分布式 大型网站的架构演进
大型网站的架构演进
主要是简单的网站结构如何演进成具有高数据量和访问量的大型网站
1.使用Java技术和单机来构建的网站
一个交易网站的架构
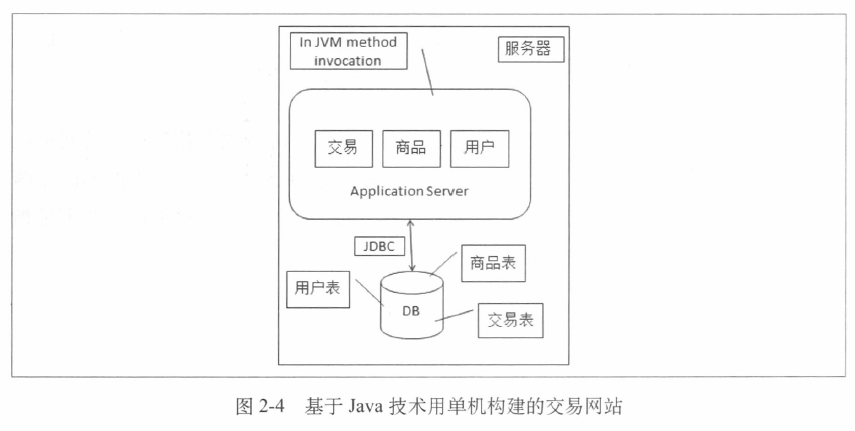
各个功能模块之间通过JVM内部的方法调用来进行交互,应用和数据库之间通过JDBC进行访问
2.单机负载过大,数据库和应用分离
访问量增大的时候,首先可以做的是把数据库应用从一台机器分到两台机器
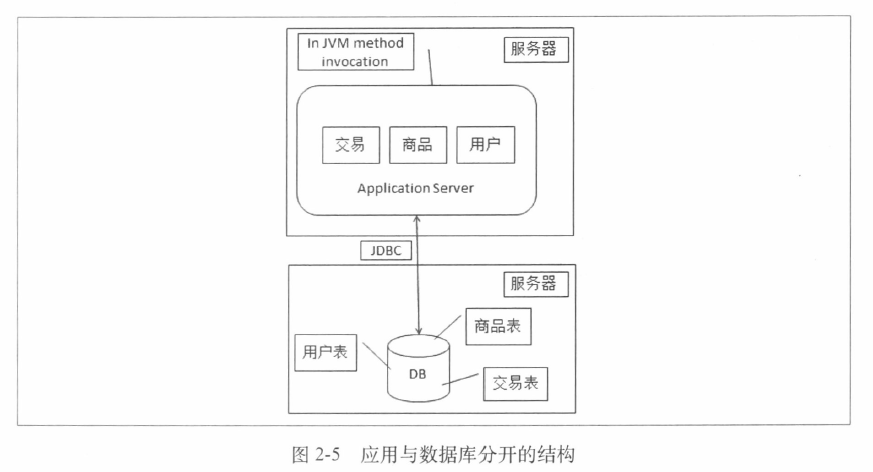
依然采用JDBC连接数据库,只是数据库的地址从本机改成另一台机器的地址。
3.应用服务器负载过大,使用服务器集群
应用服务器压力变大时,可以选择把应用从单机变成集群的优化方式。
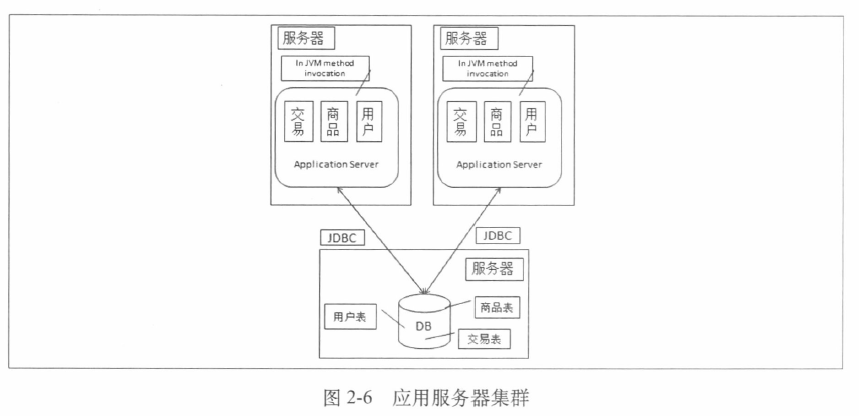
应用服务器从一台变成两台,两者之间没有直接的交互,都是依赖数据库对外提供服务。
那么会存在以下两个问题
1.用户如何选择访问哪个服务器?
