Hystrix 熔断机制、服务降级、服务限流、解决服务雪崩效应
一、什么是服务的雪崩效应
所有的请求都在处理一个服务,造成其他服务不能访问。
1.使用超时机制、服务降级(服务调用接口,如果发生错误或者超时,不让调用接口,调用本地fallback)
2.熔断机制 类似保险丝 为了解决高并发请求,一旦达到规定请求,熔断,报错。——服务降级
3.隔离机制—各个服务接口隔离开
4.限流机制—nignx 使用网关
限流模式主要是提前对各个类型的请求设置最高的QPS阈值,若高于设置的阈值则对该请求直接返回,不再调用后续资源。这种模式不能解决服务依赖的问题,只能解决系统整体资源分配问题,因为没有被限流的请求依然有可能造成雪崩效应。
模拟雪崩效应可以使用Apache JMeter是Apache组织开发的基于Java的压力测试工具
#### tomcat最大接线程数server:port: 8765tomcat:max-threads: 50
在微服务架构中,我们将业务拆分成一个个的服务,服务与服务之间可以相互调用(RPC)。为了保证其高可用,单个服务又必须集群部署。由于网络原因或者自身的原因,服务并不能保证服务的100%可用,如果单个服务出现问题,调用这个服务就会出现网络延迟,此时若有大量的网络涌入,会形成任务累计,导致服务瘫痪,甚至导致服务“雪崩”。为了解决这个问题,就出现断路器模型。
Hystrix 断路器 rpc远程调用,解决服务雪崩效应,服务与服务之间的报错信息。
Hystrix 集成服务降级、熔断机制、隔离机制
Hystrix 是一个帮助解决分布式系统交互时超时处理和容错的类库, 它同样拥有保护系统的能力.什么是服务雪崩
分布式系统中经常会出现某个基础服务不可用造成整个系统不可用的情况, 这种现象被称为服务雪崩效应. 为了应对服务雪崩, 一种常见的做法是手动服务降级. 而Hystrix的出现,给我们提供了另一种选择。
1.引入依赖
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-hystrix</artifactId></dependency>
2.配置文件新增
feign:hystrix:enabled: true###超时时间hystrix:command:default:execution:isolation:thread:timeoutInMilliseconds: 5000
配置文件改为微服务无响应超过5秒钟
3.新建fallback类 默认:微服务无响应1秒内
Hy@Componentpublic class MemberFeignService implements MemberFeign {//服务的降级处理public List<String> getOrderByUserList() {List<String> listUser = new ArrayList<String>();listUser.add("not orderUser list");return listUser;}}
4.fegin调用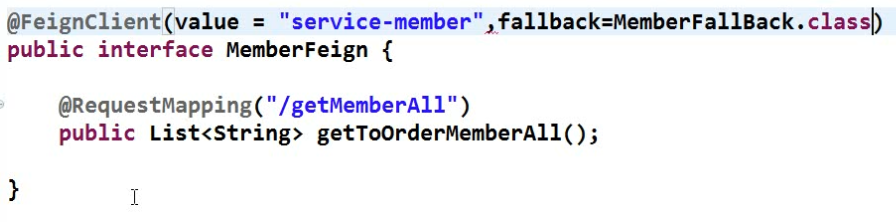





























-- volatile关键字解析")




还没有评论,来说两句吧...