机器学习之降低损失(Reducing Loss)
为了训练模型,我们需要一种可降低模型损失的好方法。迭代方法是一种广泛用于降低损失的方法。
一、迭代方法: 一种迭代试错,优化模型的方法
机器学习算法用于训练模型的迭代试错(迭代方法)过程:
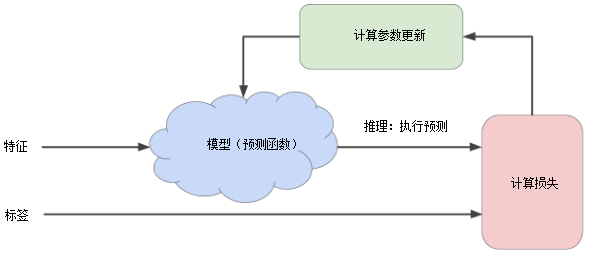
简单来说,迭代方法就是将模型预测值与实际值之间的误差值反馈给模型,让模型不断改进,误差值会越来越小,即模型预测的会越来越精确。
在训练机器学习模型时,首先对权重和偏差进行初始猜测,然后反复调整这些猜测,直到获得损失可能最低的权重和偏差为止。
学习链接: https://developers.google.cn/machine-learning/crash-course/reducing-loss/an-iterative-approach
二、梯度下降法: 一种快速找到损失函数收敛点的方法
回归问题所产生的 损失与权重值的图形 (损失曲线)始终是 凸形 。
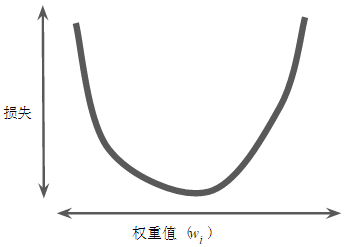
凸形问题只有一个最低点;即只存在一个斜率正好为 0 的位置。 这个最小值就是损失函数收敛之处。
梯度下降法:
- 首先为权重值(w1)选择一个起始值(起点)。
起点并不重要;因此很多算法就直接将 w1设为 0 或随机选择一个值。
- 然后,梯度下降法算法会计算损失曲线在起点处的梯度。
梯度 是偏导数相对于所有自变量的 矢量 ;它可以让你了解哪个方向距离目标“更近”或“更远”。损失相对于单个权重的梯度就等于导数。
- 梯度始终指向损失函数中增长最为迅猛的方向。梯度下降法算法会沿着负梯度的方向走一步,以便尽快降低损失。(梯度下降法依赖于负梯度)
- 为了确定损失函数曲线上的下一个点,梯度下降法算法会将梯度大小的一部分与起点相加,如下图所示:
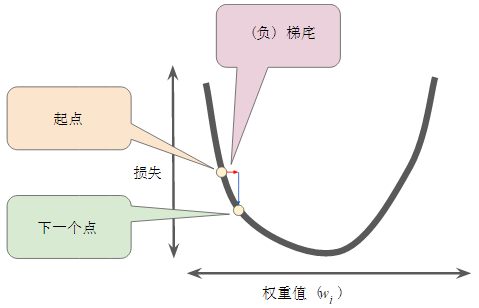
一个梯度步长将我们移动到损失曲线上的下一个点。
- 重复此过程,逐渐接近最低点。
三、学习速率: 用来确定每一步的“步幅”
梯度下降法算法用梯度乘以一个称为 学习速率 (有时也称为 步长 )的标量,以确定下一个点的位置。 例如,如果梯度大小为 2.5,学习速率为 0.01,则梯度下降法算法会选择距离前一个点 0.025 的位置作为下一个点。
超参数 是机器学习算法中用于调整的旋钮。大多数机器学习编程人员会花费相当多的时间来调整学习速率。
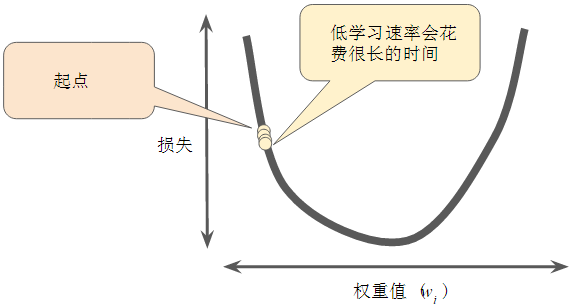
- 如果选择的学习速率过小,就会花费太长的学习时间,如下图所示:
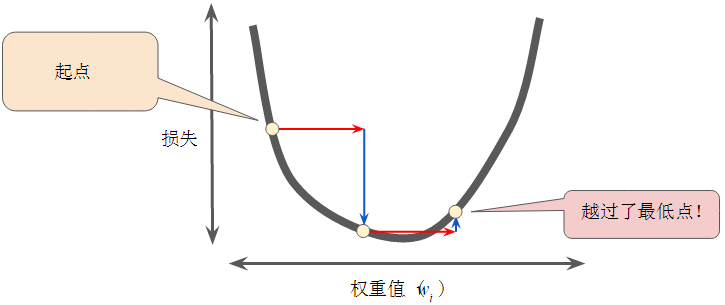
- 相反,如果指定的学习速率过大,下一个点将永远在 U 形曲线的底部随意弹跳,很可能会越过最低点。如下图所示:
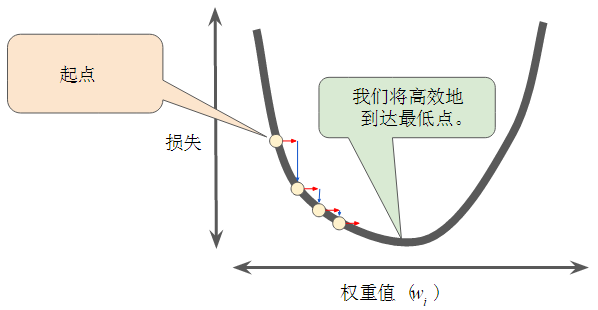
- 学习速率刚刚好。每个回归问题都存在一个金发姑娘学习速率。“金发姑娘”值与损失函数的平坦程度相关。如果知道损失函数的梯度较小,则可以放心地试着采用更大的学习速率,以补偿较小的梯度并获得更大的步长。
优化学习速率练习: https://developers.google.cn/machine-learning/crash-course/fitter/graph
四、随机梯度下降法(SGD)
三个概念:全批量梯度下降法、小批量随机梯度下降法、随机梯度下降法
在梯度下降法中, 批量 指的是 用于在单次迭代中计算梯度的样本总数 。到目前为止,我们一直假定批量是指整个数据集。如果数据集太大(即批量过于巨大),则单次迭代就可能要花费很长时间进行计算。SGD就是用来解决此问题的。
如果我们可以通过更少的计算量得出正确的平均梯度,会怎么样?通过从我们的数据集中随机选择样本,我们可以通过小得多的数据集估算(尽管过程非常杂乱)出较大的平均值。 随机梯度下降法 (SGD) 将这种想法运用到极致,它每次迭代只使用一个样本(批量大小为 1)。“随机”表示构成各个批量的一个样本都是随机选择的。
简单来说,SGD就是从大的数据集中随机选择样本来得到一个小得多的数据集,用它来估算出正确的平均梯度值。
小批量随机梯度下降法(小批量 SGD) 是介于全批量迭代与 SGD 之间的折衷方案。小批量通常包含 10-1000 个随机选择的样本。小批量 SGD 可以减少 SGD 中的杂乱样本数量,但仍然比全批量更高效。
Playground 练习 : https://developers.google.cn/machine-learning/crash-course/reducing-loss/playground-exercise
神经网络练习网站:
http://playground.tensorflow.org/#activation=tanh&batchSize=10&dataset=circle®Dataset=reg-plane&learningRate=0.03®ularizationRate=0&noise=0&networkShape=4,2&seed=0.24585&showTestData=false&discretize=false&percTrainData=50&x=true&y=true&xTimesY=false&xSquared=false&ySquared=false&cosX=false&sinX=false&cosY=false&sinY=false&collectStats=false&problem=classification&initZero=false&hideText=false



























")


")



还没有评论,来说两句吧...