- 方法一:使用DNS解决,在用户解析DNS的时候就会被给予一个服务器的地址
- 方法二:在应用服务器集群前添加负载均衡服务设备
2.Session问题
3.1 引入负载均衡设备
我们使用第二种方法来解决访问哪个访问服务器的问题
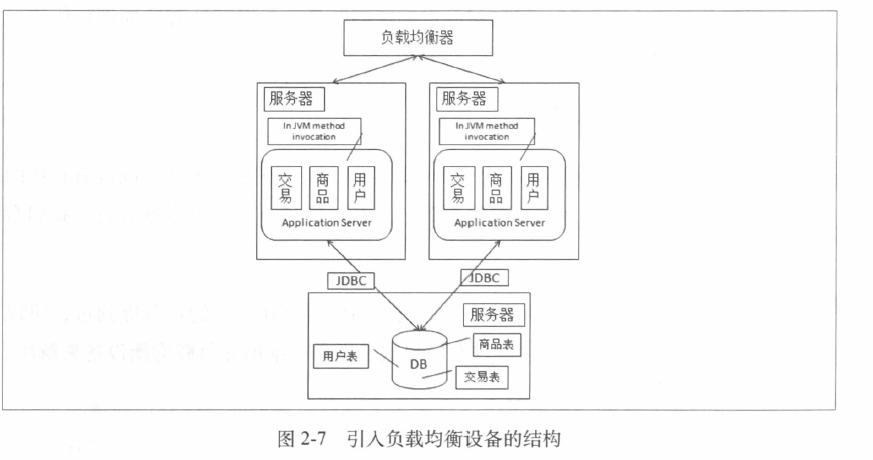
但是这样我们会遇到第二个问题Session问题
3.2 解决Session问题
什么是Session?
用户使用网站的服务,基本需要浏览器与Web服务器进行多次交互。HTTP协议本身是无状态的,需要基于HTTP协议支持会话状态(Session State)的机制,是的服务器可以从多次单独的HTTP请求中看到哪些请求的来自哪个对话。
实现方式:在会话开始之前,分配一个唯一的会话标识(SessionId),通过Cookie把这个标识告诉浏览器,以后每次请求的时候,浏览器都会带上这个会话标识来告诉服务器请求是属于哪个对话的。在服务器上,每个会话有独立的存储,保存不同的会话信息。如果是禁用Cookie可以把会话标识放到URL参数中

所谓的Session问题就是,在应用服务器集群的情况下,如何在HTTP请求的处理过程中找到对应的会话数据。

一般存在以下几种解决方法
1.Session Sticky
保证同一个会话的请求都在同一个服务器上处理,负载均衡器根据每次请求的会话标识来进行转发
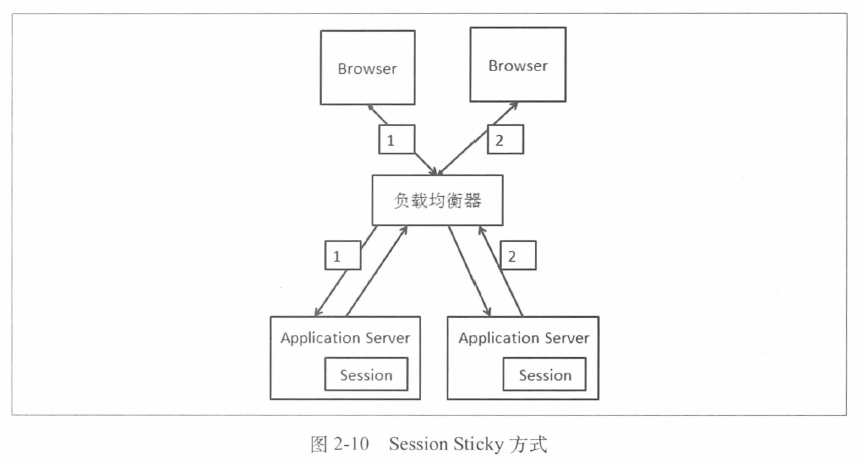
