并行计算之向量的计算
#include <stdio.h>#include <stdlib.h>#include <mpi.h>void Read_n(int* n_p, int* local_n_p, int my_rank,int comm_sz, MPI_Comm comm);void Allocate_vectors(double** local_x_pp,double** local_y_pp,double** local_z_pp,int local_n, MPI_Comm comm);void Read_vector(double local_a[], int local_n,int n, char vec_name[],int my_rank, MPI_Comm comm);void Print_vector(double local_b[], int local_n,int n, char title[],int my_rank, MPI_Comm comm);void Parallel_vector_sum(double local_x[],double local_y[],double local_z[],int local_n);int main(void) {int n, local_n;int comm_sz, my_rank;double *local_x, *local_y, *local_z;MPI_Comm comm;MPI_Init(NULL, NULL);comm = MPI_COMM_WORLD;MPI_Comm_size(comm, &comm_sz);MPI_Comm_rank(comm, &my_rank);Read_n(&n, &local_n, my_rank, comm_sz, comm);printf("Proc %d > n = %d, local_n = %d\n",my_rank, n, local_n);Allocate_vectors(&local_x, &local_y,&local_z, local_n, comm);Read_vector(local_x, local_n, n, "x", my_rank, comm);Print_vector(local_x, local_n, n, "x is", my_rank, comm);Read_vector(local_y, local_n, n, "y", my_rank, comm);Print_vector(local_y, local_n, n, "y is", my_rank, comm);Parallel_vector_sum(local_x, local_y, local_z, local_n);Print_vector(local_z, local_n, n, "The sum is",my_rank, comm);free(local_x);free(local_y);free(local_z);MPI_Finalize();return 0;}void Read_n(int* n_p, int* local_n_p, int my_rank,int comm_sz, MPI_Comm comm) {if (my_rank == 0) {printf("What's the order of the vectors?\n");scanf("%d", n_p);}MPI_Bcast(n_p, 1, MPI_INT, 0, comm);*local_n_p = *n_p/comm_sz;}void Allocate_vectors(double** local_x_pp,double** local_y_pp,double** local_z_pp,int local_n, MPI_Comm comm) {*local_x_pp = (double *)malloc(local_n*sizeof(double));*local_y_pp = (double *)malloc(local_n*sizeof(double));*local_z_pp = (double *)malloc(local_n*sizeof(double));}void Read_vector(double local_a[], int local_n,int n, char vec_name[],int my_rank, MPI_Comm comm) {double* a = NULL;int i;if (my_rank == 0) {a = (double *)malloc(n*sizeof(double));printf("Enter the vector %s\n", vec_name);for (i = 0; i < n; i++)scanf("%lf", &a[i]);MPI_Scatter(a, local_n, MPI_DOUBLE,local_a, local_n, MPI_DOUBLE, 0, comm);free(a);}else {MPI_Scatter(a, local_n, MPI_DOUBLE,local_a, local_n, MPI_DOUBLE, 0, comm);}}void Print_vector(double local_b[], int local_n,int n, char title[],int my_rank, MPI_Comm comm) {double* b = NULL;int i;if (my_rank == 0) {b = (double *)malloc(n*sizeof(double));MPI_Gather(local_b, local_n, MPI_DOUBLE, b,local_n, MPI_DOUBLE, 0, comm);printf("%s\n", title);for (i = 0; i < n; i++)printf("%f ", b[i]);printf("\n");free(b);}else {MPI_Gather(local_b, local_n, MPI_DOUBLE, b,local_n, MPI_DOUBLE, 0, comm);}}void Parallel_vector_sum(double local_x[],double local_y[],double local_z[],int local_n) {int local_i;for (local_i = 0; local_i < local_n; local_i++)local_z[local_i] = local_x[local_i] + local_y[local_i];}
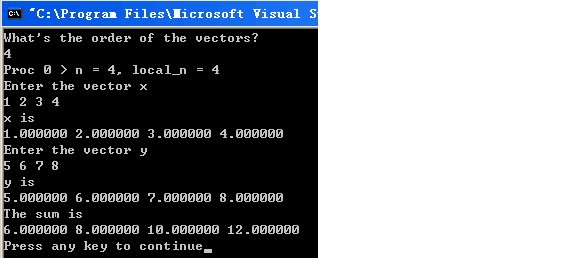
VC6运行效果图
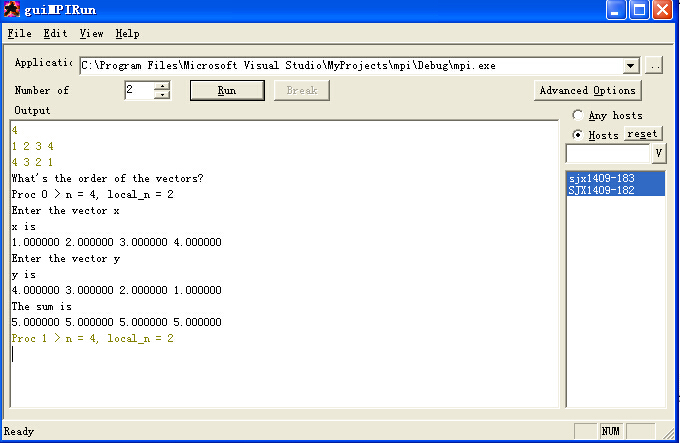
MPI运行效果图




























还没有评论,来说两句吧...