Java爬取网页内容的简单例子
原文转载自:https://www.2cto.com/kf/201408/324292.html
【准备工作】
下载一个 jsoup-1.6.1.jar
【目标页面】
中国天气网

【目标】
获取今日的天气情况
通过查看页面代码可以看到,我们所需要抓取的数据在页面中如下图
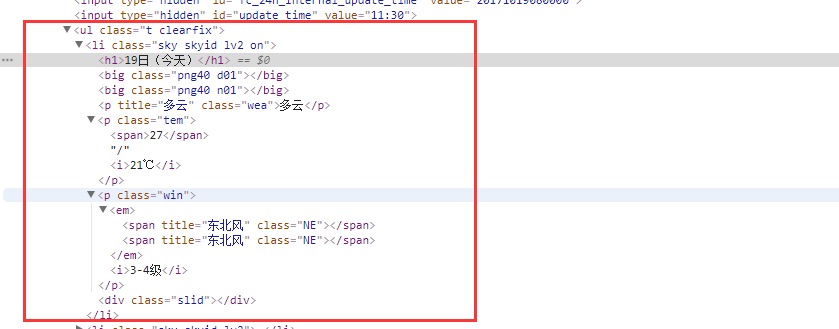
【解析代码】
通过对代码的分析,我们看到:
我们所需要的数据都在 “
- ……
日期在”
天气在 “
中” ;
最高温在:”
中”;
最低气温在:”
内的 中”;
风力:”
内的 中”
根据上面分析的结果,看下下面的代码:
import java.io.IOException; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.select.Elements; public class TestJsoup { /** * * @param url 访问路径 * @return */ public Document getDocument (String url){ try { //5000是设置连接超时时间,单位ms return Jsoup.connect(url).timeout(5000).get(); } catch (IOException e) { e.printStackTrace(); } return null; } public static void main(String[] args) { TestJsoup t = new TestJsoup(); Document doc = t.getDocument("http://www.weather.com.cn/weather/101230101.shtml"); // 获取目标HTML代码 Elements elements1 = doc.select("[class=t clearfix]"); //今天 Elements elements2 = elements1.select("[class=sky skyid lv2 on]"); String today = elements2.get(0).text(); System.out.println("今日天气: "+today); //几号 Elements elements3 = elements1.select("h1"); String number = elements3.get(0).text(); System.out.println("日期: "+number); // 天气 Elements elements4 = elements1.select("[class=wea]"); String rain = elements4.get(0).text(); System.out.println("天气: "+rain); // 最高温度 Elements elements5 = elements1.select("span"); String highTemperature = elements5.get(0).text()+"°C"; System.out.println("最高温:"+highTemperature); // 最低温度 Elements elements6 = elements1.select(".tem i"); String lowTemperature = elements6.get(0).text(); System.out.println("最低温:"+lowTemperature); // 风力 Elements elements7 = elements1.select(".win i"); String wind = elements7.get(2).text(); System.out.println("风力:"+wind); } }
代码运行结果:
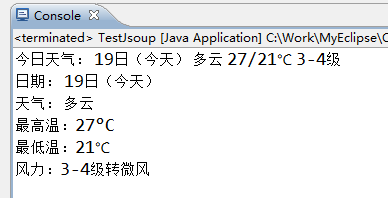
从 Jsonp 的API 文档中可以知道,获取数据源的方法有三种:
第一种:从一段html代码字符串中获取: Document doc = Jsonp.parse(html);
第二种:从一个url中获取:Document doc = Jsonp.connect(“http://www.weather.com.cn/weather/101230101.shtml").get();
第三种:从一个html文件中获取:File input = new File(“/tem/input.html”);
Document doc = Jsoup.parse(input, "UTF-8", "http://www.weather.com.cn/weather/101230101.shtml");
在这里我们采取的是 第二中方法。
上述代码中,最重要的一个为 doc.select(“”)
Document 继承自 Element 类, 而Element类有一个很好的方法,叫select , 这个选择器几乎无所不能。快速从一堆html代码中获取我们想要的一段,我觉得使用select最方便。下面我们来看怎么使用select方法来查找。
1. 通过标签名称进行查找:
<span>33</span> <span>25</span>Elements elements = doc.select("span"); //注:通过标签来查找,直接写 "标签名" 就好,不需要尖括号。
2. 通过 id 进行查找:
<span id="mySpan">36</span> <span>20</span>Elements elements = doc.select("#mySpan"); //注:通过id来查找,使用方法跟css指定元素一样,用#
3.通过 class 名称进行查找:
<span class="myClass">36</span> <span>20</span>Elements elements = doc.select(".myClass"); //注:通过 class 来查找,使用方法跟css指定元素一样,用 .
4.利用标签内的属性名称来查找元素:
<span class="class1" id="id1">36</span> <span class="class2" id="id2">36</span>Elements elements = doc.select("span[class=class1]span[id=id1]"); // 注:规则为 标签名[属性名=属性值],标签名可写可不写,多个属性即多个[],如上。
5.利用标签内的属性前缀来查找元素
<span class="class1" >36</span> <span class="class2" >22</span>Elements elements = doc.select("span[^cl]"); //注:规则为 标签名[^属性名前缀],标签名可写可不写,多个属性即多个[]。
6.利用标签内属性名+正则表达式查找元素
<span class="ABC" >36</span> <span class="ADE" >22</span>Elements elements = doc.select("span[class~=^AB]"); //注:规则为 标签名 [属性名~=正则表达式],以上的正则表达式的意思是查找以class值以AB为开头的标签,标签名可写可不写,多个属性即多个[]
7.利用标签文本包含某些内容来查找元素
<span>36</span> <span>22</span>Elements elements = doc.select("span:contains(3)"); //注:规则为 标签名:contains(文本值)
8. 利用标签文本包含某些内容+正则表达式来查找元素
<span>36</span> <span>22</span>Elements elements = doc.select("span:matchesOwn(^3)"); // 注:规则为 标签名:matchesOwn(正则表达式),以上的正则表式的意思是以文本值以3为开头的标签
select方法返回的是一个Elements 对象,里面包含着找到的所有节点。遍历Elements ,通过get(index),就可以拿出具体的 节点了。通过节点的text()方法,就可用拿出文本值。
而想得到节点的其他属性,可以看API的介绍。




























")





还没有评论,来说两句吧...