oracle 表分区
oracle大数据表建分区优缺点
oracle给出的建议是按照表的大小给出的,10g的建议是2G,也就是说表的大小大于2G,那么就最好建立分区。
为什么要建立分区?主要是为了查询方便,因为如果一个表每天都有百万条记录,那么即使建立了索引,那么你要查的话,也不会很快的。
如果你建立了分区,每次查询一个分区,也就是这张表的几分之一,甚至几十分之一,那么不管怎么计算都比你查询整张表的消耗要少。而且在分区上也能建立索引的。
分区的建立最好一个原则,就是查询,这个要具体问题具体分析,有些分区的方式虽然条数不错,不过每次查询要跨越2-3个分区,这样的分区其实个人认为比较失败的。最好把最常用的查询限定在一个分区内,而且分区的条数不能过少(这个没有具体的要求,一般oracle是按照大小建议的,我忘了是多少了,还是那句话,看你的需求)
优点:
增强可用性:如果表的某个分区出现故障,表在其他分区的数据仍然可用;
维护方便:如果表的某个分区出现故障,需要修复数据,只修复该分区即可;
均衡I/O:可以把不同的分区映射到磁盘以平衡I/O,改善整个系统性能;
改善查询性能:对分区对象的查询可以仅搜索自己关心的分区,提高检索速度。
缺点:
分区表相关:已经存在的表没有方法可以直接转化为分区表。不过Oracle 提供了在线重定义表的功能。
或者 下面这种解决方法
- 基础表的数据量大,查询的时候尽量避免原表扫描,可以考虑使用中间表或者物化视图,比如你要查询每年表中的用户数,可以把每一月统计的结果放在中间表,然后累加,
思想就是把大的查询拆分为若干小的查询。
2.在夜间执行一些job,生成中间表的数据,方便第2天查询。
3.如果表中数据特别多,可以考虑水平切分表(下面详解),比如表中有2000w条记录,则拆分成两个结构一样的表,每一个标存在1000w条数据。
4.索引的选择。在设计表的时候就要考虑是否需要索引,不要等数据量多了再考虑。
5.还有表分区需要考虑~~~~
oracle的 分表 详解 ——-表分区
设置表分区:根据 日期+公司编码(很多公司)建表分区
此文从以下几个方面来整理关于分区表的概念及操作:
1.表空间及分区表的概念2.表分区的具体作用3.表分区的优缺点4.表分区的几种类型及操作方法5.对表分区的维护性操作.
(1.) 表空间及分区表的概念
表空间:
是一个或多个数据文件的集合,所有的数据对象都存放在指定的表空间中,但主要存放的是表, 所以称作表空间。
分区表:
当表中的数据量不断增大,查询数据的速度就会变慢,应用程序的性能就会下降,这时就应该考虑对表进行分区。表进行分区后,逻辑上表仍然是一张完整的表,只是将表中的数据在物理上存放到多个表空间(物理文件上),这样查询数据时,不至于每次都扫描整张表。
( 2).表分区的具体作用
Oracle的表分区功能通过改善可管理性、性能和可用性,从而为各式应用程序带来了极大的好处。通常,分区可以使某些查询以及维护操作的性能大大提高。此外,分区还可以极大简化常见的管理任务,分区是构建千兆字节数据系统或超高可用性系统的关键工具。
分区功能能够将表、索引或索引组织表进一步细分为段,这些数据库对象的段叫做分区。每个分区有自己的名称,还可以选择自己的存储特性。从数据库管理员的角度来看,一个分区后的对象具有多个段,这些段既可进行集体管理,也可单独管理,这就使数据库管理员在管理分区后的对象时有相当大的灵活性。但是,从应用程序的角度来看,分区后的表与非分区表完全相同,使用 SQL DML 命令访问分区后的表时,无需任何修改。
什么时候使用分区表:
1、表的大小超过2GB。
2、表中包含历史数据,新的数据被增加都新的分区中。
(3).表分区的优缺点
表分区有以下优点:
1、改善查询性能:对分区对象的查询可以仅搜索自己关心的分区,提高检索速度。
2、增强可用性:如果表的某个分区出现故障,表在其他分区的数据仍然可用;
3、维护方便:如果表的某个分区出现故障,需要修复数据,只修复该分区即可;
4、均衡I/O:可以把不同的分区映射到磁盘以平衡I/O,改善整个系统性能。
缺点:
分区表相关:已经存在的表没有方法可以直接转化为分区表。不过 Oracle 提供了在线重定义表的功能。
(4).表分区的几种类型及操作方法
一.范围分区:
范围分区将数据基于范围映射到每一个分区,这个范围是你在创建分区时指定的分区键决定的。这种分区方式是最为常用的,并且分区键经常采用日期。举个例子:你可能会将销售数据按照月份进行分区。
当使用范围分区时,请考虑以下几个规则:
1、每一个分区都必须有一个VALUES LESS THEN子句,它指定了一个不包括在该分区中的上限值。分区键的任何值等于或者大于这个上限值的记录都会被加入到下一个高一些的分区中。
2、所有分区,除了第一个,都会有一个隐式的下限值,这个值就是此分区的前一个分区的上限值。
3、在最高的分区中,MAXVALUE被定义。MAXVALUE代表了一个不确定的值。这个值高于其它分区中的任何分区键的值,也可以理解为高于任何分区中指定的VALUE LESS THEN的值,同时包括空值。
