FlinkSql-cdc 实时ETL kafka 数据
文章目录
- 资源参考
- 1, 配置 debezium-mysql kafka 连接器
- a, mysql开启binlog, 创建mysql 表和cdc用户
- b, 使用 ksql 创建kafka连接器:debezium
- c, flink sql 读写数据( mysql— > hbase)
- 2, 配置 debezium-oracle kafka 连接器
- a, oracle启用archive-log,并配置用户权限
- b, 使用 ksql 创建kafka连接器:debezium
- c, flink sql 读写数据 (oracle — > hbase)
- 3, 使用 web 提交flink sql 任务
- 4, flink 读取 confluent avro topic数据
资源参考
- 参考云邪: https://github.com/ververica/flink-cdc-connectors
- flink 社区:https://www.jianshu.com/u/504bc225cb7a,
Bilibili视频(flink社区):https://www.bilibili.com/video/BV1zt4y1D7kt/ - flink join语法: https://ci.apache.org/projects/flink/flink-docs-release-1.13/zh/docs/dev/table/sql/queries/joins/index.html
1, 配置 debezium-mysql kafka 连接器
a, mysql开启binlog, 创建mysql 表和cdc用户
配置mysql: https://debezium.io/documentation/reference/1.3/connectors/mysql.html#setup-the-mysql-server
mysql> show master status;+------------------+----------+--------------+------------------+| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |+------------------+----------+--------------+------------------+| mysql-bin.000001 | 10290780 | | |+------------------+----------+--------------+------------------+1 row in set (0.00 sec)mysql> use test2;mysql> show create table employee;+----------+--------------------------------------------------------------------| Table | Create Table+----------+-------------------------------------------------------------------- +| employee | CREATE TABLE `employee` (`id` int(11) DEFAULT NULL,`dept_id` int(11) DEFAULT NULL,`name` varchar(20) COLLATE utf8_unicode_ci DEFAULT NULL) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci |+----------+--------------------------------------------------------------------1 row in set (0.00 sec)
b, 使用 ksql 创建kafka连接器:debezium
ksql> CREATE SOURCE CONNECTOR `mysql-dbz-src2` WITH("connector.class"='io.debezium.connector.mysql.MySqlConnector',"tasks.max"='1',"database.hostname"='127.0.0.1',"database.port"='3306',"database.server.name"='dbz2',"database.user"='cdc',"database.password"='cdc',"database.whitelist"='test2',"database.history.kafka.bootstrap.servers"='localhost:9092',"database.history.kafka.topic"='schema-changes2.inventory2');ksql> show connectors;Connector Name | Type | Class | Status--------------------------------------------------------------------------------------------------------mysql-dbz-src2 | SOURCE | io.debezium.connector.mysql.MySqlConnector | RUNNING (1/1 tasks RUNNING)--------------------------------------------------------------------------------------------------------ksql> show