HBase集群安装
前言:阅读本文之前,可以去apache hbase官网阅读安装配置文档,看不懂可以借助翻译,计算机所有的各种新技术只有官网是唯一且准确的第一手资料。
http://hbase.apache.org/book.html#hbase_default_configurations
一、Hbase简介
Apache HBase 是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,是NoSQL数据库,基于Google Bigtable思想的开源实现,可在廉价的PC Server上搭建大规模结构化存储集群,利用Hadoop HDFS作为其文件存储系统,利用Hadoop MapReduce来处理HBase海量数据,使用Zookeeper协调服务器集群。
二、环境准备
笔者还是搭建hadoop、spark集群的那三个节点,要配置HBase Master、Master-backup、RegionServer各节点的进程规划如下:
centos 6.5
JDK-1.8.x
Zookeeper-3.4.6
Hadoop-2.7.3
以上这些都在笔者的其他博客里有详细介绍,不再赘述。
主机 IP 节点进程
master HMaster
worker1 Master-backup、RegionServer
worker2 RegionServer
三、安装Hbase-1.2.6
1.可从官网或者国内阿里云等镜像站下载Hbase
http://mirror.bit.edu.cn/apache/hbase/stable/hbase-1.2.6-bin.tar.gz
2.解压至/app/hbase/目录下
[hadoop@master app]$ lshadoop hbase hive java kafka scala spark tgz zookeeper
3.添加系统环境变量
# User specific environment and startup programsexport JAVA_HOME=/app/java/jdk1.8.0_141export HADOOP_HOME=/app/hadoop/hadoop-2.7.3export SCALA_HOME=/app/scala/scala-2.11.8export SPARK_HOME=/app/spark/spark-2.1.1export ZOOKEEPER_HOME=/app/zookeeper/zookeeper-3.4.6export KAFKA_HOME=/app/kafka/kafka_2.10-0.9.0.0export HIVE_HOME=/app/hive/apache-hive-2.1.1-binexport HBASE_HOME=/app/hbase/hbase-1.2.6PATH=$PATH:$HOME/bin:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SCALA_HOME/bin:$SPARK_HOME/bin:$SPARK_HOME/sbin:$ZOOKEEPER_HOME/bin:$KAFKA_HOME/bin:$HIVE_HOME/bin:$HBASE_HOME/binexport PATH
别忘了source一下使用环境变量生效
[hadoop@master app]$ source ~/.bash_profile
4.阅读apache hbase官方文档发现,有一项是要将hadoop的conf目录下的hdfs-site.xml复制到hbase的conf目录下,这样可以保证hdfs和hbase的配置一致,例如副本数hbase和hdfs要一致。
官网原文:
Procedure: HDFS Client Configuration
Of note, if you have made HDFS client configuration changes on your Hadoop cluster, such as configuration directives for HDFS clients, as opposed to server-side configurations, you must use one of the following methods to enable HBase to see and use these configuration changes:
Add a pointer to your HADOOP_CONF_DIR to the HBASE_CLASSPATH environment variable in hbase-env.sh.
Add a copy of hdfs-site.xml (or hadoop-site.xml) or, better, symlinks, under ${HBASE_HOME}/conf, or
if only a small set of HDFS client configurations, add them to hbase-site.xml.
[hadoop@master conf]$ cp /app/hadoop/hadoop-2.7.3/etc/hadoop/hdfs-site.xml /app/hbase/hbase-1.2.6/conf/
5.配置hbase-site.xml
参照官方文档http://hbase.apache.org/book.html#_configuration_files
编辑 $HBASE_HOME/conf/hbase-site.xml
<configuration><property><name>hbase.zookeeper.property.clientPort</name><value>2181</value></property><property><name>hbase.zookeeper.quorum</name><value>master,worker1,worker2</value><description>The directory shared by RegionServers.</description></property><property><name>hbase.zookeeper.property.dataDir</name><value>/app/zookeeper/zookeeper-3.4.6/data</value><description>注意这里的zookeeper数据目录与hadoop ha的共用,也即要与 zoo.cfg 中配置的一致Property from ZooKeeper config zoo.cfg.The directory where the snapshot is stored.