例一:
假设有一个CUSTOMER表,表中有数据200000行,我们将此表通过CUSTOMER_ID进行分区,每个分区存储100000行,我们将每个分区保存到单独的表空间中,这样数据文件就可以跨越多个物理磁盘。下面是创建表和分区的代码,如下:
CREATE TABLE CUSTOMER
(
CUSTOMER_ID NUMBER NOT NULL PRIMARY KEY,
FIRST_NAME VARCHAR2(30) NOT NULL,
LAST_NAME VARCHAR2(30) NOT NULL,
PHONE VARCHAR2(15) NOT NULL,
EMAIL VARCHAR2(80),
STATUS CHAR(1)
)
PARTITION BY RANGE (CUSTOMER_ID)
(
PARTITION CUS_PART1 VALUES LESS THAN (100000) TABLESPACE CUS_TS01,
PARTITION CUS_PART2 VALUES LESS THAN (200000) TABLESPACE CUS_TS02
)
例二:按时间划分
CREATE TABLE ORDER_ACTIVITIES
(
ORDER_ID NUMBER(7) NOT NULL,
ORDER_DATE DATE,
TOTAL_AMOUNT NUMBER,
CUSTOTMER_ID NUMBER(7),
PAID CHAR(1)
)
PARTITION BY RANGE (ORDER_DATE)
(
PARTITION ORD_ACT_PART01 VALUES LESS THAN (TO_DATE(‘01- MAY -2003’,’DD-MON-YYYY’)) TABLESPACEORD_TS01,
PARTITION ORD_ACT_PART02 VALUES LESS THAN (TO_DATE(‘01-JUN-2003’,’DD-MON-YYYY’)) TABLESPACE ORD_TS02,
PARTITION ORD_ACT_PART02 VALUES LESS THAN (TO_DATE(‘01-JUL-2003’,’DD-MON-YYYY’)) TABLESPACE ORD_TS03
)
例三:MAXVALUE
CREATE TABLE RangeTable
(
idd INT PRIMARY KEY ,
iNAME VARCHAR(10),
grade INT
)
PARTITION BY RANGE (grade)
(
PARTITION part1 VALUES LESS THEN (1000) TABLESPACE Part1_tb,
PARTITION part2 VALUES LESS THEN (MAXVALUE) TABLESPACE Part2_tb
);
二.列表分区:
该分区的特点是某列的值只有几个,基于这样的特点我们可以采用列表分区。
例一
CREATE TABLE PROBLEM_TICKETS
(
PROBLEM_ID NUMBER(7) NOT NULL PRIMARY KEY,
DESCRIPTION VARCHAR2(2000),
CUSTOMER_ID NUMBER(7) NOT NULL,
DATE_ENTERED DATE NOT NULL,
STATUS VARCHAR2(20)
)
PARTITION BY LIST (STATUS)
(
PARTITION PROB_ACTIVE VALUES (‘ACTIVE’) TABLESPACE PROB_TS01,
PARTITION PROB_INACTIVE VALUES (‘INACTIVE’) TABLESPACE PROB_TS02
例二
CREATE TABLE ListTable
(
id INT PRIMARY KEY ,
name VARCHAR (20),
area VARCHAR (10)
)
PARTITION BY LIST (area)
(
PARTITION part1 VALUES (‘guangdong’,’beijing’) TABLESPACE Part1_tb,
PARTITION part2 VALUES (‘shanghai’,’nanjing’) TABLESPACE Part2_tb
);
)
三.散列分区:
这类分区是在列值上使用散列算法,以确定将行放入哪个分区中。当列的值没有合适的条件时,建议使用散列分区。
散列分区为通过指定分区编号来均匀分布数据的一种分区类型,因为通过在I/O设备上进行散列分区,使得这些分区大小一致。
例一:
CREATE TABLE HASH_TABLE
(
COL NUMBER(8),
INF VARCHAR2(100)
)
PARTITION BY HASH (COL)
(