方案简单,但是可能存在以下几个问题。
- 如果一台Web服务器宕机或者重启,那么这台机器上的会话数据就会丢失
- 会话标识是应用层的信息,每次保存都要进行应用层的解析
- 负载均衡器变成了一个由状态的节点,内存消耗更大,容灾也会更麻烦
2. Session Replication
每个服务器都保存有Session数据,使用负载均衡器保证同步
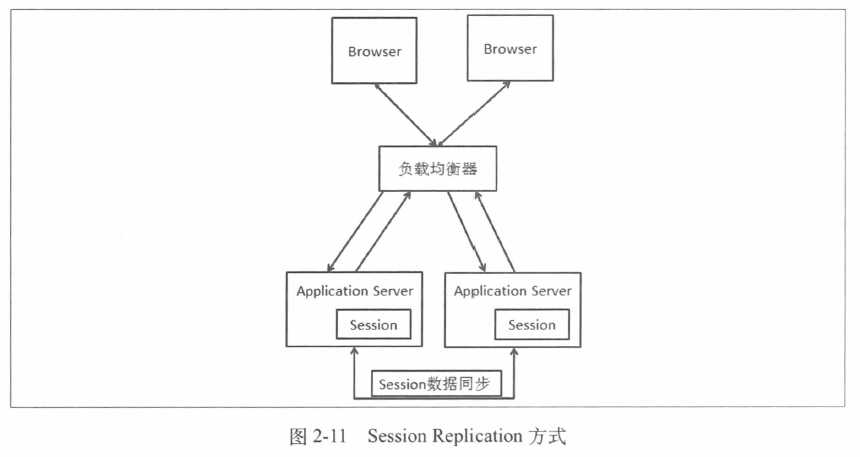
也可能存在一些问题
- 同步Session数据造成网络带宽的开销。只要Session数据变化,就要同步到所有的服务器上,如果机器很多那么带宽消耗会很大
- 每台服务器都要保存所有的Session数据,如果很多人同时访问的话,占用空间会很大
因此该种方案只适合集群数少的情况
3. Session数据集中存储
把Session数据集中存放起来,服务器从该处获取Session
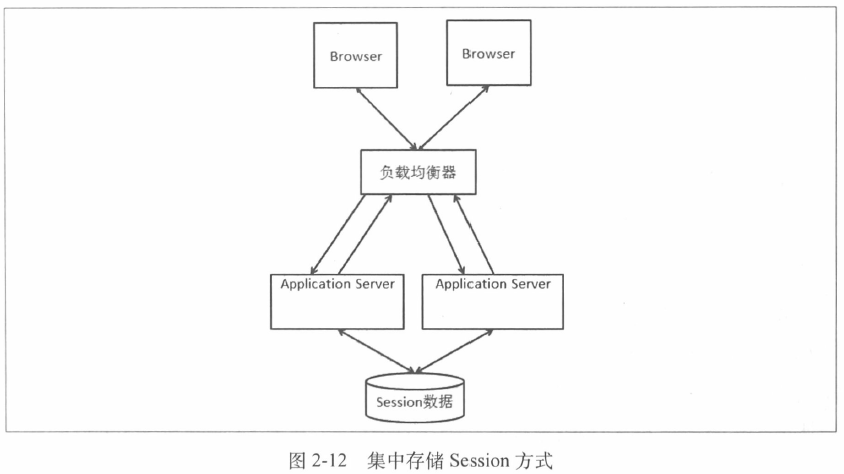
存储Session可以使用数据库或者其他分布式存储系统
当然也存在一些问题:
- 读写Session数据引入了网络操作,因此存在时延和不确定性
- 如果存储Session的机器或者集群出现问题,就会影响应用
4. Cookie Based
把Session数据存在Cookie中,如果在服务器上从Cookie中生成对应的Session数据
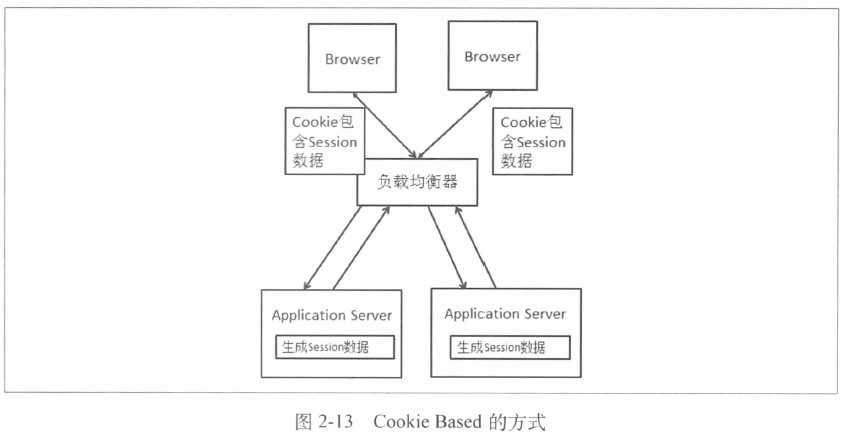
