java网络爬虫模拟登录案例教学2
本文为原创博客,仅供技术学习使用。未经允许,禁止将其复制下来上传到百度文库等平台。
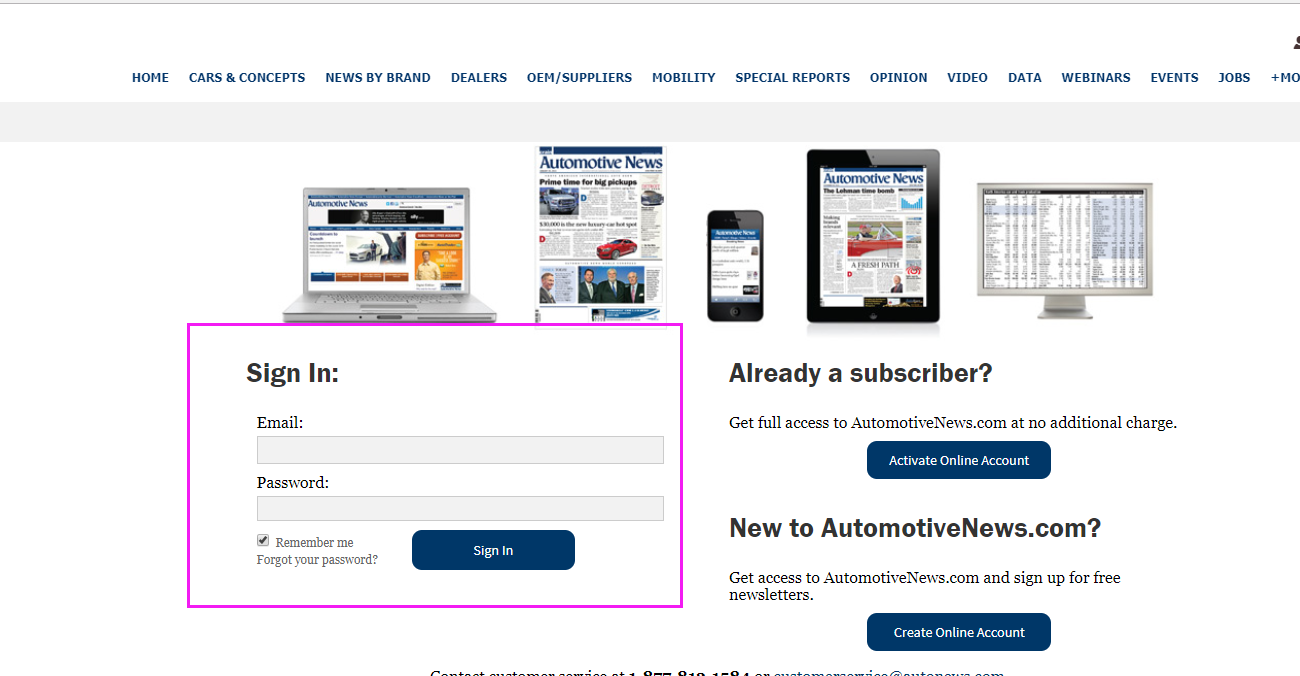
模拟登录的网站
我们需要登录的网站为:autonews,模拟登陆的地址为:
https://home.autonews.com/clickshare/cspLogin.do
网络抓包分析
在请求表单中,输入用户名及密码。
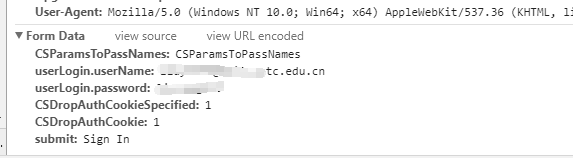
可以看到,我们要向后台提交的数据有哪些。
CSParamsToPassNames:CSParamsToPassNames
userLogin.userName:你的用户名
userLogin.password:你的密码
CSDropAuthCookieSpecified:1
CSDropAuthCookie:1
submit:Sign In
实战代码
package crawlerTest;/* * 合肥工业大学 管理学院 qianyang 1563178220@qq.com */import java.io.BufferedOutputStream;import java.io.BufferedWriter;import java.io.File;import java.io.FileOutputStream;import java.io.IOException;import java.io.InputStream;import java.io.OutputStreamWriter;import java.util.ArrayList;import java.util.List;import org.apache.http.Header;import org.apache.http.HttpEntity;import org.apache.http.HttpResponse;import org.apache.http.NameValuePair;import org.apache.http.client.ClientProtocolException;import org.apache.http.client.ResponseHandler;import org.apache.http.client.entity.UrlEncodedFormEntity;import org.apache.http.client.methods.HttpGet;import org.apache.http.client.methods.HttpPost;import org.apache.http.impl.client.BasicResponseHandler;import org.apache.http.impl.client.DefaultHttpClient;import org.apache.http.message.BasicNameValuePair;import org.apache.http.protocol.HTTP;import org.apache.http.util.EntityUtils;@SuppressWarnings("deprecation")public class AutonewsLogin {// The configuration items//输入用户名及密码private static String userName = "";private static String password = "";private static String redirectURL = "https://home.autonews.com/clickshare/myhome.do";// Don't change the following URLprivate static String renRenLoginURL = "https://home.autonews.com/clickshare/cspLogin.do";// The HttpClient is used in one sessionprivate HttpResponse response;private DefaultHttpClient httpclient = new DefaultHttpClient();private boolean login() {//open the LoginURLHttpPost httpost = new HttpPost(renRenLoginURL);// All the parameters post to the web site//建立一个NameValuePair数组,用于存储欲传送的参数List<NameValuePair> nvps = new ArrayList<NameValuePair>();// nvps.add(new BasicNameValuePair("CSAuthReq", "1"));// nvps.add(new BasicNameValuePair("CSTargetURL", "http%3A%2F%2Fwww.autonews.com%2F"));// nvps.add(new BasicNameValuePair("CSResumeURL", "/clickshare/forceLogin.do"));// nvps.add(new BasicNameValuePair("CSParamsToPassNames", "CSAuthReq|CSTargetURL|CSResumeURL|CSParamsToPassNames"));nvps.add(new BasicNameValuePair("userLogin.userName", userName));nvps.add(new