PARTITION PART01 TABLESPACE HASH_TS01,
PARTITION PART02 TABLESPACE HASH_TS02,
PARTITION PART03 TABLESPACE HASH_TS03
)
简写:
CREATE TABLE emp
(
empno NUMBER (4),
ename VARCHAR2 (30),
sal NUMBER
)
PARTITION BY HASH (empno) PARTITIONS 8
STORE IN (emp1,emp2,emp3,emp4,emp5,emp6,emp7,emp8);
hash分区最主要的机制是根据hash算法来计算具体某条纪录应该插入到哪个分区中,hash算法中最重要的是hash函数,Oracle中如果你要使用hash分区,只需指定分区的数量即可。建议分区的数量采用2的n次方,这样可以使得各个分区间数据分布更加均匀。
四.组合范围散列分区
这种分区是基于范围分区和列表分区,表首先按某列进行范围分区,然后再按某列进行列表分区,分区之中的分区被称为子分区。
CREATE TABLE SALES
(
PRODUCT_ID VARCHAR2(5),
SALES_DATE DATE,
SALES_COST NUMBER(10),
STATUS VARCHAR2(20)
)
PARTITION BY RANGE(SALES_DATE) SUBPARTITION BY LIST (STATUS)
(
PARTITION P1 VALUES LESS THAN(TO_DATE(‘2003-01-01’,’YYYY-MM-DD’))TABLESPACE rptfact2009
(
SUBPARTITION P1SUB1 VALUES (‘ACTIVE’) TABLESPACE rptfact2009,
SUBPARTITION P1SUB2 VALUES (‘INACTIVE’) TABLESPACE rptfact2009
),
PARTITION P2 VALUES LESS THAN (TO_DATE(‘2003-03-01’,’YYYY-MM-DD’)) TABLESPACE rptfact2009
(
SUBPARTITION P2SUB1 VALUES (‘ACTIVE’) TABLESPACE rptfact2009,
SUBPARTITION P2SUB2 VALUES (‘INACTIVE’) TABLESPACE rptfact2009
)
)
五.复合范围散列分区:
这种分区是基于范围分区和散列分区,表首先按某列进行范围分区,然后再按某列进行散列分区。
create table dinya_test
(
transaction_id number primary key,
item_id number(8) not null,
item_description varchar2(300),
transaction_date date
)
partition by range(transaction_date)subpartition by hash(transaction_id) subpartitions 3 store in (dinya_space01,dinya_space02,dinya_space03)
(
partition part_01 values less than(to_date(‘2006-01-01’,’yyyy-mm-dd’)),
partition part_02 values less than(to_date(‘2010-01-01’,’yyyy-mm-dd’)),
partition part_03 values less than(maxvalue)
);
(5).有关表分区的一些维护性操作:
一、添加分区
以下代码给SALES表添加了一个P3分区
ALTER TABLE SALES ADD PARTITION P3 VALUES LESS THAN(TO_DATE(‘2003-06-01’,’YYYY-MM-DD’));
注意:以上添加的分区界限应该高于最后一个分区界限。
以下代码给SALES表的P3分区添加了一个P3SUB1子分区
ALTER TABLE SALES MODIFY PARTITION P3 ADD SUBPARTITION P3SUB1 VALUES(‘COMPLETE’);
二、删除分区
以下代码删除了P3表分区:
ALTER TABLE SALES DROP PARTITION P3;
在以下代码删除了P4SUB1子分区:
ALTER TABLE SALES DROP SUBPARTITION P4SUB1;
注意:如果删除的分区是表中唯一的分区,那么此分区将不能被删除,要想删除此分区,必须删除表。
三、截断分区
截断某个分区是指删除某个分区中的数据,并不会删除分区,也不会删除其它分区中的数据。当表中即使只有一个分区时,也可以截断该分区。通过以下代码截断分区:
ALTER TABLE SALES TRUNCATE PARTITION P2;
通过以下代码截断子分区:
ALTER TABLE SALES TRUNCATE SUBPARTITION P2SUB2;
四、合并分区
合并分区是将相邻的分区合并成一个分区,结果分区将采用较高分区的界限,值得注意的是,不能将分区合并到界限较低的分区。以下代码实现了P1 P2分区的合并:
ALTER TABLE SALES MERGE PARTITIONS P1,P2 INTO PARTITION P2;
五、拆分分区
拆分分区将一个分区拆分两个新分区,拆分后原来分区不再存在。注意不能对HASH类型的分区进行拆分。
ALTER TABLE SALES SBLIT PARTITION P2 AT(TO_DATE(‘2003-02-01’,’YYYY-MM-DD’)) INTO (PARTITION P21,PARTITION P22);
六、接合分区(coalesca)
结合分区是将散列分区中的数据接合到其它分区中,当散列分区中的数据比较大时,可以增加散列分区,然后进行接合,值得注意的是,接合分区只能用于散列分区中。通过以下代码进行接合分区:
ALTER TABLE SALES COALESCA PARTITION;
七、重命名表分区
以下代码将P21更改为P2
ALTER TABLE SALES RENAME PARTITION P21 TO P2;
八、相关查询
跨分区查询
select sum( *) from
(select count(*) cn from t_table_SS PARTITION (P200709_1)
union all
select count(*) cn from t_table_SS PARTITION (P200709_2)
);
查询表上有多少分区
SELECT * FROM useR_TAB_PARTITIONS WHERE TABLE_NAME=’tableName’
查询索引信息
select object_name,object_type,tablespace_name,sum(value)
from v$segment_statistics
where statistic_name IN (‘physical reads’,’physical write’,’logical reads’)and object_type=’INDEX’
group by object_name,object_type,tablespace_name
order by 4 desc
--显示数据库所有分区表的信息:
select * from DBA_PART_TABLES
--显示当前用户可访问的所有分区表信息:
select * from ALL_PART_TABLES
--显示当前用户所有分区表的信息:
select * from USER_PART_TABLES
--显示表分区信息 显示数据库所有分区表的详细分区信息:
select * from DBA_TAB_PARTITIONS
--显示当前用户可访问的所有分区表的详细分区信息:
select * from ALL_TAB_PARTITIONS
--显示当前用户所有分区表的详细分区信息:
select * from USER_TAB_PARTITIONS
--显示子分区信息 显示数据库所有组合分区表的子分区信息:
select * from DBA_TAB_SUBPARTITIONS
--显示当前用户可访问的所有组合分区表的子分区信息:
select * from ALL_TAB_SUBPARTITIONS
--显示当前用户所有组合分区表的子分区信息:
select * from USER_TAB_SUBPARTITIONS
--显示分区列 显示数据库所有分区表的分区列信息:
select * from DBA_PART_KEY_COLUMNS
--显示当前用户可访问的所有分区表的分区列信息:
select * from ALL_PART_KEY_COLUMNS
--显示当前用户所有分区表的分区列信息:
select * from USER_PART_KEY_COLUMNS
--显示子分区列 显示数据库所有分区表的子分区列信息:
select * from DBA_SUBPART_KEY_COLUMNS
--显示当前用户可访问的所有分区表的子分区列信息:
select * from ALL_SUBPART_KEY_COLUMNS
--显示当前用户所有分区表的子分区列信息:
select * from USER_SUBPART_KEY_COLUMNS
--怎样查询出oracle数据库中所有的的分区表
select * from user_tables a where a.partitioned=’YES’
--删除一个表的数据是