</description></property><property><name>hbase.rootdir</name><value>hdfs://master:8020/hbase</value><description>The directory shared by RegionServers.官网多次强调这个目录不要预先创建,hbase会自行创建,否则会做迁移操作,引发错误至于端口,有些是8020,有些是9000,看 $HADOOP_HOME/etc/hadoop/hdfs-site.xml 里面的配置,本实验配置的是dfs.namenode.rpc-address.hdcluster.nn1 , dfs.namenode.rpc-address.hdcluster.nn2</description></property><property><name>hbase.cluster.distributed</name><value>true</value><description>分布式集群配置,这里要设置为true,如果是单节点的,则设置为falseThe mode the cluster will be in. Possible values arefalse: standalone and pseudo-distributed setups with managed ZooKeepertrue: fully-distributed with unmanaged ZooKeeper Quorum (see hbase-env.sh)</description></property></configuration>
6.配置regionserver文件
编辑 $HBASE_HOME/conf/regionservers 文件,输入要运行 regionserver 的主机名
worker1worker2
7.配置 backup-masters 文件(master备用节点)
HBase 支持运行多个 master 节点,因此不会出现单点故障的问题,但只能有一个活动的管理节点(active master),其余为备用节点(backup master),编辑 $HBASE_HOME/conf/backup-masters 文件进行配置备用管理节点的主机名
这一步也可不配置。
worker1
8.配置 hbase-env.sh 文件
编辑 HBASE_HOME/conf/hbase-env.sh 配置环境变量,为了实现统一管理,本文使用单独配置的zookeeper,即将其中的 HBASE_MANAGES_ZK 设置为 false
# Tell HBase whether it should manage it's own instance of Zookeeper or not.export HBASE_MANAGES_ZK=false#The default log rolling policy is RFA, where the log file is rolled as per the size defined for theexport JAVA_HOME=/app/java/jdk1.8.0_141export HBASE_CLASSPATH=/app/hbase/hbase-1.2.6/conf# 此配置信息,设置由hbase自己管理zookeeper,不需要单独的zookeeper。export HBASE_HOME=/app/hbase/hbase-1.2.6export HADOOP_HOME=/app/hadoop/hadoop-2.7.3#Hbase日志目录export HBASE_LOG_DIR=/app/hbase/hbase-1.2.6/logs
将master节点的hbase文件拷贝至worker1和worker2
[hadoop@master app]$ scp -r hbase/ hadoop@worker1:/app/[hadoop@master app]$ scp -r hbase/ hadoop@worker2:/app/
并将环境变量也拷贝过去
[hadoop@master app]$ scp ~/.bash_profile hadoop@worker1:~/[hadoop@master app]$ scp ~/.bash_profile hadoop@worker2:~/
ssh到各节点source使其生效。
至此,hbase配置全部完成
9.测试启动
使用 $HBASE_HOME/bin/start-hbase.sh 指令启动整个集群,查看其shell脚本,可见其启动顺序。
# HBASE-6504 - only take the first line of the output in case verbose gc is ondistMode=`$bin/hbase --config "$HBASE_CONF_DIR" org.apache.hadoop.hbase.util.HBaseConfTool hbase.cluster.distributed | head -n 1`if [ "$distMode" == 'false' ]then"$bin"/hbase-daemon.sh --config "${HBASE_CONF_DIR}" $commandToRun master $@else"$bin"/hbase-daemons.sh --config "${HBASE_CONF_DIR}" $commandToRun zookeeper"$bin"/hbase-daemon.sh --config "${HBASE_CONF_DIR}" $commandToRun master"$bin"/hbase-daemons.sh --config "${HBASE_CONF_DIR}" \--hosts "${HBASE_REGIONSERVERS}" $commandToRun regionserver"$bin"/hbase-daemons.sh --config "${HBASE_CONF_DIR}" \--hosts "${HBASE_BACKUP_MASTERS}" $commandToRun master-backupfi
hbase的启动依赖于hadoop和zookeeper,所以我们按照上述的启动顺序,一一启动。
也就是使用 hbase-daemon.sh 命令依次启动 zookeeper、master、regionserver、master-backup
因此,我们也按照这个顺序,在各个节点进行启动
