多线程竞争
在多线程编程中,会经常碰到资源竞争的情况,如果多个线程同时访问同个资源,会照成未知的错误。
如以下实例代码,多个线程对同个全局变量进行加1操作,得到的结果并非是我们想要的结果:
unsigned long g_count_num = 0;long long getSystemTime() {struct timeb t;ftime(&t);return 1000 * t.time + t.millitm;}void * pth_test_fun(void * a_arg){int b_loop;for(b_loop = 0; b_loop < 10000000; b_loop++){g_count_num++;}return 0;}int main(){int b_loop;long long b_begin, b_end;pthread_t b_pth_id[20];b_begin = getSystemTime();for(b_loop = 0; b_loop < 10; b_loop++){pthread_create(&b_pth_id[b_loop], NULL, pth_test_fun, NULL);}for(b_loop = 0; b_loop < 10; b_loop++){pthread_join(b_pth_id[b_loop], NULL);}b_end = getSystemTime();printf("time = %lu, val = %lu\n", b_end - b_begin, g_count_num);return 0;}
运行结果:
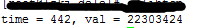
time是整个线程运行的总时间,val是全局变量g_count_num 的值,多个线程同时对该变量进行操作,当一个线程对该变量进行操作时,但还没对该变量进行加1操作,而另一个线程同时对该变量进行操作,读出的值是原值还没加1的值,这样就造成了最后变量g_count_num的值不正确
多线程操作同一个资源,最好加锁,给资源加上锁,保证同一个时刻只有一个线程可以访问该资源,其他访问该资源的线程阻塞直到访问该资源的线程解锁释放该资源。
最常见的就是利用pthread_mutex_lock进行加锁,如以下实例代码:
unsigned long g_count_num = 0;pthread_mutex_t * g_pth_mutex = NULL;long long getSystemTime() {struct timeb t;ftime(&t);return 1000 * t.time + t.millitm;}void * pth_test_fun(void * a_arg){int b_loop;for(b_loop = 0; b_loop < 10000000; b_loop++){pthread_mutex_lock(g_pth_mutex);g_count_num++;pthread_mutex_unlock(g_pth_mutex);}return 0;}int main(){int b_loop;long long b_begin, b_end;pthread_t b_pth_id[20];pthread_mutex_init(g_pth_mutex, NULL);b_begin = getSystemTime();for(b_loop = 0; b_loop < 10; b_loop++){pthread_create(&b_pth_id[b_loop], NULL, pth_test_fun, NULL);}for(b_loop = 0; b_loop < 10; b_loop++){pthread_join(b_pth_id[b_loop], NULL);}b_end = getSystemTime();pthread_mutex_destroy(g_pth_mutex);printf("time = %lu, val = %lu\n", b_end - b_begin, g_count_num);return 0;}
运行结果:
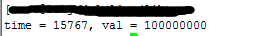
对资源加锁后,变量的值正常了。
除了pthread_mutex_lock可以对资源加锁外,我们还可以利用信号量,信号量就是一个计数器,计数可以访问资源的线程数,来试试信号量和锁那种性能高:
unsigned long g_count_num = 0;int g_semphore_id = 0;#define SEM_KEY 10008long long getSystemTime() {struct timeb t;ftime(&t);return 1000 * t.time + t.millitm;}void * pth_test_fun(void * a_arg){int b_loop;struct sembuf b_lock_sop = {0}, b_unlock_sop = {0};b_lock_sop.sem_num = 0;b_lock_sop.sem_op = -1;b_lock_sop.sem_flg = SEM_UNDO;b_unlock_sop.sem_num = 0;b_unlock_sop.sem_op = 1;b_unlock_sop.sem_flg = SEM_UNDO;for(b_loop = 0; b_loop < 10000000; b_loop++){semop(g_semphore_id, &b_lock_sop, 1);g_count_num++;semop(g_semphore_id, &b_unlock_sop, 1);}return 0;}int main(){int b_loop;long long b_begin, b_end;pthread_t b_pth_id[20];union semun b_sem_val = {0};g_semphore_id = semget(SEM_KEY, 1, IPC_CREAT|0666);semctl(g_semphore_id, 0, SETVAL, 1);b_begin = getSystemTime();for(b_loop = 0; b_loop < 10; b_loop++){pthread_create(&b_pth_id[b_loop], NULL, pth_test_fun, NULL);}for(b_loop = 0; b_loop < 10; b_loop++){pthread_join(b_pth_id[b_loop], NULL);}b_end = getSystemTime();semctl(g_semphore_id, 0, IPC_RMID);printf("time = %lu, val = %lu\n", b_end - b_begin, g_count_num);return 0;}
运行结果:

和上个程序对比,信号量的消耗时间比线程锁消耗的时间更多,在锁资源方面,线程锁性能高点
测试下一段代码前,先介绍一个概念,原子操作。
原子操作就是该操作不会被任何打断直至操作完成,操作系统定义了一些相关原子操作,比如对变量进行原子加1,原子减1.以下代码就是利用了系统原子操作特性atomic64_inc(原子加1操作),来实现多线程对同个资源的操作:
typedef struct {volatile long counter;} atomic64_t;atomic64_t g_count_num = {0};static inline void atomic64_inc(atomic64_t *v){asm volatile("lock ;" "incq %0": "=m" (v->counter): "m" (v->counter));}void * pth_test_fun(void * a_arg){int b_loop;for(b_loop = 0; b_loop < 10000000; b_loop++){atomic64_inc(&g_count_num);}return 0;}long long getSystemTime() {struct timeb t;ftime(&t);return 1000 * t.time + t.millitm;}int main(){int b_loop;long long b_begin, b_end;pthread_t b_pth_id[20];b_begin = getSystemTime();for(b_loop = 0; b_loop < 10; b_loop++){pthread_create(&b_pth_id[b_loop], NULL, pth_test_fun, NULL);}for(b_loop = 0; b_loop < 10; b_loop++){pthread_join(b_pth_id[b_loop], NULL);}b_end = getSystemTime();printf("time = %lu, val = %lu\n", b_end - b_begin, g_count_num.counter);return 0;}
运行结果:

通过运行结果可看出,性能比加锁高出很多,因为毕竟加锁操作的实现也是经过原子操作实现的
再来看看另一段代码,利用__sync_fetch_and_add原子加1.
unsigned long g_count_num = 0;void * pth_test_fun(void * a_arg){int b_loop;for(b_loop = 0; b_loop < 10000000; b_loop++){__sync_fetch_and_add(&g_count_num, 1);}return 0;}int main(){int b_loop;long long b_begin, b_end;pthread_t b_pth_id[20];b_begin = getSystemTime();for(b_loop = 0; b_loop < 10; b_loop++){pthread_create(&b_pth_id[b_loop], NULL, pth_test_fun, NULL);}for(b_loop = 0; b_loop < 10; b_loop++){pthread_join(b_pth_id[b_loop], NULL);}b_end = getSystemTime();printf("time = %lu, val = %lu\n", b_end - b_begin, g_count_num);return 0;}
运行结果:


























盒子模型,边框,内外边距,盒子模型布局,ps基本操作,列表样式,圆角边框,盒子阴影")








还没有评论,来说两句吧...