truncate table table_name;
--删除分区表一个分区的数据是
alter table table_name truncate partition p5;
oracle分区表按时间自动创建
表分区是一种思想,分区表示一种技术实现。当表的大小过G的时候可以考虑进行表分区,提高查询效率,均衡IO。oracle分区表是oracle数据库提供的一种表分区的实现形式。表进行分区后,逻辑上仍然是一张表,原来的查询SQL同样生效,同时可以采用使用分区查询来优化SQL查询效率,不至于每次都扫描整个表。
根据年: INTERVAL(NUMTOYMINTERVAL(1,’YEAR’))
根据月: INTERVAL(NUMTOYMINTERVAL(1,’MONTH’))
根据天: INTERVAL(NUMTODSINTERVAL(1,’DAY’))
根据时分秒: NUMTODSINTERVAL( n, { ‘DAY’|’HOUR’|’MINUTE’|’SECOND’})
此时已经有普通表了,我创建了含相同字段的分区表,把数据导入到分区表中,再把原表删掉。
-- Create table(WMS_OPERATION_RECORD)create table DPHOMEWMS.WMS_OPERATION_RECORD_TMP
(
ID NUMBER(19) not null,
WAREHOUSE_ID NUMBER(19),
ASN_ID NUMBER(19),
PICK_TICKET_ID NUMBER(19),
RELATION_CODE VARCHAR2(50),
OPERATION_TYPE VARCHAR2(50),
OPERATION_ID NUMBER(19),
OPERATION_NAME VARCHAR2(50 CHAR),
OPERATION_TIME TIMESTAMP(6) DEFAULT systimestamp not null,
STATUS VARCHAR2(10),
TYPE VARCHAR2(10),
COUNTS NUMBER(10)
)tablespace DPHOMEWMS_DATA
PARTITION BY RANGE (OPERATION_TIME) interval (numtoyminterval(1, ‘month’))
STORE IN (DPHOMEWMS_DATA)
(
partition OPERATION_RECORD_P01 values less than (TIMESTAMP’ 2017-05-08 00:00:00’)
tablespace DPHOMEWMS_DATA
);-- Add comments to the columns
comment on column DPHOMEWMS.WMS_OPERATION_RECORD_TMP.WAREHOUSE_ID
is ‘仓库id’;
comment on column DPHOMEWMS.WMS_OPERATION_RECORD_TMP.ASN_ID
is ‘收货单id’;
comment on column DPHOMEWMS.WMS_OPERATION_RECORD_TMP.PICK_TICKET_ID
is ‘发货单ID’;
comment on column DPHOMEWMS.WMS_OPERATION_RECORD_TMP.RELATION_CODE
is ‘关联单据号(收货单或发货单的code)’;
comment on column DPHOMEWMS.WMS_OPERATION_RECORD_TMP.OPERATION_TYPE
is ‘操作类型’;
comment on column DPHOMEWMS.WMS_OPERATION_RECORD_TMP.OPERATION_ID
is ‘操作人ID’;
comment on column DPHOMEWMS.WMS_OPERATION_RECORD_TMP.OPERATION_NAME
is ‘操作人名称’;
comment on column DPHOMEWMS.WMS_OPERATION_RECORD_TMP.OPERATION_TIME
is ‘操作时间’;
comment on column DPHOMEWMS.WMS_OPERATION_RECORD_TMP.STATUS
is ‘状态’;
comment on column DPHOMEWMS.WMS_OPERATION_RECORD_TMP.TYPE
is ‘明细或者统计次数类型’;
comment on column DPHOMEWMS.WMS_OPERATION_RECORD_TMP.COUNTS
is ‘统计次数’;--创建本地索引create index IDX_WMS_OPERATION_RECORD on DPHOMEWMS.WMS_OPERATION_RECORD_TMP(RELATION_CODE)
