mysql索引优化
索引有什么用处呢?
- 可以提高查询效率
- 可以提高排序效率
- 也可以提高分组效率
我们什么时候使用索引呢?索引是不能随便使用的,单独的索引是没有意义的。
比如:在where条件语句上都加上索引,例如查询第3个栏目,100元以上的商品,where cart_id=3 and price>100,cart_id和price都加索引,这是不正确的,因为在独立的索引中,同时只能用上一个,也就是说,只能用的上cart_id和price其中一个。
因而,我们一般使用多列联合索引,单个索引是没有意义的,但是多列索引是有顺序,就像是一块过河的模板被分成了多块,我们肯定在过河的时候,是按照木板的顺序过河的,决不能决不能少了这一块,而直接走到下一块木板上的。因而,它满足左前缀的要求,比如这个面试题:
比如,我们打开淘宝的官网,一开始不会去查询价格,而是查询标签,以及该标签下某类商品,然后再去查询价格,因而,将price单独作为索引是不合适的,这也就是为什么将(card_id price)作符合索引了。
mysql中的innoDB索引来说:
- 主键索引,级存储索引值,又在叶子节点中存储行的数据
- 如果没有主键(primary key),则unique key会做主键
- 如果没有unique key,则系统生成一个内部的rowID作为主键
- 像innoDB中,主键的索引结构中,既存储了主键值,又存储了行数据,这种结构称为聚簇索引。
聚簇索引和非聚簇索引
当我们在创建表时,可以指明它的索引方式,比如 engine innodb charset utf-8或者engine myisam charset utf-8
聚簇索引针对大文件来说,查询相对来说比较慢,而是用非聚簇索引,查询大文件相对较快。但是我们在创建索引时,可以提高我们的查询效率,但是会影响更新和插入,因而,我们在批量插入数据时,可以暂时禁用索引:
alter table table_name disbale keys
当插入结束后,我们可以解禁索引:
alter table table_name enable keys
如果我们想要了解执行某天语句的具体时间,可以使用:
