Redis哨兵机制
一、什么是哨兵模式
我们知道Redis 在一个主库在对应多个从库的情况下,如果主库出了故障,那么所有的从库都会等待主库恢复,所这种情况是很危险的。哨兵模式是指如果主库出了故障,那么后台监控能够检查出该问题,从而在众多对应的从库中进行投票,产生新的主库,其余原主库的从库都会连接该主库,而不再与之前的主库相连接。
二、哨兵模式应用
因为是在一个虚拟机中进行演示,所以准备了三个Redis 服务,修改对应的文件,用来模拟三台主机。
需要新建一个sentinel.conf 文件,文件语法规则为:
sentinel monitor 被监控数据库名字(自定义名字) 127.0.0.1 6379 票数
启用 redis-sentinel /myredis/sentinel.conf 启动哨兵
过程演示(只监视一个主库)
[1] 开启三个Redis 服务
[root@localhost bin]# ./redis-server /myredis/redis.conf[root@localhost bin]# ./redis-cli -p 6379127.0.0.1:6379>root@localhost bin]# ./redis-server /myredis/redis6380.conf[root@localhost bin]# ./redis-cli -p 6380127.0.0.1:6380>[root@localhost bin]# ./redis-server /myredis/redis6381.conf[root@localhost bin]# ./redis-cli -p 6381127.0.0.1:6381>
[2] 将6380 端口与6381 端口对应的服务设置为6379 的从库
127.0.0.1:6380> SLAVEOF 127.0.0.1 6379OK127.0.0.1:6380>127.0.0.1:6381> SLAVEOF 127.0.0.1 6379OK//查看主库对应的从库信息,配置完成127.0.0.1:6379> INFO REPLICATION# Replicationrole:master //主库connected_slaves:2 //对应两个从库,分别是6380 与6381slave0:ip=127.0.0.1,port=6380,state=online,offset=90030,lag=1slave1:ip=127.0.0.1,port=6381,state=online,offset=90030,lag=2master_repl_offset:90030repl_backlog_active:1repl_backlog_size:1048576repl_backlog_first_byte_offset:2repl_backlog_histlen:90029
[3] 打开一个终端,在redis.conf 配置文件的目录下创建sentinel.conf 文件,用vim 打开进行如下配置
sentinel monitor host6379 127.0.0.1 6379 1
[4] 开启哨兵,对应日志信息如下
[root@localhost bin]# ./redis-sentinel /myredis/sentinel.conf*** FATAL CONFIG FILE ERROR ***Reading the configuration file, at line 1>>> 'entinel monitor host6379 127.0.0.1 6379 1'Bad directive or wrong number of arguments[root@localhost bin]# ./redis-sentinel /myredis/sentinel.conf8874:X 03 Jan 14:16:15.633 * Increased maximum number of open files to 10032 (it was originally set to 1024)._.__.-``__ ''-.__.-`` `. `_. ''-._ Redis 3.0.4 (00000000/0) 64 bit.-`` .-```. ```\/ _.,_ ''-._( ' , .-` | `, ) Running in sentinel mode |`-._`-...-` __...-.``-._|'` _.-'| Port: 26379 | `-._ `._ / _.-' | PID: 8874`-._ `-._ `-./ _.-' _.-'|`-._`-._ `-.__.-' _.-'_.-'| | `-._`-._ _.-'_.-' | http://redis.io `-._ `-._`-.__.-'_.-' _.-'|`-._`-._ `-.__.-' _.-'_.-'| | `-._`-._ _.-'_.-' | `-._ `-._`-.__.-'_.-' _.-'`-._ `-.__.-' _.-'`-._ _.-' `-.__.-'8874:X 03 Jan 14:16:15.721 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.8874:X 03 Jan 14:16:15.721 # Sentinel runid is 6c33484891d59eae4fe90470378486f833c67fb28874:X 03 Jan 14:16:15.721 # +monitor master host6379 127.0.0.1 6379 quorum 18874:X 03 Jan 14:16:16.677 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ host6379 127.0.0.1 63798874:X 03 Jan 14:16:16.693 * +slave slave 127.0.0.1:6381 127.0.0.1 6381 @ host6379 127.0.0.1 6379
