Hadoop分布式搭建、Hbase安装、Hive安装
Hadoop分布式搭建、Hbase安装、Hive安装
关于hadoop分布式环境的搭建,网上有很多教程,看起来很简单,对着别人的教程一步一步来,但是真的是亲身试了这趟水,才知道这趟水有多深,就算步骤对着别人的教程一步不错,也会出现大大小小的问题,我前后安装的数次,解决了N个乱七八糟的问题,真的很消磨耐心,但是学习之路永远艰且长,所以认真学,逐渐摸清它的本质,就算出现问题也能自己解决。
这是最终成功的版本,特此记录成安装手册
- 安装环境:ubuntu12.04 64位系统
Hadoop版本:hadoop2.6.0
Hadoop安装
一、创建用户
:因为我在创建虚拟机,安装ubuntu的时候用的用户就是hadoop,默认为管理员,不用再设置增加权限,并将用户密码设置为hadoop。
二、更新apt:
根据网上教程,若是没有更新apt安装软件,可能有些软件安装不了。
登录hadoop用户,按ctrl+alt+t打开终端窗口,执行如下命令:
$ sudo apt-get update
" class="reference-link">
三、安装SSH、配置SSH无密码登陆:
SSH是专为远程登录会话和其他网络服务提供安全性的协议
公钥私钥简单实现原理:
1、比如两台服务器A、B,A要通过SSH远程B,A首先本地生成公钥私钥对,将公钥发送给B,B收到A的公钥后加入到自己授权列表中。此时A、B公钥私钥对配置完成
2、在A请求远程B时,B先在授权列表中检查是否有A相关登录用户配置,如果有,那么就B就用A的公钥加密一段信息,发送给A,A收到后用私钥解密,然后发回给B,B就接收A解密后的信息,与发出的信息进行校验,如果校验成功则允许登录
集群、单节点模式都需要用到SSH登陆,ubuntu默认已安装了SSH client,此外还需要安装SSH server
安装后,可以使用如下命令登陆本机:
此时,会有如下提示(SSH首次登陆提示),输入yes。然后按提示输入密码hadoop,这样就登陆到本机了。
配置SSH无密码登陆:首先退出刚才的SSH,回到原先的终端窗口,然后利用ssh-keygen生成密匙,并将密匙加入到授权中:

加入授权:
四、安装java环境:
jre和jdk的区别
JRE(Java Runtime Environment,Java运行环境),是运行 Java 所需的环境。JDK(Java Development Kit,Java软件开发工具包)即包括 JRE,还包括开发 Java 程序所需的工具和类库。
直接通过命令安装OpenJDK 7
安装好OpenJDK后,找到相应的安装路径:
红色的/bin/javac前面的一串:/usr/lib/jvm/java-7-openjdk-i386,就是其安装路径
接着配置JAVA_HOME环境变量:
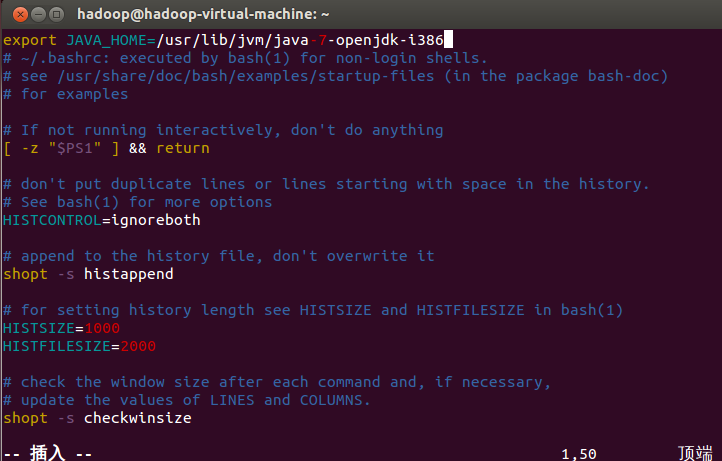
使该环境变量生效: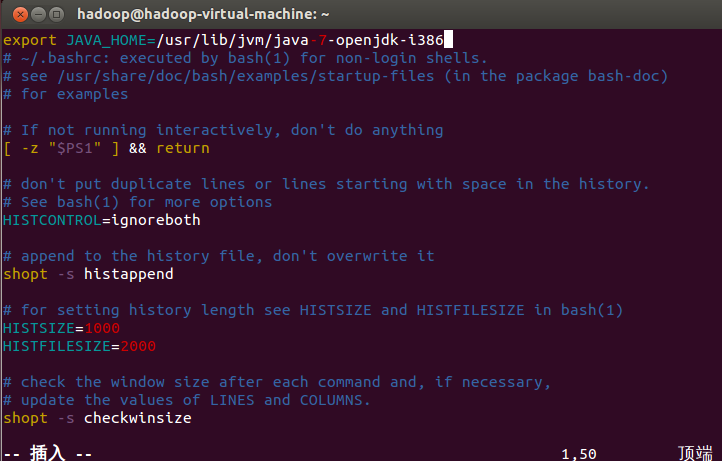
五、安装hadoop:
我下载的是hadoop-2.6.0版本,下载在“下载”文件夹中;并选择将hadoop安装到/usr/local/中
- 将hadoop安装包解压到/usr/local中