在启动HBase之前,必须先启动Hadoop,以便于HBase初始化、读取存储在hdfs上的数据
(1)启动zookeeper(三个节点分别启动)
[hadoop@master bin]$ zkServer.sh status[hadoop@master bin]$ zkServer.sh statusJMX enabled by defaultUsing config: /app/zookeeper/zookeeper-3.4.6/bin/../conf/zoo.cfgMode: follower[hadoop@worker1 ~]$ zkServer.sh statusJMX enabled by defaultUsing config: /app/zookeeper/zookeeper-3.4.6/bin/../conf/zoo.cfgMode: leader[hadoop@worker2 ~]$ zkServer.sh statusJMX enabled by defaultUsing config: /app/zookeeper/zookeeper-3.4.6/bin/../conf/zoo.cfgMode: follower
(2)启动Hadoop分布式集群
这里使用start-all.sh启动
[hadoop@master bin]$ start-all.shThis script is Deprecated. Instead use start-dfs.sh and start-yarn.shStarting namenodes on [master]master: starting namenode, logging to /app/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-namenode-master.outworker2: starting datanode, logging to /app/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-datanode-worker2.outworker1: starting datanode, logging to /app/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-datanode-worker1.outmaster: starting datanode, logging to /app/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-datanode-master.outStarting secondary namenodes [0.0.0.0]0.0.0.0: starting secondarynamenode, logging to /app/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-secondarynamenode-master.outstarting yarn daemonsstarting resourcemanager, logging to /app/hadoop/hadoop-2.7.3/logs/yarn-hadoop-resourcemanager-master.outmaster: starting nodemanager, logging to /app/hadoop/hadoop-2.7.3/logs/yarn-hadoop-nodemanager-master.outworker1: starting nodemanager, logging to /app/hadoop/hadoop-2.7.3/logs/yarn-hadoop-nodemanager-worker1.outworker2: starting nodemanager, logging to /app/hadoop/hadoop-2.7.3/logs/yarn-hadoop-nodemanager-worker2.out[hadoop@master bin]$ jps3683 NodeManager3715 Jps3380 SecondaryNameNode3575 ResourceManager3223 DataNode2890 QuorumPeerMain3117 NameNode[hadoop@master bin]$
(3)启动hbase
[hadoop@master app]$ start-hbase.shstarting master, logging to /app/hbase/hbase-1.2.6/logs/hbase-hadoop-master-master.outJava HotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize=128m; support was removed in 8.0Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=128m; support was removed in 8.0worker2: starting regionserver, logging to /app/hbase/hbase-1.2.6/logs/hbase-hadoop-regionserver-worker2.outworker1: starting regionserver, logging to /app/hbase/hbase-1.2.6/logs/hbase-hadoop-regionserver-worker1.outworker2: Java HotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize=128m; support was removed in 8.0worker2: Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=128m; support was removed in 8.0worker1: Java HotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize=128m; support was removed in 8.0worker1: Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=128m; support was removed in 8.0worker1: starting master, logging to /app/hbase/hbase-1.2.6/logs/hbase-hadoop-master-worker1.out