不足就是
- Cookie长度的限制
- 安全性
- 带宽消耗
- 性能影响
* 每次请求和响应都带有Session数据
总结
一般使用Session Sticky和Session集中两种方式
4. 数据压力过大,采用读写分离
4.1 采用数据库作为读库
对于读多写少的业务可以采用读写分离的方式优化
下图加了一个读库只负责读操作
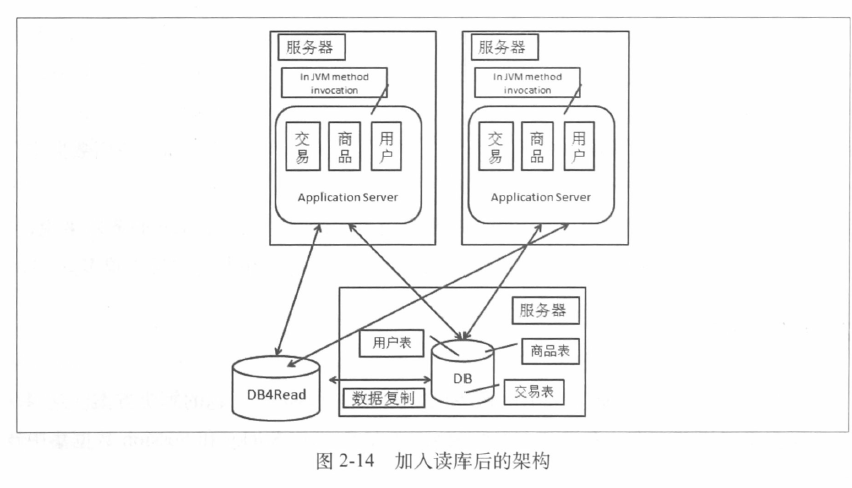
这种结构也会带来两个问题
- 数据复制问题
- 应用对于数据源选择的问题
解决数据库复制的问题,一般可以直接使用数据库的自身机制。MySQL支持主从的结构,提供数据复制的机制,MySQL5.5之前的版本支持异步的复制并且会有延迟,保证主从库的数据一致性,在MySQL5.5之后加入的半同步复制。
解决数据源的问题,写操作要走主库,事务的读也要走主库,同时也要考虑备库数据相对于主库数据的延迟。
4.2 搜索引擎的例子
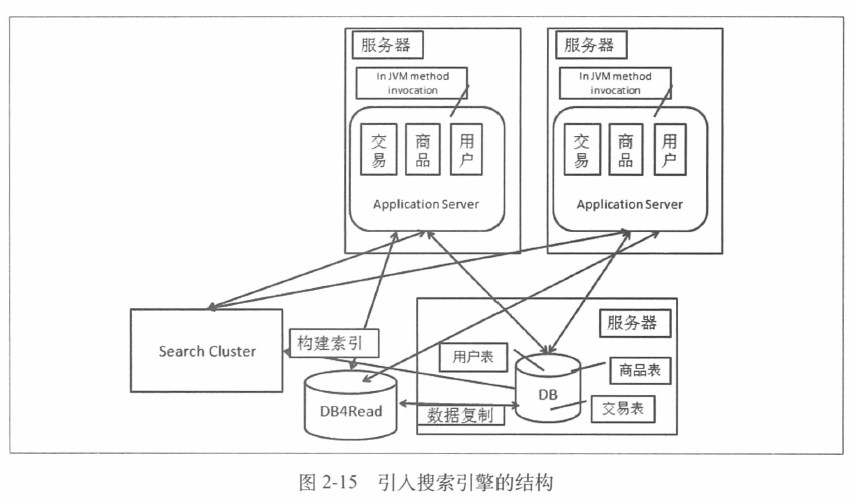
搜索集群的使用方式和读库的使用方式是一样的,只是构建索引的过程基本都是需要自己实现,可以从两个纬度划分,一种按照全量/增量划分,一种按照实时/非实时划分。
全量用于第一次建立索引,而增量用于在全量的基础上持续更新索引。
4.3 使用缓存加速数据读取
1. 数据缓存
大型系统中的数据缓存主要用于分担数据库的读的压力,类似之前提到的分库和搜索引擎
