提高效率,再比如把一整年的数据根据月份划分12个月( 12个分区) ,后续就可以查询指定月份分区的数据,尽可能避免了全表扫描,但要保证文件是干净的。
根据什么划分,可在建表的时候指定.
create table t_all_hero_part(id int,name string,hp_max int,mp_max int,attack_max int,defense_max int,attack_range string,role_main string,role_assist string) partitioned by (role string)--注意哦 这里是分区字段row format delimitedfields terminated by "\t";--静态加载分区表数据load data local inpath '/root/hivedata/archer.txt' into table t_all_hero_part partition(role='sheshou');load data local inpath '/root/hivedata/assassin.txt' into table t_all_hero_part partition(role='cike');load data local inpath '/root/hivedata/mage.txt' into table t_all_hero_part partition(role='fashi');load data local inpath '/root/hivedata/support.txt' into table t_all_hero_part partition(role='fuzhu');load data local inpath '/root/hivedata/tank.txt' into table t_all_hero_part partition(role='tanke');load data local inpath '/root/hivedata/warrior.txt' into table t_all_hero_part partition(role='zhanshi');
事务表
创建事务表,需要注意的是,事务表创建的几个要素:开启参数、分桶表、存储格式orc、表属性
create table trans_student(id int,name String,age int)clustered by (id) into 2 buckets stored as orc TBLPROPERTIES('transactional'='true');
为什么Hive要支持事务?
使用如Apache Flume、 Apache Kafka之类的工具可将数据流式传输到Hadoop集群中。
虽然这些工具写入数据速度很快,但是Hive只能每隔15分钟到1个小时添加一次分区。
因为如果每分甚至每秒频繁添加分区会很快导致表中大量的分区,并将许多小文件留在目录中,这将给NameNode带来压力。因此通常使用这些工具将数据流式传输到已有分区中,但这有可能会造成脏读(数据传输一半失败,需要回滚了)。即需要通过事务功能,允许用户获得一致的数据视图并避免过多的小文件产生。



























![洛谷 P1169 [ZJOI2007]棋盘制作](https://image.dandelioncloud.cn/images/20230808/72ba490c52904facb1bad28940d1f12a.png "洛谷 P1169 [ZJOI2007]棋盘制作")





还没有评论,来说两句吧...