双向链表和循环链表
一、双向链表
每个结点有两个指针域和若干数据域,其中一个指针域指向它的前趋结点,一个指向它的后继结点。它的优点是访问、插入、删除更方便,速度也快了。但“是以空间换时间”。
【数据结构的定义】
struct node{int data;node *pre,*next;//pre指向前趋,next指向后继};node *head,*p,*q,*r;
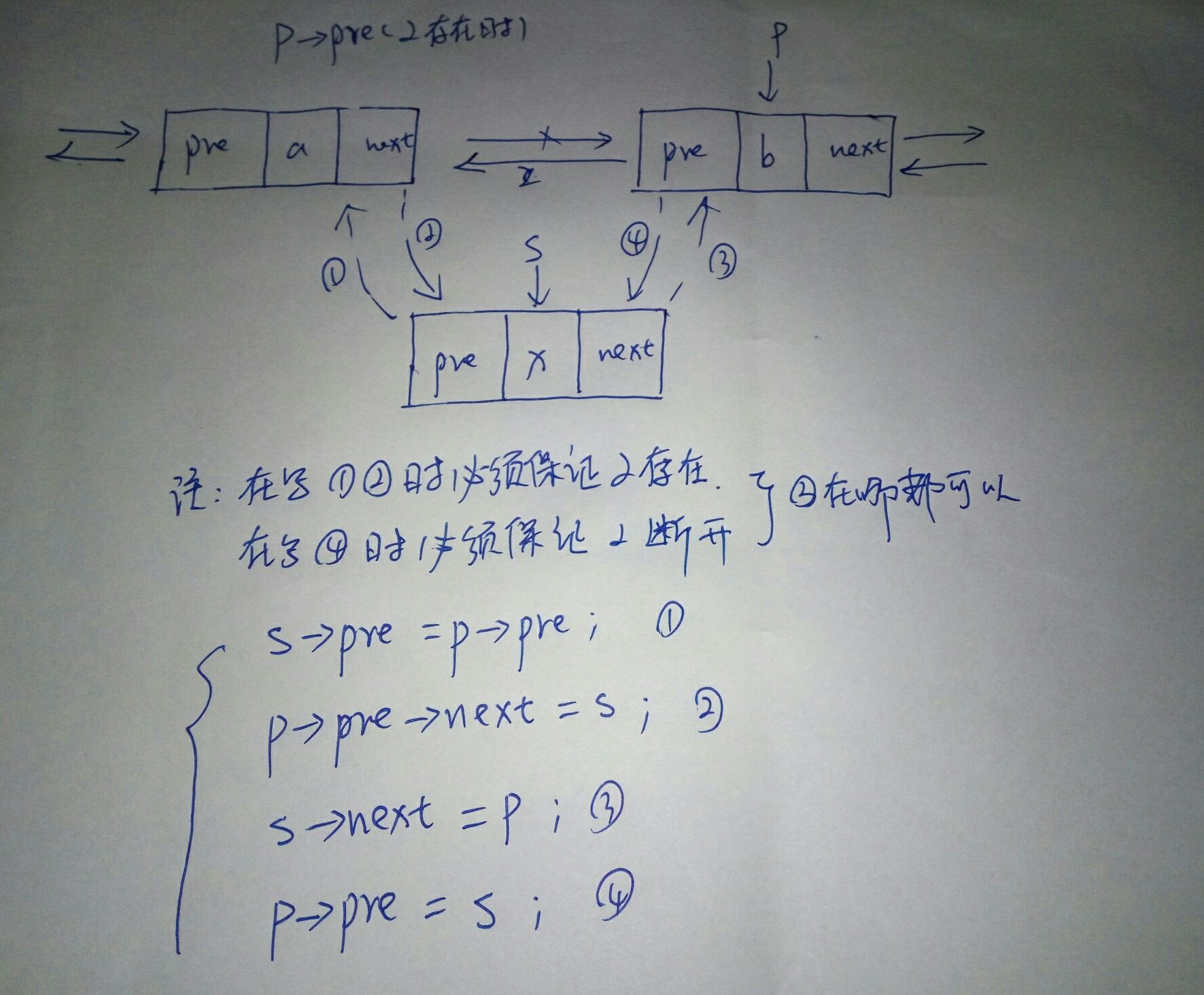
void insert(node *head,int i,int x)//在双向链表的第i个结点之前插入x{node *s,*p;int j;s=new node;s->data=x;p=head;j=0;while((p->next!