查看各节点jps
master:
[hadoop@master app]$ jps5762 Jps3683 NodeManager3380 SecondaryNameNode5557 HMaster3575 ResourceManager3223 DataNode2890 QuorumPeerMain3117 NameNode
worker1:
这里start-hbase.sh脚本里启动了,Hmaster的备份进程
hbase-daemon.sh start master –backup &
[hadoop@worker1 app]$ jps3970 Jps2883 NodeManager2692 QuorumPeerMain3722 HMaster2798 DataNode3615 HRegionServer
worker2:
[hadoop@worker2 ~]$ jps3424 HRegionServer2730 QuorumPeerMain2826 DataNode2939 NodeManager3612 Jps
至此hbase配置启动完成。
四、Hbase测试并使用
1.使用hbase shell进入到 hbase 的交互命令行界面,这时可进行测试使用
[hadoop@master app]$ hbase shellSLF4J: Class path contains multiple SLF4J bindings.SLF4J: Found binding in [jar:file:/app/hbase/hbase-1.2.6/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]SLF4J: Found binding in [jar:file:/app/hadoop/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]HBase Shell; enter 'help<RETURN>' for list of supported commands.Type "exit<RETURN>" to leave the HBase ShellVersion 1.2.6, rUnknown, Mon May 29 02:25:32 CDT 2017hbase(main):001:0>
(1)查看集群状态和节点数量,很重要
hbase(main):001:0> status1 active master, 1 backup masters, 2 servers, 0 dead, 1.0000 average load
由此可知,一个活跃的master,一个备份masters,两个HRegionserver,零个死亡。
(2)创建表
hbase创建表create命令语法为:表名、列名1、列名2、列名3……
hbase(main):002:0> create 'employee' ,'name','age'0 row(s) in 6.4790 seconds => Hbase::Table - employee
(3)查看表
hbase(main):003:0> list 'employee'TABLEemployee1 row(s) in 0.2430 seconds=> ["employee"]
(4)导入数据
=> Hbase::Table - employeehbase(main):025:0> put 'employee','row1','name:firstname','james'0 row(s) in 0.0240 secondshbase(main):026:0> put 'employee','row1','name:lastname','lebron'0 row(s) in 0.0210 secondshbase(main):027:0> put 'employee','row2','age','33'0 row(s) in 0.0150 seconds
(5)全表扫描数据
hbase(main):028:0> scan 'employee'ROW COLUMN+CELLrow1 column=name:firstname, timestamp=1525800600153, value=jamesrow1 column=name:lastname, timestamp=1525800607228, value=lebronrow2 column=age:, timestamp=1525800622854, value=332 row(s) in 0.0690 seconds
(6)根据条件查询数据
hbase(main):029:0> get 'employee','row1'COLUMN CELLname:firstname timestamp=1525800600153, value=jamesname:lastname timestamp=1525800607228, value=lebron2 row(s) in 0.0220 secondshbase(main):003:0> get 'employee','row2'COLUMN CELLage: timestamp=1525800622854, value=331 row(s) in 0.1410 seconds
(7)表失效
hbase(main):004:0> disable 'employee'0 row(s) in 7.0270 seconds
(8)表重新生效
hbase(main):005:0> enable 'employee'0 row(s) in 5.1070 seconds
(9)删除数据表
使用drop命令对表进行删除,但只有表在失效的情况下,才能进行删除
hbase(main):004:0> disable 'employee'0 row(s) in 7.0270 secondshbase(main):006:0> drop 'employee'
(10)退出 hbase shell
quit
2.HBase 管理页面
HBase 还提供了管理页面,供用户查看,可更加方便地查看集群状态
在浏览器中输入 http://172.17.0.1:16010 地址(默认端口为 16010),即可进入到管理页面,如下图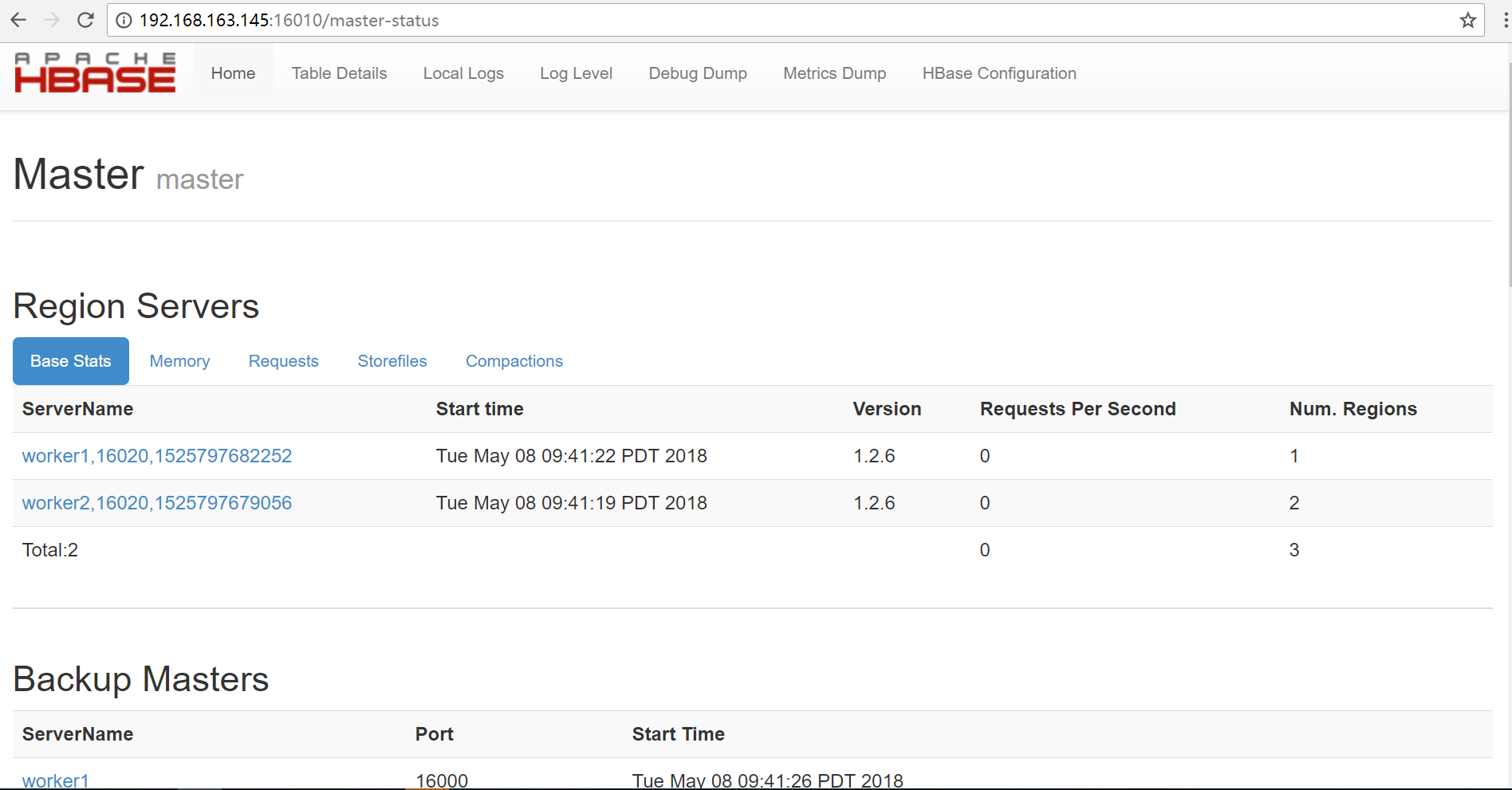
至此hbase配置全部完成。


























图的概述")

之图像描述-根据网络模型结构图训练网络")





还没有评论,来说两句吧...