tablespace DPHOMEWMS_INDEX local;update DPHOMEWMS.WMS_OPERATION_RECORD set OPERATION_TIME = sysdate where OPERATION_TIME is null;insert into DPHOMEWMS.WMS_OPERATION_RECORD_TMP select * from WMS_OPERATION_RECORD;drop table DPHOMEWMS.WMS_OPERATION_RECORD;alter table DPHOMEWMS.WMS_OPERATION_RECORD_TMP rename to WMS_OPERATION_RECORD;alter table DPHOMEWMS.WMS_OPERATION_RECORD enable row movement;
(1)OPERATION_TIME是分区键,每一个月会自动创建一个分区,分区键不允许为null。
(2)alter table table_name enable row movement; 是指允许分区表的分区键是可更新,当某一行更新时,如果更新的是分区列,并且更新后的列值不属于原来的这个分区,如果开启了这个选项,就会把这行从这个分区中delete掉,并加到更新后所属的分区,此时就会发生rowid的改变。相当于一个隐式的delete+insert,但是不会触发insert/delete触发器。如果没有开启这个选项,就会在更新时报错。
oracle定期生成和删除表分区
在项目中我们有个一个表是秒数据表,这个表每天插入的数据量都有800多万条,所以我们只存储一段时间的数据,半个月之前的数据就会删除掉,这样当我们查询当前即时的数据来绘制图表的时候就会出现问题:Oralce的高水位线的问题。
至于什么是高水位线问题,大家可以百度下,这里摘抄一段:
在oracle里,使用delete删除数据以后,数据库的存储容量不会减少,而且使用delete删除某个表的数据以后,查询这张表的速度和删除之前一样,不会发生变化。
因为oralce有一个HWM高水位,它是oracle的一个表使用空间最高水位线。当插入了数据以后,高水位线就会上涨,但是如果你采用delete语句删除数据的话,数据虽然被删除了,但是高水位线却没有降低,还是你刚才删除数据以前那么高的水位。除非使用truncate删除数据。那么,这条高水位线在日常的增删操作中只会上涨,不会下跌,所以数据库容量也只会上升,不会下降。而使用select语句查询数据时,数据库会扫描高水位线以下的数据块,因为高水位线没有变化,所以扫描的时间不会减少,所以才会出现使用delete删除数据以后,查询的速度还是和delete以前一样。在网上查了下,决定用表分区来解决这个问题,方案就是每天定期新建表分区,同时删除旧的表分区。
首先,新建表和分区
[sql] view plain copy
CREATE TABLE “DATASERVER”.”SVRSENSORDATA”
( “ID” NUMBER(*,0) DEFAULT 0 NOT NULL ENABLE,
“SSID” NUMBER(*,0) DEFAULT 0 NOT NULL ENABLE,
“TYPE” NUMBER(*,0) DEFAULT 0 NOT NULL ENABLE,
“VALUE” BINARY_DOUBLE DEFAULT 0,
“TIME” TIMESTAMP (3) NOT NULL ENABLE,
)PARTITION BY RANGE (TIME) --以TIME字段做分区条件
(
partition SDP_20140302 values less than (to_date(‘2014/03/02’,’YYYY/MM/DD’)),
partition SDP_20140303 values less than (to_date(‘2014/03/03’,’YYYY/MM/DD’)),
partition SDP_20500101 values less than (maxvalue)
);
这里新建了表和表分区,然后要做的就是每天都新建一个新的表分区。
建立添加新表分区的存储过程
[sql] view plain copy
create or replace
PROCEDURE SVRSENSORDATA_ADDPART(
DaysAmount NUMBER --要添加多少天之后的分区
)
AS
v_SqlExec VARCHAR2(2000); --DDL语句变量
v_PartName VARCHAR2(20);--创建分区的日期(YYYYMMDD)
v_PartDateStr VARCHAR2(20);--分区时间的字符串形式
begin
v_PartName:= ‘SDP_‘ +to_char(sysdate + DaysAmount,’YYYYMMDD’);
