python踩过的一些坑
找完工作,又开始忙于做毕设,很久没更新博客了,不过博客新上线的这个新界面太不好用了,分类下只有两篇文章,每次点击进去都出现很多篇其他类的,每次找一篇博文都要翻很久。体验真是极差。
废话不多说,先记几个做毕设过程中发现的小坑
1、jieba分词生成迭代器,在第二次for循环会失效
测试代码:
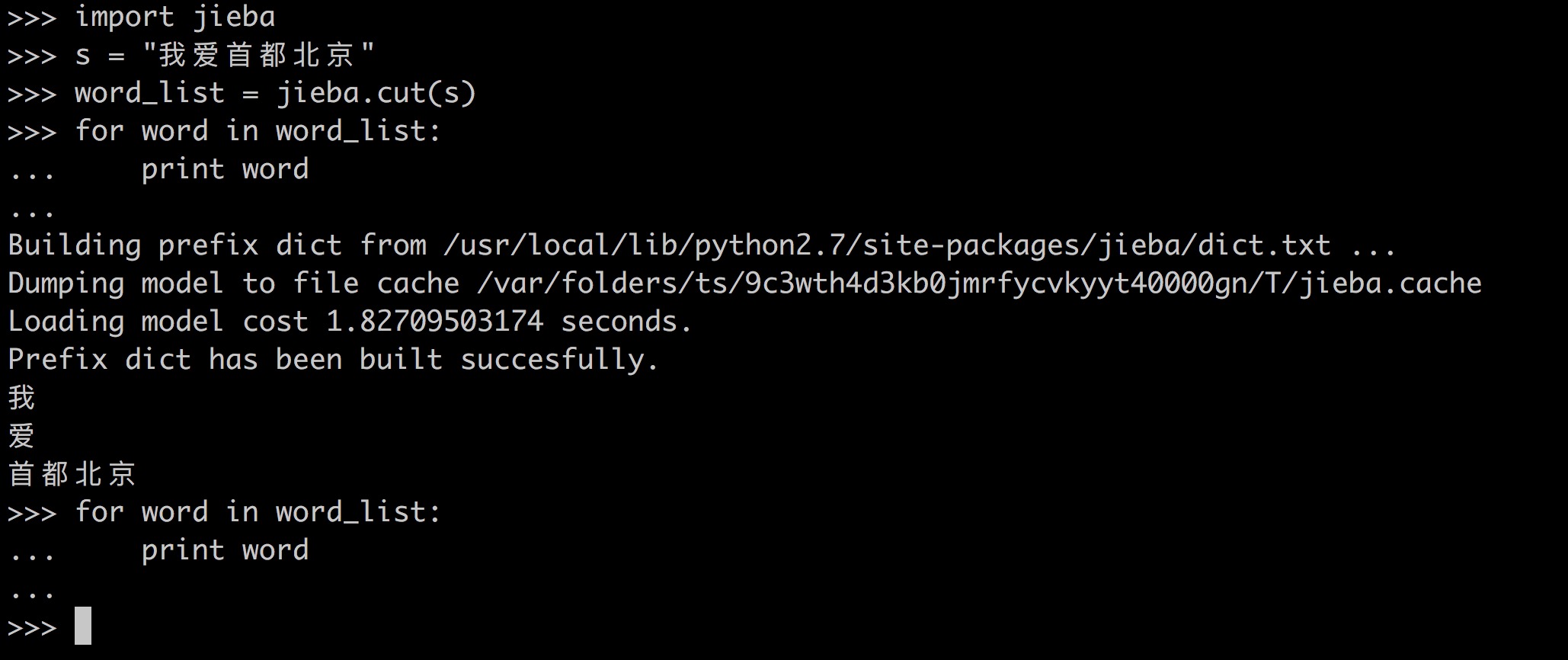
用jieba分词生成的word_list是个迭代器,第二个for里面就已经失效了,所以什么都打印不出来,所以为了让它不失效,用word_list1 = list(word_list)将其转化为list即可。
2、list在生成二维数组时,注意值的浅拷贝
问题发现:
>>> a = [[0] * 3] * 3>>> a[[0, 0, 0], [0, 0, 0], [0, 0, 0]]>>> a[1][1] = 1>>> a[[0, 1, 0], [0, 1, 0], [0, 1, 0]]>>>
创建了一个3*3的二维数组a,初始化所有值都为0,现在想将a[1][1]值改为1,发现所有行的下标为1的值都改为了1
原因:[0]*3是生成一个1*3的一维数组,初始化所有值为0,现在对这个一维数组再*3,企图生成一个二维数组时,实际上用到的是浅拷贝,就是说这三个[0]*3用到的一个内存,所以任何一维数组中有值修改了,另外两个一维数组中对应地方的值都会跟着变(因为用的是一个内存,可以理解为本来就是指向同一个数)。
正确的生成二维数组的方式如下:
>>> a = [[] for i in range(3)]>>> a[[], [], []]>>> a[0].append(0)>>> a[1].append(0)>>> a[2].append(0)>>> a[[0], [0], [0]]>>> a[1][0] = 1>>> a[[0], [1], [0]]
3、在python的工程中,文件的命名千万不要使用包的名字。当你出现报错提示你import的包不存在时,看看你的文件命名是否有问题!
4、处理微博数据时,在遇到表情时,utf-8编码的文本是可以打印出来不报错的,但是在存储到数据库中会报错。这时需要对其进行处理
处理方案是:将其先通过encode转化为gbk编码,因为gbk编码不能表示表情,在转码时会报错。选择errors = ‘ignore’,然后再decode回utf-8,这时文本中表情已经去掉了
str = str.encode("gbk", errors="ignore")str = str.decode("gbk")
在用到
str.encode(encoding='UTF-8',errors='strict')
这个函数时,如果想直接将表情从文本中去掉,选择errors=’ignore’即可。
errors参数如下:
‘ignore’, ‘replace’, ‘xmlcharrefreplace’, ‘backslashreplace’ 以及通过 codecs.register_error() 注册的任何值。
可参考网址:http://www.runoob.com/python/att-string-encode.html


































还没有评论,来说两句吧...