BasicNameValuePair("userLogin.password", password));// nvps.add(new BasicNameValuePair("CSDropAuthCookieSpecified", "1"));// nvps.add(new BasicNameValuePair("CSDropAuthCookie", "1"));nvps.add(new BasicNameValuePair("submit", "Sign In"));try {httpost.setEntity(new UrlEncodedFormEntity(nvps, HTTP.UTF_8));response = httpclient.execute(httpost);int StatusCode = response.getStatusLine().getStatusCode();System.out.println(StatusCode);} catch (Exception e) {e.printStackTrace();return false;} finally {httpost.abort();}return true;}private String getRedirectLocation() {Header locationHeader = response.getFirstHeader("Location");if (locationHeader == null) {return null;}return locationHeader.getValue();}private String getText(String redirectLocation) {HttpGet httpget = new HttpGet(redirectLocation);// Create a response handlerResponseHandler<String> responseHandler = new BasicResponseHandler();String responseBody = "";try {responseBody = httpclient.execute(httpget, responseHandler);} catch (Exception e) {e.printStackTrace();responseBody = null;} finally {httpget.abort();httpclient.getConnectionManager().shutdown();}return responseBody;}public String printText() {String html="";if (login()) {String redirectLocation = getRedirectLocation();if (redirectLocation != null) {html=getText(redirectURL);}}return html;}public static void main(String[] args) throws IOException {AutonewsLogin AutonewsLogin = new AutonewsLogin();BufferedWriter writer = new BufferedWriter( new OutputStreamWriter( new FileOutputStream( new File("D:\\d.txt")),"gbk"));String html=AutonewsLogin.printText();writer.write(html);writer.close();AutonewsLogin.downloadFile("http://www.autonews.com/assets/PDF/CA11537753.PDF","E:\\zipFile\\","1");}//下载该网页的pdf文件public void downloadFile(String fileURL, String saveDir,String fileName)throws IOException {File fileDir=new File(saveDir);if(!fileDir.exists()){fileDir.mkdirs();}//图片或zip下载保存地址String filename=saveDir+fileName+".pdf";File file=new File(filename);if(file.exists()){file.delete();}BufferedOutputStream bw = new BufferedOutputStream(new FileOutputStream(filename));HttpGet httpGet=new HttpGet(fileURL);HttpResponse httpResponse = httpclient.execute(httpGet);try {HttpEntity entity=httpResponse.getEntity();int i=-1;byte[] byt= EntityUtils.toByteArray(entity);bw.write(byt);System.out.println("文件下载成功!");} catch (ClientProtocolException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();}bw.close();}}
程序结果




























还没有评论,来说两句吧...