[5] 6379 关闭服务,主库被关闭,日志信息发生变化,新的主库产生
127.0.0.1:6379> SHUTDOWNnot connected> exit//当主库退出后,哨兵日志信息发生了变化,经过对两个从库的投票,最后选择 6380 端口对应的服务为主库[root@localhost bin]# ./redis-sentinel /myredis/sentinel.conf8874:X 03 Jan 14:16:15.633 * Increased maximum number of open files to 10032 (it was originally set to 1024)._.__.-``__ ''-.__.-`` `. `_. ''-._ Redis 3.0.4 (00000000/0) 64 bit.-`` .-```. ```\/ _.,_ ''-._( ' , .-` | `, ) Running in sentinel mode |`-._`-...-` __...-.``-._|'` _.-'| Port: 26379 | `-._ `._ / _.-' | PID: 8874`-._ `-._ `-./ _.-' _.-'|`-._`-._ `-.__.-' _.-'_.-'| | `-._`-._ _.-'_.-' | http://redis.io `-._ `-._`-.__.-'_.-' _.-'|`-._`-._ `-.__.-' _.-'_.-'| | `-._`-._ _.-'_.-' | `-._ `-._`-.__.-'_.-' _.-'`-._ `-.__.-' _.-'`-._ _.-' `-.__.-'8874:X 03 Jan 14:16:15.721 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.8874:X 03 Jan 14:16:15.721 # Sentinel runid is 6c33484891d59eae4fe90470378486f833c67fb28874:X 03 Jan 14:16:15.721 # +monitor master host6379 127.0.0.1 6379 quorum 18874:X 03 Jan 14:16:16.677 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ host6379 127.0.0.1 63798874:X 03 Jan 14:16:16.693 * +slave slave 127.0.0.1:6381 127.0.0.1 6381 @ host6379 127.0.0.1 6379sentinel monito8874:X 03 Jan 14:41:54.364 # +sdown master host6379 127.0.0.1 63798874:X 03 Jan 14:41:54.364 # +odown master host6379 127.0.0.1 6379 #quorum 1/18874:X 03 Jan 14:41:54.366 # +new-epoch 18874:X 03 Jan 14:41:54.366 # +try-failover master host6379 127.0.0.1 63798874:X 03 Jan 14:41:54.375 # +vote-for-leader 6c33484891d59eae4fe90470378486f833c67fb2 18874:X 03 Jan 14:41:54.375 # +elected-leader master host6379 127.0.0.1 63798874:X 03 Jan 14:41:54.375 # +failover-state-select-slave master host6379 127.0.0.1 63798874:X 03 Jan 14:41:54.440 # +selected-slave slave 127.0.0.1:6380 127.0.0.1 6380 @ host6379 127.0.0.1 63798874:X 03 Jan 14:41:54.440 * +failover-state-send-slaveof-noone slave 127.0.0.1:6380 127.0.0.1 6380 @ host6379 127.0.0.1 63798874:X 03 Jan 14:41:54.509 * +failover-state-wait-promotion slave 127.0.0.1:6380 127.0.0.1 6380 @ host6379 127.0.0.1 63798874:X 03 Jan 14:41:54.806 # +promoted-slave slave 127.0.0.1:6380 127.0.0.1 6380 @ host6379 127.0.0.1 63798874:X 