topics;Kafka Topic | Partitions | Partition Replicas---------------------------------------------------------------dbz2 | 1 | 1dbz2.test2.dept | 1 | 1dbz2.test2.employee | 1 | 1dbz2.test2.enriched_orders | 1 | 1dbz2.test2.orders | 1 | 1dbz2.test2.products | 1 | 1dbz2.test2.salary | 1 | 1dbz2.test2.shipments | 1 | 1default_ksql_processing_log | 1 | 1---------------------------------------------------------------
通过confluent platform查看kafka数据: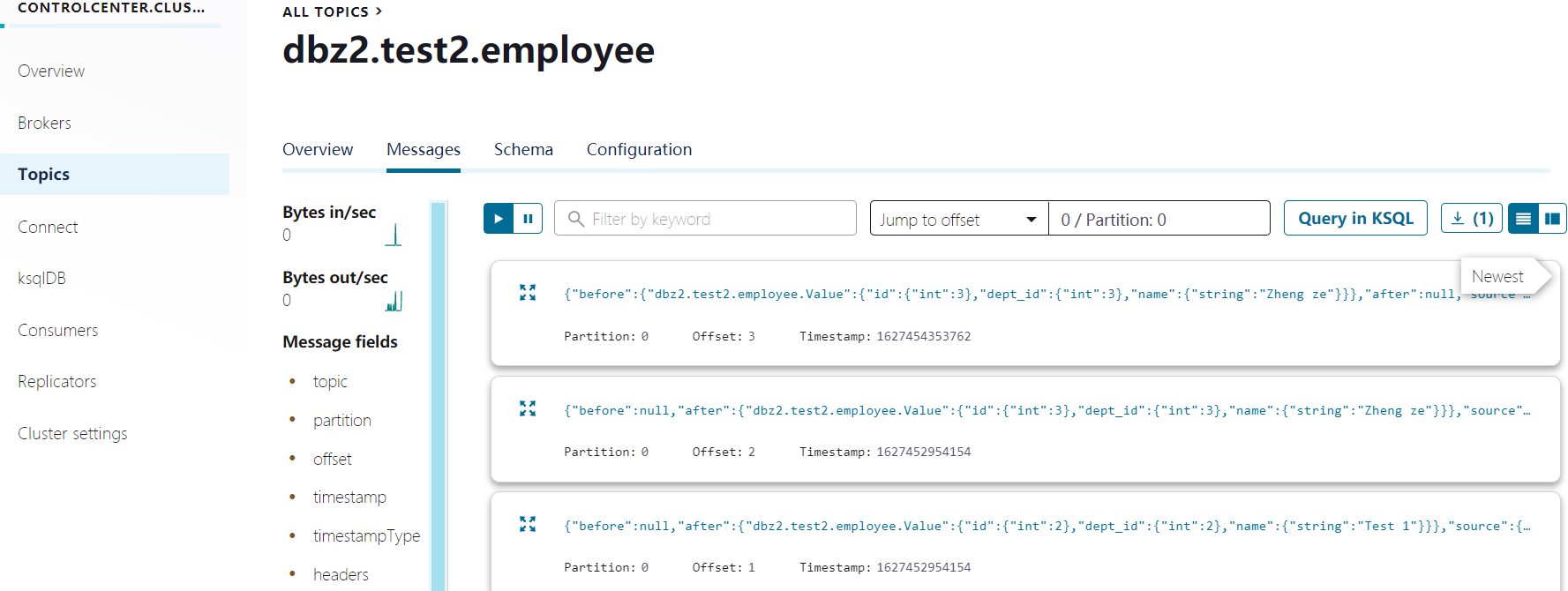
查看topic schema中:表字段和数据类型
c, flink sql 读写数据( mysql— > hbase)
- dedebezium 连接器参数:https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/table/connectors/formats/debezium.html
- hbase 连接器参数:https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/table/connectors/hbase.html
mysql join查询结果:(flink sql 执行类型sql来合并数据并写入hbase)
[root@localhost bin]$ ./sql-client.sh "embedded"| ____| (_) | | / ____|/ __ \| | / ____| (_) | || |__ | |_ _ __ | | __ | (___ | | | | | | | | |_ ___ _ __ | |_| __| | | | '_ \| |/ / \___ \| | | | | | | | | |/ _ \ '_ \| __|| | | | | | | | < ____) | |__| | |____ | |____| | | __/ | | | |_|_| |_|_|_| |_|_|\_\ |_____/ \___\_\______| \_____|_|_|\___|_| |_|\__|Welcome! Enter 'HELP;' to list all available commands. 'QUIT;' to exit.Flink SQL> // dbz2.test2.employee: (字段类型和 registry.url中保持一致,才能解析数据)CREATE TABLE topic_test2_employee (id int,dept_id int,name string) WITH ('connector' = 'kafka','topic' = 'dbz2.test2.employee','properties.bootstrap.servers' = 'localhost:9092','scan.startup.mode' = 'earliest-offset','format' = 'debezium-avro-confluent','debezium-avro-confluent.schema-registry.url' = 'http://localhost:9081');CREATE TABLE topic_test2_dept (id int,name string) WITH ('connector' = 'kafka','topic' = 'dbz2.test2.dept','properties.bootstrap.servers' = 'localhost:9092','scan.startup.mode' = 'earliest-offset','format' = 'debezium-avro-confluent','debezium-avro-confluent.schema-registry.url' = 'http://localhost:9081');CREATE TABLE topic_test2_salary (id int,emp_id int,money double) WITH ('connector' = 'kafka','topic' = 'dbz2.test2.salary','properties.bootstrap.servers' = 'localhost:9092','scan.startup.mode' = 'earliest-offset','format' = 'debezium-avro-confluent','debezium-avro-confluent.schema-registry.url' = 'http://localhost:9081');CREATE TABLE hbase_www (emp_id string,f ROW<emp_dept_id string, name string , deptname string, salary string>,PRIMARY KEY (emp_id) NOT ENFORCED) WITH ('connector' = 'hbase-1.4','table-name' = 'www','zookeeper.quorum' = '192.168.56.117:2181');#关联查询insert into hbase_wwwselect cast(emp.id as string) emp_id,ROW(cast( emp.dept_id as string) , emp.name , dept.name , cast( salary.money as string) )from topic_test2_employee empinner join topic_test2_dept dept on dept.id=emp.dept_idinner join topic_test2_salary salary on salary.emp_id= emp.id[INFO] Submitting SQL update statement to the cluster...