- 将文件夹名改为hadoop:

- 修改文件权限:

Hadoop解压后即可使用。输入如下命令检查hadoop是否可用,成功则会显示hadoop的版本信息: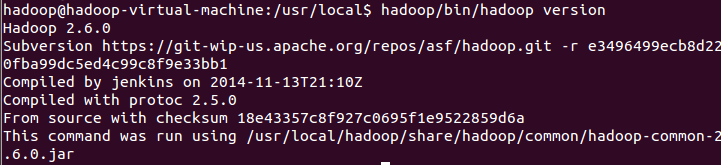
六、hadoop伪分布式配置:
Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件。
Hadoop 的配置文件位于 /usr/local/hadoop/etc/hadoop/ 中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml 。Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现。
修改配置文件core-site.xml

如图修改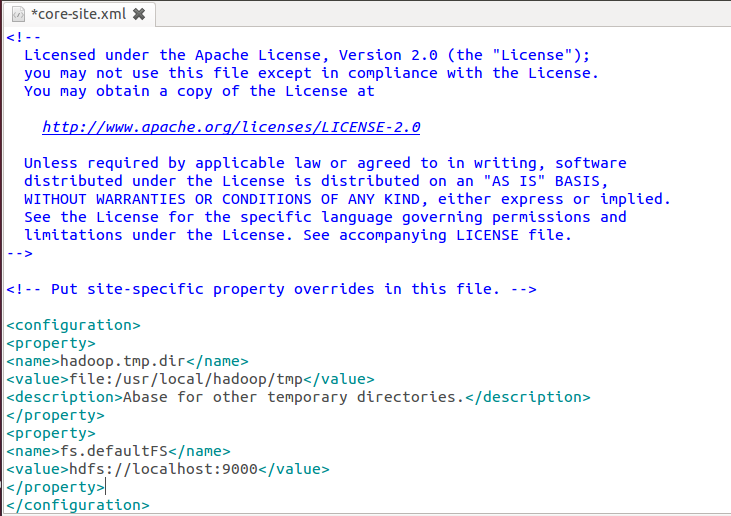
- 修改配置文件hdfs-site.xml:

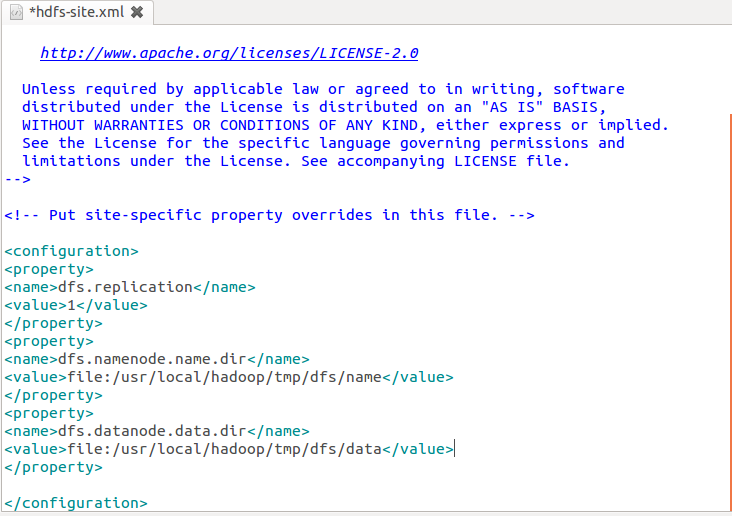
- 配置完成后,执行NameNode的格式化

成功: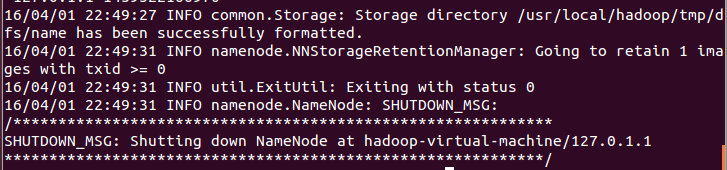
- 开启NameNode和DataNode守护进程:

七、启动YARN
新版的 Hadoop 使用了新的 MapReduce 框架(MapReduce V2,也称为 YARN,Yet Another Resource Negotiator)。
YARN 是从 MapReduce 中分离出来的,负责资源管理与任务调度。
- 重命名:

- 修改配置文件mapred-site.xml:
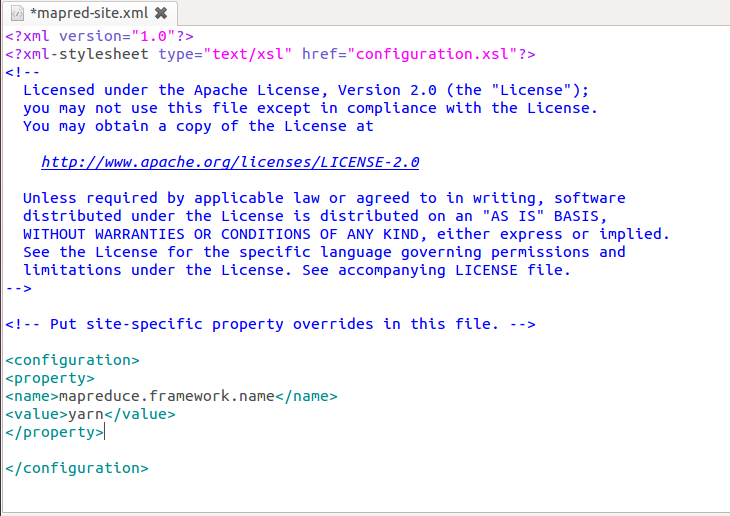
- 修改配置文件yarn-site.xml:

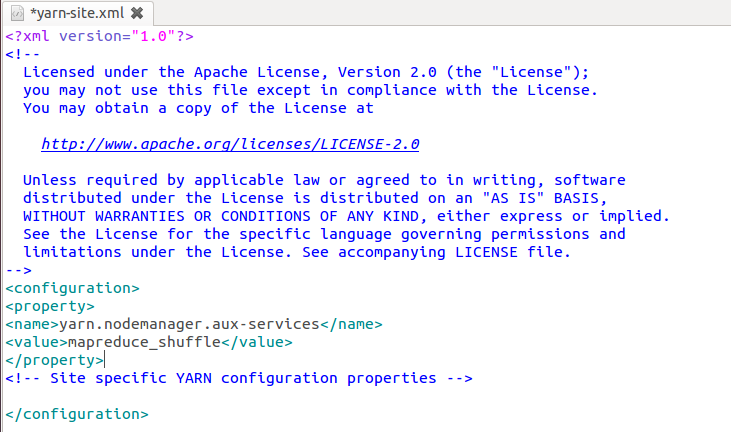
- 启动YARN:

- 开启历史服务器,在Web中查看任务运行情况:

八、
网络配置:
我使用的是虚拟机,所以需要更改网络连接方式为桥接(Bridge)模式,才能实现多个节点互连
此外,如果节点的系统是在虚拟机中直接复制的,要确保各个节点的 Mac 地址不同(可以点右边的按钮随机生成 MAC 地址,否则 IP 会冲突
- 安装其他两台slave虚拟机:slave1,slave2
- 按以上相同的方法,在这两台slave虚拟机上配置hadoop用户、安 装SSH server、安装java环境。
- 查看得知3台虚拟机的ip地址:
- 在master节点上修改主机名,改为master:


- 修改所用结点的ip映射:


- 用同样的方法,在其他两个slave1,slave2结点上,修改主机名和自己所用结点的ip映射。修改完之后还需要重启机器一下,才能机器名的变化。
- 配置好后需要在各个节点上执行ping命令,测试是否相互 ping 得通,如果 ping 不通,后面就无法顺利配置成功:
九、SSH无密码登陆结点
- 首先生成master结点的公匙,在master的终端执行,因为改过主机名,所以得删掉原来的再重新生成一次

- 让master结点能无密码登陆本机,执行:

- 在master结点上将公匙传输到slave1,和slave2结点:

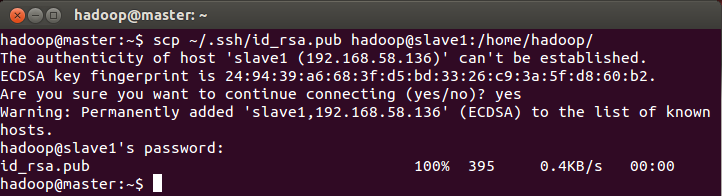
- 接着在slave1结点上,将SSH的公匙加入授权:

- 在master结点上就可以无密码SSH到各个结点了,执行如下命令进行检验:

十、配置PATH变量:
将hadoop安装目录加入到PATH变量中,这样就可以在任意目录中直接使用hadoop、hdfs等命令了,在master结点中进行配置,执行:
加入一行:
然后执行:(使配置生效)
十一、配置集群/分布式环境
修改文件core-site.xml
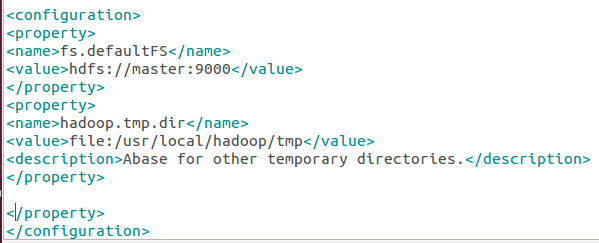
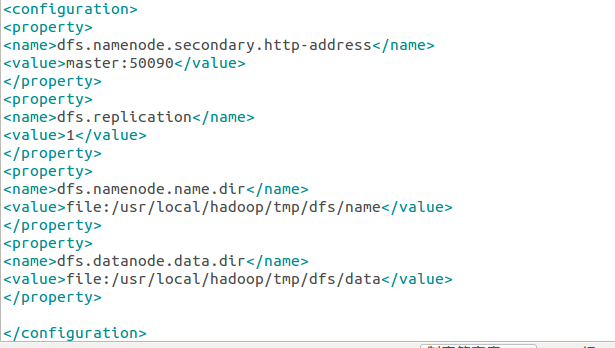
修改文件hdfs-site.xml:
修改文件mapred-site.xml: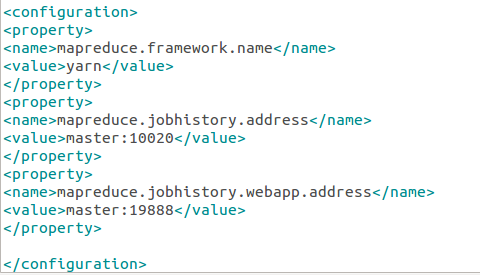
修改文件yarn-site.xml: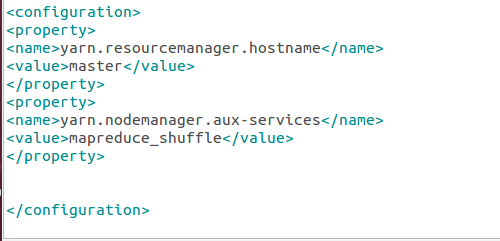
- 配置好文件后,将master上的/usr/local/hadoop文件夹复制到各个结点上,在master结点上执行:
删除hadoop临时文件和日志文件
压缩后再复制:

- 在slave结点上执行:


- 首次启动需要先在master结点上执行NameNode的格式化:

- 启动hadoop,在master结点上执行:

通过jps指令查看各个节点启动的进程
Hbase安装
一、安装运行HBase:
- 解压安装包至路径/usr/local

- 将解压的文件名hbase-1.1.4改为hbase:

- 查看hbase版本,确定hbase安装成功:

Hive安装
- 解压缩下载的Hive软件包

- 将文件名改为hive:

- 修改文件权限:

- 创建元数据存储文件夹:

- 修改文件权限:

- 为了方便使用,将hive的命令加入到环境变量中去,使用下列命令编辑.bashrc文件:


使配置生效:
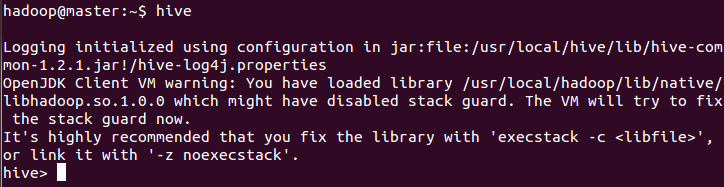
- 运行启动hive:

























")


还没有评论,来说两句吧...