=NULL)&&(j<i))//最终p指向第i个结点{p=p->next;j=j+1;}if(p=NULL){cout<<"no this position!";}else{s->pre=p->pre;//将s的前驱指向p个前驱p->pre->next=s;//将p的本来前驱结点的后继指向ss->next=p;//将s的后继指向pp->pre=s;//将s的前驱指向p的前驱}}
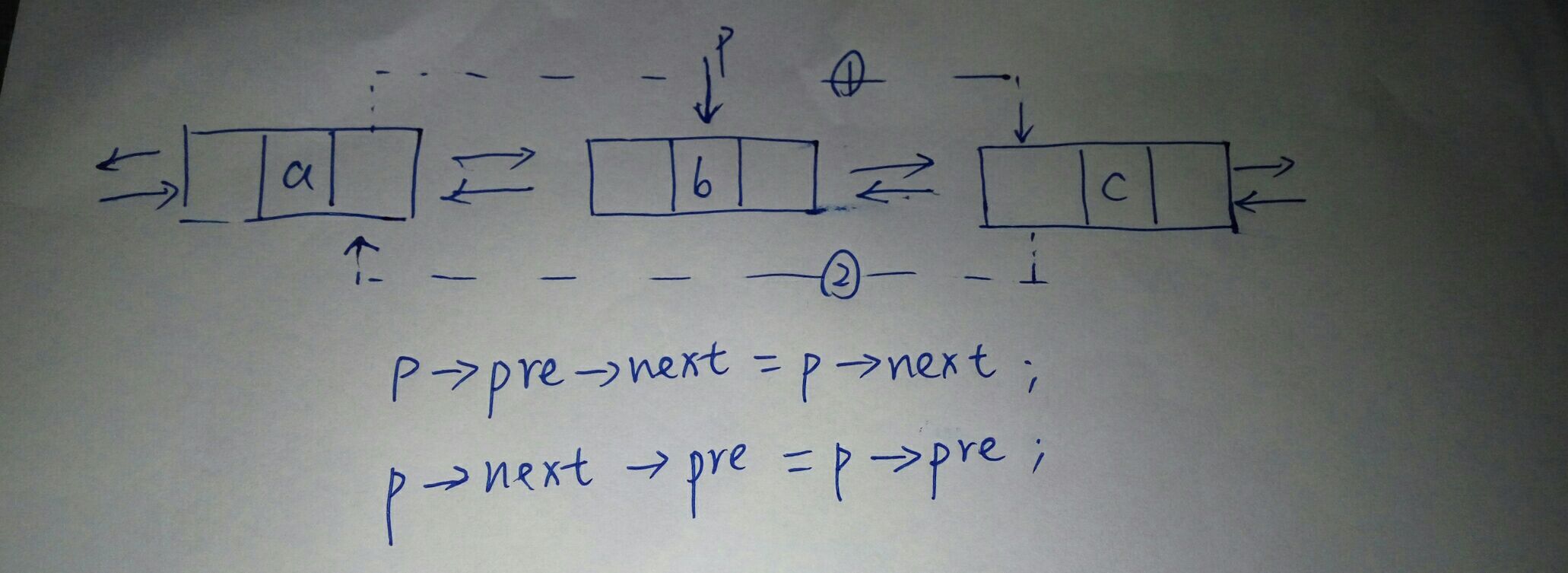
二、循环链表
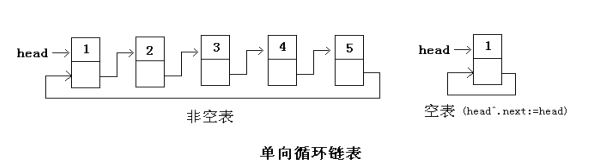
单向循环链表:最后一个结点的指针指向头结点。如下图:
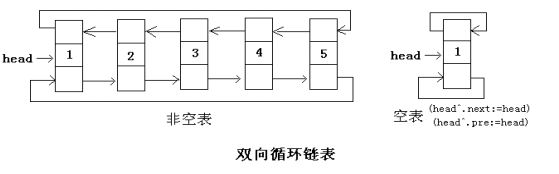
双向循环链表:最后一个结点的指针指向头结点,且头结点的前趋指向最后一个结点。如下图:




























:10张图解再谈物理内存和虚拟内存")





还没有评论,来说两句吧...