[INFO] Table update statement has been successfully submitted to the cluster:Job ID: 137c51550417ab7003c00c95d74f842b
登录flink web ui: 查看运行的任务 查看hbase 数据是否实时变化(mysql insert/update/delete数据后,是否同步变化)
查看hbase 数据是否实时变化(mysql insert/update/delete数据后,是否同步变化)
hbase(main):016:0> scan 'xx_t1'ROW COLUMN+CELL1 column=f:dept_id, timestamp=1627454335726, value=11 column=f:name, timestamp=1627454335726, value=Li si2 column=f:dept_id, timestamp=1627454335726, value=22 column=f:name, timestamp=1627454335726, value=Test 12 row(s) in 0.0120 seconds
2, 配置 debezium-oracle kafka 连接器
https://debezium.io/documentation/reference/1.6/connectors/oracle.html#oracle-deploying-a-connector
oracle join 查询的数据:
a, oracle启用archive-log,并配置用户权限
SQL> shutdown immediatestartup mountalter database archivelog;alter database open;-- Should now "Database log mode: Archive Mode"-- archive log listALTER TABLE user1.table1 ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS;ALTER DATABASE ADD SUPPLEMENTAL LOG DATA;SQL> CREATE TABLESPACE logminer_tbs DATAFILE '/home/oracle/logminer_tbs.dbf' SIZE 25M REUSE AUTOEXTEND ON MAXSIZE UNLIMITED;CREATE USER dbz IDENTIFIED BY dbz DEFAULT TABLESPACE logminer_tbs QUOTA UNLIMITED ON logminer_tbs ;GRANT CREATE SESSION TO dbz ;GRANT SELECT ON V_$DATABASE to dbz ;GRANT FLASHBACK ANY TABLE TO dbz ;GRANT SELECT ANY TABLE TO dbz ;GRANT SELECT_CATALOG_ROLE TO dbz ;GRANT EXECUTE_CATALOG_ROLE TO dbz ;GRANT SELECT ANY TRANSACTION TO dbz ;--GRANT LOGMINING TO dbz ; 11g err: 替换为以下两行GRANT EXECUTE ON SYS.DBMS_LOGMNR TO dbz;GRANT SELECT ON V_$LOGMNR_CONTENTS TO dbz;GRANT CREATE TABLE TO dbz ;GRANT LOCK ANY TABLE TO dbz ;GRANT ALTER ANY TABLE TO dbz ;GRANT CREATE SEQUENCE TO dbz ;GRANT EXECUTE ON DBMS_LOGMNR TO dbz ;GRANT EXECUTE ON DBMS_LOGMNR_D TO dbz ;GRANT SELECT ON V_$LOG TO dbz ;GRANT SELECT ON V_$LOG_HISTORY TO dbz ;GRANT SELECT ON V_$LOGMNR_LOGS TO dbz ;GRANT SELECT ON V_$LOGMNR_CONTENTS TO dbz ;GRANT SELECT ON V_$LOGMNR_PARAMETERS TO dbz ;GRANT SELECT ON V_$LOGFILE TO dbz ;GRANT SELECT ON V_$ARCHIVED_LOG TO dbz ;GRANT SELECT ON V_$ARCHIVE_DEST_STATUS TO dbz ;
b, 使用 ksql 创建kafka连接器:debezium
The Debezium Oracle connector by default ingests changes using native Oracle LogMiner.