v_partdatestr:= to_char(sysdate + DaysAmount, ‘YYYY-MM-DD’);
v_SqlExec:=’alter table SVRSENSORDATA SPLIT partition SDP_20500101 at (to_date(‘||v_PartDateStr||’,’’YYYY-MM-DD’’)) INTO (PARTITION ‘||v_PartName||’, PARTITION SDP_20500101)’;
DBMS_Utility.Exec_DDL_Statement(v_SqlExec);
END SVRSENSORDATA_ADDPART;
建立删除分区的存储过程
[sql] view plain copy
create or replace
PROCEDURE SVRSENSORDATA_DROPPART(
DaysAmount NUMBER --删除间隔日期
)
AS
v_SqlExec VARCHAR2(2000); --DDL语句变量
--先查找DaysAmount之前的表分区
cursor cursor_part is
select partition_name from user_tab_partitions
WHERE table_name= ‘SVRSENSORDATA’ AND to_date(SUBSTR(partition_name,5,8),’YYYYMMDD’)< sysdate- daysamount order by partition_name;
cursor_oldpart cursor_part%rowType;
begin
open cursor_part;
loop
fetch cursor_part into cursor_oldpart;
exit when cursor_part%notfound;
v_sqlexec:=’ALTER TABLE SVRSENSORDATA DROP PARTITION ‘||cursor_oldpart.partition_name;
DBMS_Utility.Exec_DDL_Statement(v_SqlExec);
end loop;
close cursor_part;
END SVRSENSORDATA_DROPPART;
然后使用Oracle job 每天定期执行一次这两个过程。
数据库表的垂直拆分和水平拆分
垂直拆分
垂直拆分是指数据表列的拆分,把一张列比较多的表拆分为多张表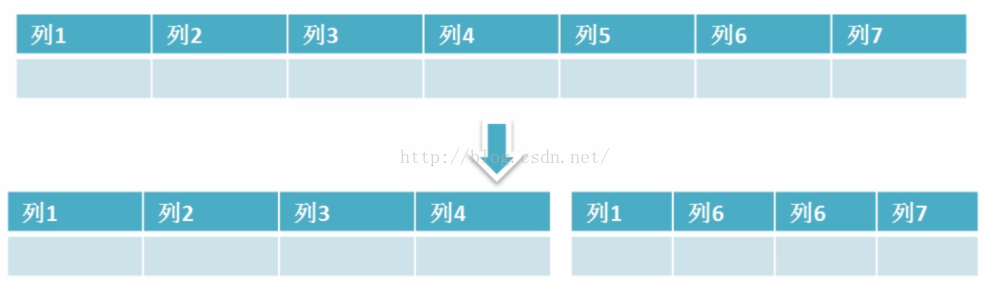
通常我们按以下原则进行垂直拆分:
把不常用的字段单独放在一张表;
把text,blob等大字段拆分出来放在附表中;
经常组合查询的列放在一张表中;垂直拆分更多时候就应该在数据表设计之初就执行的步骤,然后查询的时候用join关键起来即可;
水平拆分
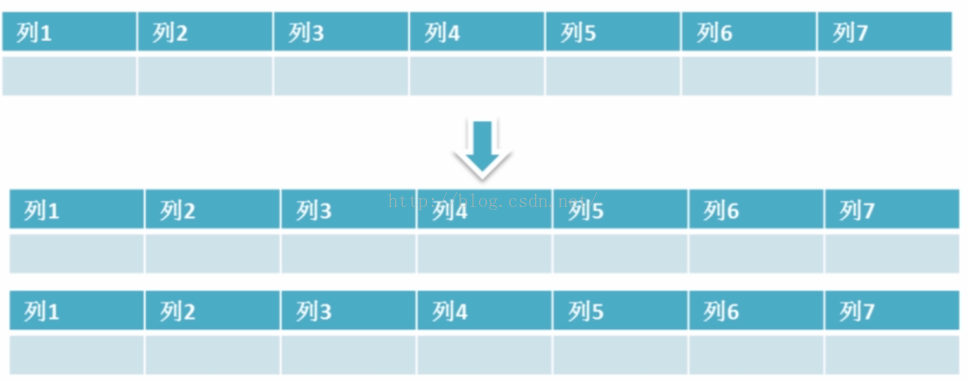
水平拆分是指数据表行的拆分,表的行数超过200万行时,就会变慢,这时可以把一张的表的数据拆成多张表来存放。
水平拆分的一些技巧
1. 拆分原则
通常情况下,我们使用取模的方式来进行表的拆分;比如一张有400W的用户表users,为提高其查询效率我们把其分成4张表
users1,users2,users3,users4
通过用ID取模的方法把数据分散到四张表内Id%4+1 = [1,2,3,4]
这里是个小哈希,然后查询,更新,删除也是通过取模的方法来查询
$_GET[‘id’] = 17,17%4 + 1 = 2, $tableName = ‘users’.’2’
Select * from users2 where id = 17;
在insert时还需要一张临时表uid_temp来提供自增的ID,该表的唯一用处就是提供自增的ID;
insert into uid_temp values(null);
得到自增的ID后,又通过取模法进行分表插入;
注意,进行水平拆分后的表,字段的列和类型和原表应该是相同的,但是要记得去掉auto_increment自增长
另外
部分业务逻辑也可以通过地区,年份等字段来进行归档拆分;
进行拆分后的表,只能满足部分查询的高效查询需求,这时我们就要在产品策划上,从界面上约束用户查询行为。比如我们是按年来进行归档拆分的,这个时候在页面设计上就约束用户必须要先选择年,然后才能进行查询;
在做分析或者统计时,由于是自己人的需求,多点等待其实是没关系的,并且并发很低,这个时候可以用union把所有表都组合成一张视图来进行查询,然后再进行查询;
Create view users as select from users1 union select from users2 union………

























——索引与优化相关")


还没有评论,来说两句吧...