打开分析工具:set profiling=1 show profiles
在我们进行数据库优化时,适量增加冗余索引,这样避免了回行,从而提高相对效率,但我们怎么来观察索引呢?利用explain,比如:
尾部不加 \G时,即
explain select * from user where u_name=’张三’ 结果是这样的: +——+——————-+———-+——————+———+———————-+———+————- +———+———+—————+——————-+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +——+——————-+———-+——————+———+———————-+———+————- +———+———+—————+——————-+ | 1 | SIMPLE | user | NULL | ALL | NULL | NULL | NULL | NULL | 2 | 50.00 | Using where | +——+——————-+———-+——————+———+———————-+———+————- +———+———+—————+——————-+
如果在尾部加上 \G,即
explain select * from user where u_name=’张三’ \G;
结果是这样的:
* 1. row *id: 1 select 语句的编号 select_type: SIMPLE select语句的类型 table: user tablename partitions: NULL type: ALL 查询类型 possible_keys: NULL 可能用到哪些索引 key: NULL key表示最终用到的索引 key_len: NULL 索引最大长度 ref: NULL 引用 rows: 2 预计查询到的行数 filtered: 50.00 Extra: Using where 使用的条件
ps:select_type的分类情况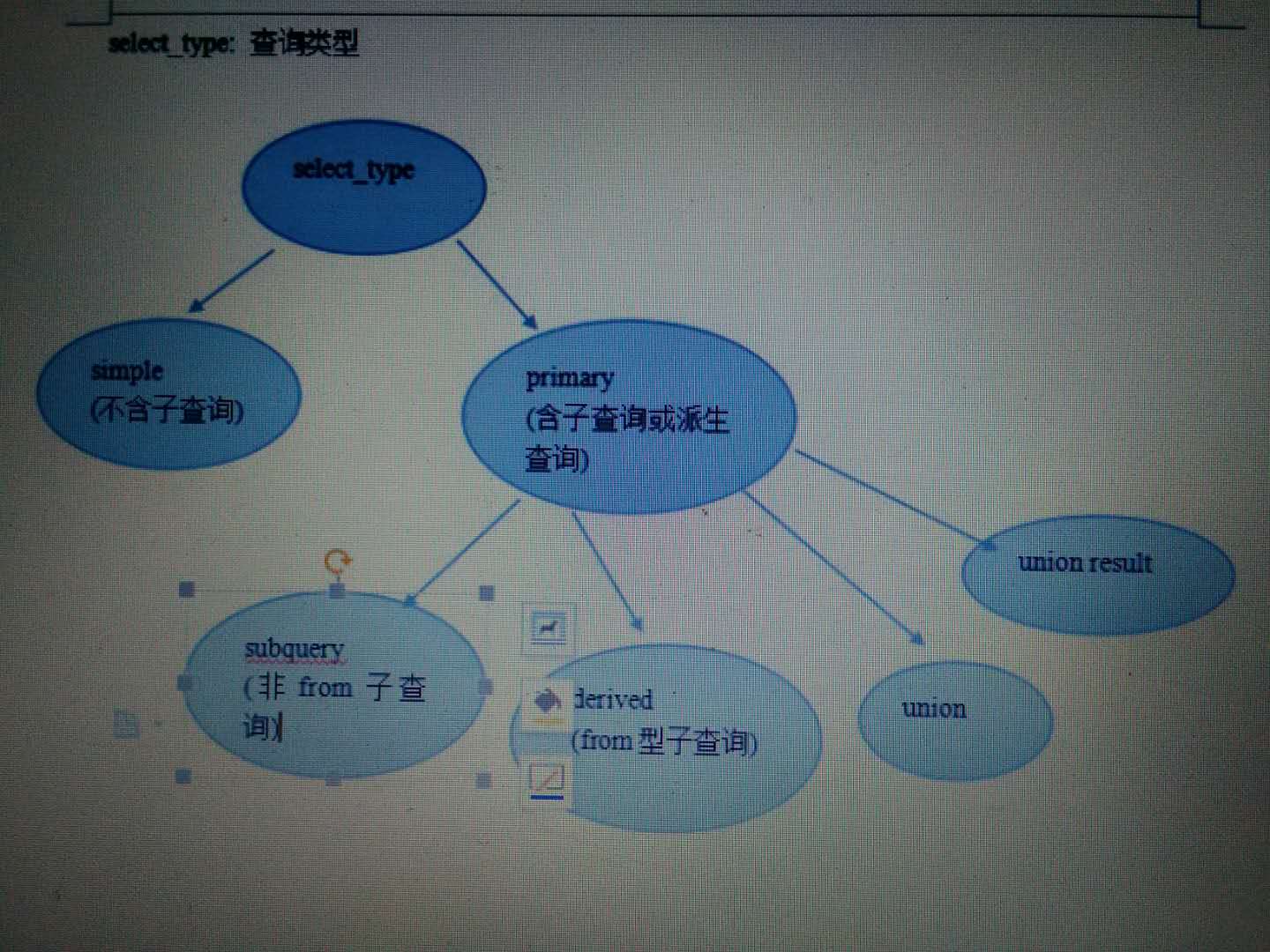