ksql> CREATE SOURCE CONNECTOR
oracle_cdc4WITH("connector.class"='io.debezium.connector.oracle.OracleConnector',"tasks.max" ='1',"database.server.name" ='helowin_cdc4',"database.hostname" ='localhost',"database.port" ='15211',"database.user" ='dbz',"database.password" ='dbz',"schema.include.list"='SCOTT',"database.dbname" ='helowin',"decimal.handling.mode"='string',"database.history.kafka.bootstrap.servers" ='localhost:9092',"database.history.kafka.topic"='schema-changes.oracle_cdc4',"database.history.skip.unparseable.ddl"=true
);
ksql> show connectors;
Connector Name | Type | Class | Status
oracle_cdc4 | SOURCE | io.debezium.connector.oracle.OracleConnector | RUNNING (1/1 tasks RUNNING)
ksql> show topics;
Kafka Topic | Partitions | Partition Replicas
helowin_cdc4 | 1 | 1
helowin_cdc4.SCOTT.DEPT | 1 | 1
helowin_cdc4.SCOTT.EMP | 1 | 1
helowin_cdc4.SCOTT.SALGRADE | 1 | 1
helowin_cdc4.SCOTT.TEST | 1 | 1ksql> set ‘auto.offset.reset’=’earliest’;
Successfully changed local property ‘auto.offset.reset’ from ‘earliest’ to ‘earliest’.
ksql> printhelowin_cdc4.SCOTT.TEST;
Key format: SESSION(AVRO) or HOPPING(AVRO) or TUMBLING(AVRO) or AVRO or SESSION(PROTOBUF) or HOPPING(PROTOBUF) or TUMBLING(PROTOBUF) or PROTOBUF or SESSION(JSON) or HOPPING(JSON) or TUMBLING(JSON) or JSON or SESSION(JSON_SR) or HOPPING(JSON_SR) or TUMBLING(JSON_SR) or JSON_SR or SESSION(KAFKA_INT) or HOPPING(KAFKA_INT) or TUMBLING(KAFKA_INT) or KAFKA_INT or SESSION(KAFKA_BIGINT) or HOPPING(KAFKA_BIGINT) or TUMBLING(KAFKA_BIGINT) or KAFKA_BIGINT or SESSION(KAFKA_DOUBLE) or HOPPING(KAFKA_DOUBLE) or TUMBLING(KAFKA_DOUBLE) or KAFKA_DOUBLE or SESSION(KAFKA_STRING) or HOPPING(KAFKA_STRING) or TUMBLING(KAFKA_STRING) or KAFKA_STRING
Value format: AVRO
rowtime: 7/29/21 11:33:09 AM CST, key:, value: { “before”: null, “after”: { “ID”: “2”, “NAME”: “b”, “MARK”: “b”}, “source”: { “version”: “1.6.1.Final”, “connector”: “oracle”, “name”: “helowin_cdc4”, “ts_ms”: 1627529588336, “snapshot”: “last”, “db”: “HELOWIN”, “sequence”: null, “schema”: “SCOTT”, “table”: “TEST”, “txId”: null, “scn”: “1103657”, “commit_scn”: null, “lcr_position”: null}, “op”: “r”, “ts_ms”: 1627529588336, “transaction”: null}
rowtime: 7/29/21 12:11:18 PM CST, key:, value: { “before”: null, “after”: { “ID”: “3”, “NAME”: “c”, “MARK”: “c”}, “source”: { “version”: “1.6.1.Final”, “connector”: “oracle”, “name”: “helowin_cdc4”, “ts_ms”: 1627511996000, “snapshot”: “false”, “db”: “HELOWIN”, “sequence”: null, “schema”: “SCOTT”, “table”: “TEST”, “txId”: “02001f0051030000”, “scn”: “1145746”, “commit_scn”: “1145747”, “lcr_position”: null}, “op”: “c”, “ts_ms”: 1627531878417, “transaction”: null}
rowtime: 7/29/21 12:12:07 PM CST, key:, value: { “before”: { “ID”: “3”, “NAME”: “c”, “MARK”: “c”}, “after”: { “ID”: “3”, “NAME”: “c2”, “MARK”: “c2”}, “source”: { “version”: “1.6.1.Final”, “connector”: “oracle”, “name”: “helowin_cdc4”, “ts_ms”: 1627512679000, “snapshot”: “false”, “db”: “HELOWIN”, “sequence”: null, “schema”: “SCOTT”, “table”: “TEST”, “txId”: “0200080068030000”, “scn”: “1145746”, “commit_scn”: “1174275”, “lcr_position”: null}, “op”: “u”, “ts_ms”: 1627531927799, “transaction”: null}
c, flink sql 读写数据 (oracle – > hbase)