03 Jan 14:41:54.806 # +failover-state-reconf-slaves master host6379 127.0.0.1 63798874:X 03 Jan 14:41:54.885 * +slave-reconf-sent slave 127.0.0.1:6381 127.0.0.1 6381 @ host6379 127.0.0.1 63798874:X 03 Jan 14:41:55.861 * +slave-reconf-inprog slave 127.0.0.1:6381 127.0.0.1 6381 @ host6379 127.0.0.1 63798874:X 03 Jan 14:41:56.934 * +slave-reconf-done slave 127.0.0.1:6381 127.0.0.1 6381 @ host6379 127.0.0.1 63798874:X 03 Jan 14:41:57.022 # +failover-end master host6379 127.0.0.1 63798874:X 03 Jan 14:41:57.024 # +switch-master host6379 127.0.0.1 6379 127.0.0.1 63808874:X 03 Jan 14:41:57.032 * +slave slave 127.0.0.1:6381 127.0.0.1 6381 @ host6379 127.0.0.1 63808874:X 03 Jan 14:41:57.039 * +slave slave 127.0.0.1:6379 127.0.0.1 6379 @ host6379 127.0.0.1 63808874:X 03 Jan 14:42:27.039 # +sdown slave 127.0.0.1:6379 127.0.0.1 6379 @ host6379 127.0.0.1 6380
[6] 查看6380 端口,与6381 端口,6380 由原来的从库变成了主库,6381 对应的主库也发生了变化
127.0.0.1:6380> INFO REPLICATION# Replicationrole:master //由从库变成了主库connected_slaves:1 //现在只有一个从库6381slave0:ip=127.0.0.1,port=6381,state=online,offset=5190,lag=0master_repl_offset:5190repl_backlog_active:1repl_backlog_size:1048576repl_backlog_first_byte_offset:2repl_backlog_histlen:5189127.0.0.1:6381> INFO REPLICATION# Replicationrole:slave //由于投票决定还是从库master_host:127.0.0.1master_port:6380 //主库由原来的6379 变成了6380master_link_status:upmaster_last_io_seconds_ago:1master_sync_in_progress:0slave_repl_offset:5736slave_priority:100slave_read_only:1connected_slaves:0master_repl_offset:0repl_backlog_active:0repl_backlog_size:1048576repl_backlog_first_byte_offset:0repl_backlog_histlen:0
[7] 如果原主库6379 恢复了正常,那么它将变成新主库的从库
[root@localhost bin]# ./redis-server /myredis/redis.conf[root@localhost bin]# ./redis-cli -p 6379127.0.0.1:6379> INFO REPLICATION# Replicationrole:slave // 由故障前的主库变成了从库master_host:127.0.0.1 //对应的主库为投票出来的6380master_port:6380master_link_status:upmaster_last_io_seconds_ago:2master_sync_in_progress:0slave_repl_offset:34543slave_priority:100slave_read_only:1connected_slaves:0master_repl_offset:0repl_backlog_active:0repl_backlog_size:1048576repl_backlog_first_byte_offset:0repl_backlog_histlen:0
三、图解
为了更好理解,对这个过程画了图解,如果有不正确的地方还望大家指正。
一开始一个主库对应着两个从库,正常的工作着。
主库挂掉之后,新的主库产生。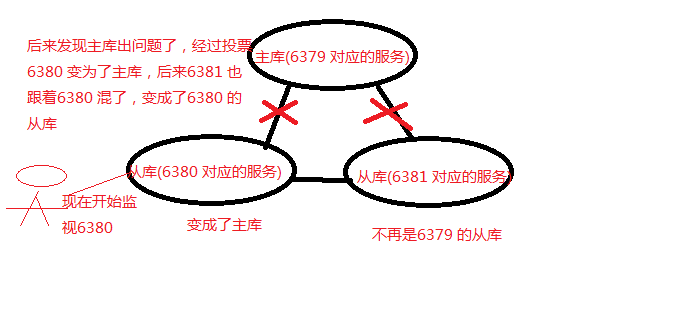
后来出故障的主库恢复了正常,发现却不再是主库。
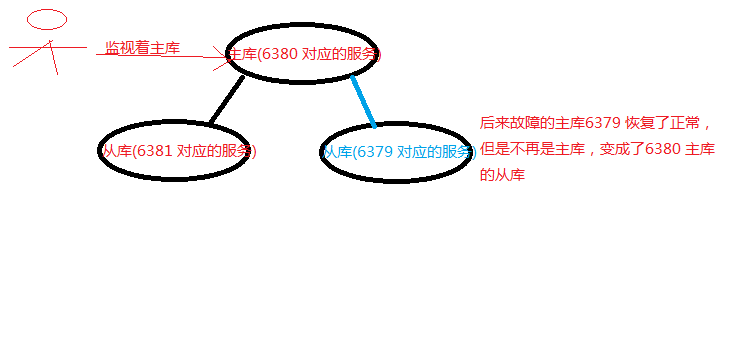
同理如果主库6380 端口对应的服务出故障,那么将会在6379 与6381 从库中重新选出主库。


































还没有评论,来说两句吧...