但是,虽有说在索引列上添加函数或列表达式,比如(nunnery=number+1),索引会失效,但有时候我们虽然添加了,但索引没有失效,这是为什么呢?这就要考虑到索引覆盖。
什么是索引覆盖?如果索引包含所有满足查询需要的数据的索引称为覆盖索引(Covering Index),也就是平时所说的不需要回表操作,因而,这个例子是没有考虑到索引覆盖: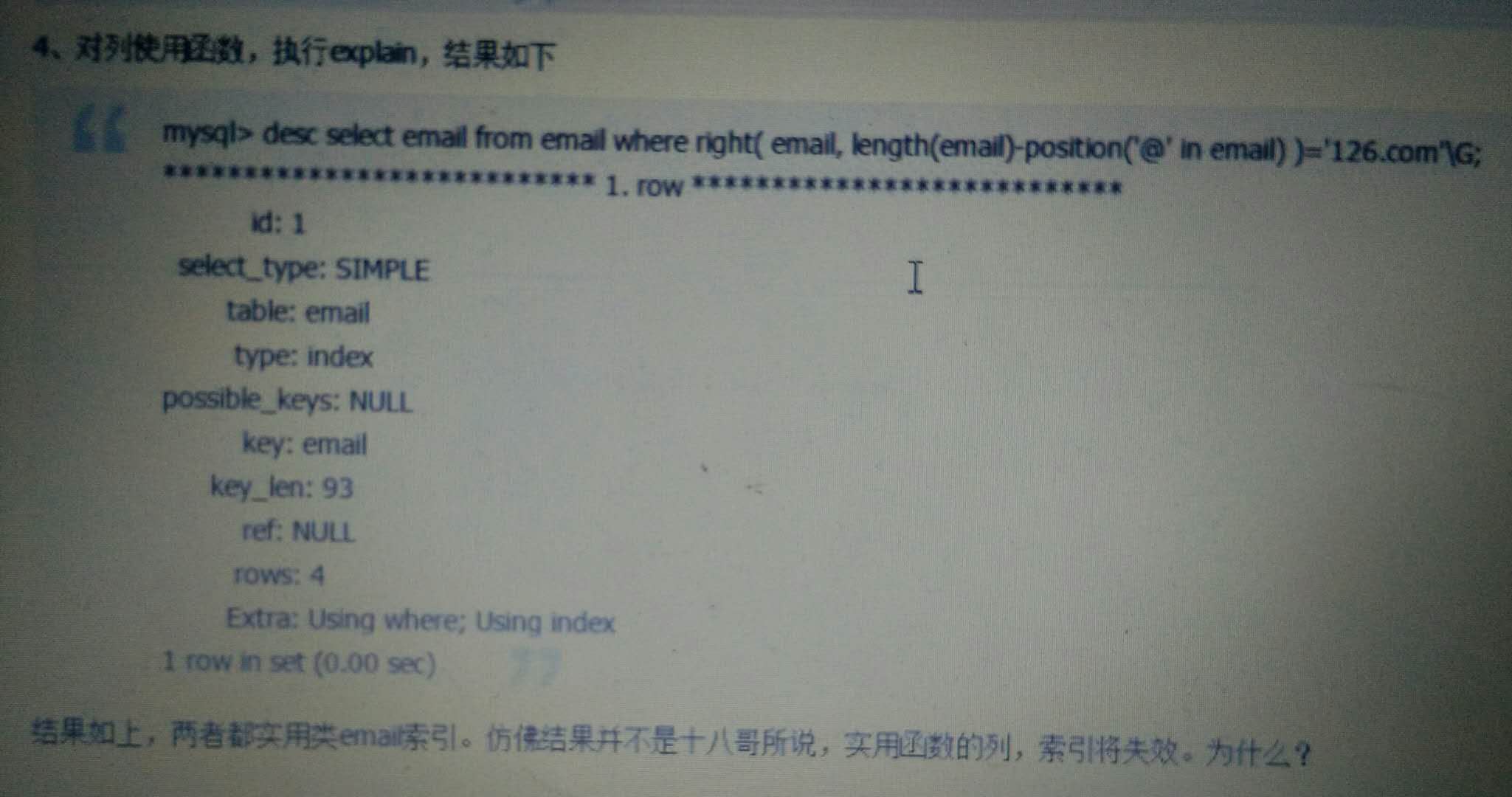
因为该作者在创建数据库时,里面有个email索引,而他查询到的也仅仅查询email的值,我们为什么要加索引,也就是为了不要回表查询,直接在索引树上查询,因而,该查询没有进行回表,因而会有索引值,这也是索引覆盖的效果,如果我们把把语言改成这样:
select eamil,name from email where... 这里就没有索引覆盖,而需要进行回表查询,所以key这里就为null了。
注:如果取出的列含有text类型的数据,或者更大的数据如mediumtext,那么排序将在磁盘上发生,这无疑降低了查询效率,这也违背了建立索引的初衷。怎么查看会有临时发生在磁盘上的呢?我们可以使用以下语句:
mysql> show status like '%tmp%'; +-------------------------+-------+| Variable_name | Value | +-------------------------+-------+| Created_tmp_disk_tables | 0 | | Created_tmp_files | 5 | | Created_tmp_tables | 0 | +-------------------------+-------+ 这是会有两个东西出现: Created_tmp_disk_tables 表示发生在磁盘上的临时表Created_tmp_tables 表示创建的临时表Created_tmp_files 表示创建的临时文件出现这种情况并不好,我们应当尽量避免掉;

























盒子模型,边框,内外边距,盒子模型布局,ps基本操作,列表样式,圆角边框,盒子阴影")








还没有评论,来说两句吧...