Flink SQL> CREATE TABLE emp (EMPNO int, ENAME string, JOB string, MGR int, HIREDATE BIGINT , SAL string , COMM string, DEPTNO int) WITH ('connector' = 'kafka','properties.bootstrap.servers' = 'localhost:9092','topic' = 'helowin_cdc4.SCOTT.EMP','format' = 'debezium-avro-confluent','debezium-avro-confluent.schema-registry.url' = 'http://localhost:9081','scan.startup.mode' = 'earliest-offset');CREATE TABLE dept (DEPTNO int, DNAME string, LOC string) WITH ('connector' = 'kafka','properties.bootstrap.servers' = 'localhost:9092','topic' = 'helowin_cdc4.SCOTT.DEPT','format' = 'debezium-avro-confluent','debezium-avro-confluent.schema-registry.url' = 'http://localhost:9081','scan.startup.mode' = 'earliest-offset');CREATE TABLE hbase_www2 (EMPNO string ,f ROW<ENAME string, JOB string , MGR string,HIREDATE string, SAL string, COMM string,DEPTNO string, DNAME string, LOC string>,PRIMARY KEY (EMPNO ) NOT ENFORCED) WITH ('connector' = 'hbase-1.4','table-name' = 'www','zookeeper.quorum' = 'localhost:2181');//合并多个表的flink 视图create view dept_emp_v asselect cast(EMPNO as string) EMPNO, ENAME , JOB, cast(MGR as string) MGR, cast(HIREDATE as string) HIREDATE, SAL, COMM, cast(emp.DEPTNO as string) DEPTNO, dept.DNAME ,dept.LOCfrom empINNER JOIN deptON emp.DEPTNO =dept.DEPTNO//从视图中检索数据并插入hbaseinsert into hbase_www2select EMPNO , ROW( ENAME , JOB, MGR , HIREDATE, SAL, COMM, DEPTNO , DNAME ,LOC )from dept_emp_v[INFO] Submitting SQL update statement to the cluster...[INFO] Table update statement has been successfully submitted to the cluster:Job ID: e73a8f4c8860a3bc83879e1a50543350
3, 使用 web 提交flink sql 任务
https://gitee.com/zhuhuipei/flink-streaming-platform-web/blob/master/docs/deploy.md
登录web ui: http://$\{ip或者hostname\}:9084/ , admin 123456 (编辑sql任务)
- 注意:创建任务时,
三方jar地址那一栏最好留空,把相关jar包手动下载到 flink_home/lib, 排除http://ccblog.cn/jars/flink-streaming-udf.jar这个jar包避免和flink内置的函数有冲突 platform 工作原理:本质是调用了flink客户端,提交一个jar包任务
flink run -d -p 2-c com.flink.streaming.core.JobApplicationflink-streaming-platform-web/lib/flink-streaming-core_flink_1.12.0-1.2.0.RELEASE.jar-sql flink-streaming-platform-web/sql/job_sql_8.sql常用jar包
https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/table/connectors/formats/avro-confluent.html
https://repo1.maven.org/maven2/com/alibaba/ververica/flink-sql-connector-mysql-cdc/1.1.0/flink-sql-connector-mysql-cdc-1.1.0.jar
https://repo.maven.apache.org/maven2/org/apache/flink/flink-sql-connector-hbase-1.4_2.11/1.12.3/flink-sql-connector-hbase-1.4_2.11-1.12.3.jar
http://ccblog.cn/jars/flink-connector-jdbc_2.11-1.12.0.jar
http://ccblog.cn/jars/flink-sql-connector-kafka_2.11-1.12.0.jar



4, flink 读取 confluent avro topic数据

ksql> CREATE STREAM t1 (id int , name VARCHAR) WITH ( KAFKA_TOPIC='t1', PARTITIONS='2',VALUE_FORMAT='avro');ksql> insert into t1(id,name) values (1,'a');ksql> select * from t1 emit changes;+------------------+------------------+------------------+------------------+|ROWTIME |ROWKEY |ID |NAME |+------------------+------------------+------------------+------------------+|1627631954797 |null |1 |a |Flink SQL> CREATE TABLE t1 (ID int,NAME string) WITH ('connector' = 'kafka','properties.bootstrap.servers' = 'localhost:9092','topic' = 't1','format' = 'avro-confluent','avro-confluent.schema-registry.url' = 'http://localhost:9081','scan.startup.mode' = 'earliest-offset');




























")

作用")



还没有评论,来说两句吧...