一般缓存中放的是热数据而不是全部数据,填充方式应该通过应用完成,如果数据不存在,就从数据库读出数据后放入缓存。随着时间的推移,当缓存容量不够的时候,最近不被访问的数据就被清除了。
还有一种做法是在数据库的数据发生变化后,主动吧数据放入缓存系统中,保证数据的一致性。
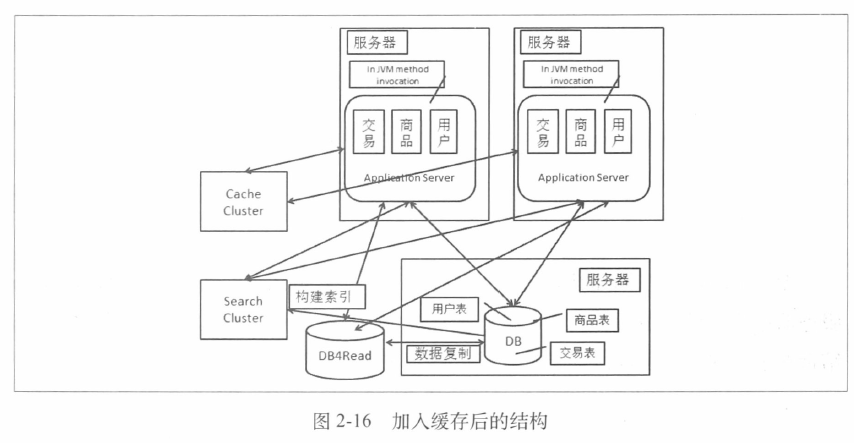
2.页面缓存
除了数据缓存之外还有页面缓存。数据缓存可以加速应用在响应请求时的数据读取速度。但是由于最后返回给用户的还是页面,如果有一些动态生成的页面或者页面的一部分特别热,就可以对这些内容进行缓存。

把渲染和缓存的工作结合在一起
5. 引入分布式存储系统
常见的分布式存储系统有分布式文件系统、分布式Key-Value系统和分布式数据库。
文件系统是大家熟知的,分布式文件系统是在分布式环境中由多个节点组成的功能和单机文件系统一样的文件系统,是弱格式的,内容的格式需要使用者自己来组织。
分布式KV系统会更加格式化一些。
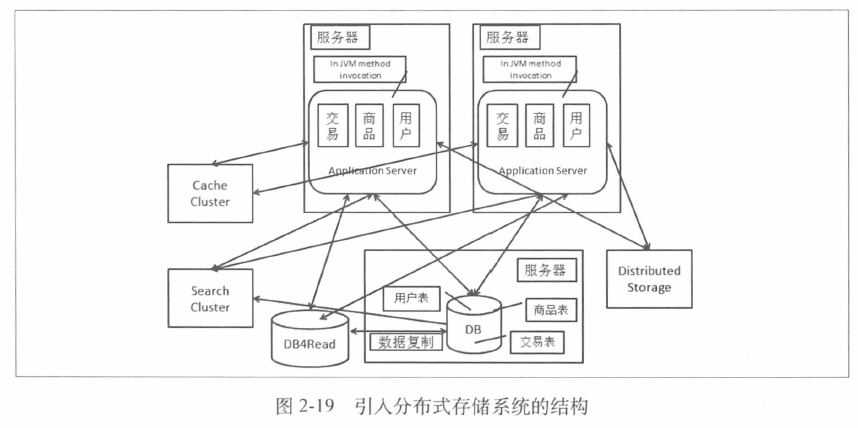
6.读写分离之后的进行水平垂直拆分
解决方法就是数据垂直拆分和水平拆分两种选择
6.1 专库专用 数据垂直拆分
垂直拆分是把数据库中不同的业务数据拆分到不同的数据库中

不同业务的数据从原来的一个数据库中拆分到了多个数据库中,需要考虑如何处理原来单机中跨业务的事务。
一种是使用分布式事务,性能要低于单机事务
另一种是去掉事务,使用表关联查询来实现
6.1 数据水平拆分
水平拆分是把同一个表的数据拆到两个数据库中。产生数据水平拆分的原因是某个事务的数据表的数据量或者更新量达到了单个数据库的瓶颈,就可以把这个表拆到两个或者多个数据库中。
数据水平拆分和读写分离的区别是:
- 读写分离解决的是读压力大的问题,对于数据量大或者更新量的情况不起作用。
- 水平拆分是把同一个表拆到不同的数据库中
水平拆分带来的影响:
- 访问用户信息的时候需要解决SQL路由的问题,因为用户信息分在了两个数据库中,需要了解需要操作的数据在哪里。
- 主键的处理也会不同

7.其他问题
7.1 拆分应用
前面的读写分离,分布式存储,数据垂直拆分和水平拆分都是在解决数据方面的问题,下面看看应用方面的变化。
当应用功能越来越多的时候,可以把一个应用变为两个或者多个应用,有两种方式
第一种,根据业务的特性拆分应用。


7.2 服务化优化
把应用分为三层,处于最上层的WEB系统用于完成不同的业务功能。处于中间的服务中心,不同的服务中心提供不同的业务服务。处于下层的是业务的数据库。

首先,业务功能之间的访问设计到了远程的服务调用,其次共享的代码被放在了各个服务中心,第三,数据库的连接也发生了变化,把数据库的交互中心放到了各个服务中心,让前端的WEB应用更注重和浏览器交互的工作。
最后演进成的结构





























——界面美化")




还没有评论,来说两句吧...