python+shell 备份 CSDN 博客文章,CSDN博客备份工具
python+shell 备份 CSDN 博客文章,CSDN博客备份工具
在 csdn 写了几年的博客了。多少也积累了两三百篇博文,近日,想把自己的这些文章全部备份下来,于是开始寻找解决方案。
我找到了一个同为 CSDN 博主写的 python 脚本工具,尝试了一下,发现因为网站改版的原因,原先的脚本已经不能运行了。
其实,这是想要一揽子解决问题的脚本的通病,当一处变化,整个脚本就要作废。所以,我决定自己来解决这个问题,并且这个解决问题的方案,不会因为官方的改版就不能使用,只要稍微修改一下代码,即可。
分析备份文章的步骤
将一个大的问题,拆成若干个小的问题,即可轻松解决问题。
- csdn 的每篇博文都有独立的 ID
因此,我们需要把所有的 ID 都找出来。 - csdn 肯定有接口,展示我们的
markdown格式的文本
因为我们每次打开编辑器的时候,文本都会被渲染出来,所以肯定有接口。
就算没有接口,我们通过浏览器能访问到我们的文章,我们就一定有办法保存下来。
不过 csdn 有,所以没有尝试了。呵呵。 - 通过 ID 和接口,把文本全部读取出来,并保存到本地。
好,大概就是这个流程。
搞到所有文章的ID
这个会有很多种方法,我直接通过爬取我的博客首页,来拿到所有的文章 ID。分析一下我的博客的首页列表,我们可以看到这样的 url 格式 https://blog.csdn.net/fungleo/article/list/2。而我的博文有 14 页,所以,很容易猜测到我的博客问的所有列表。
循环一个 14 的数字即可。你有多少,就循环多少咯。然后我们分析一下源码:
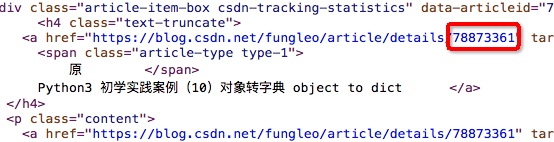
如上,我们的 ID 在一个名为 text-truncate 的 h4 标签中的 a 链接的结尾。通过 BeautifulSoup 这个 python 爬虫工具,我们可以非常轻松的拿到这个值。
于是,我写出了下面的脚本:
#!/usr/bin/env python3# -*- coding: UTF-8 -*-import urllib.requestfrom bs4 import BeautifulSoupimport osdef getid (x):url = r'https://blog.csdn.net/fungleo/article/list/' + str(x)res = urllib.request.urlopen(url)html = res.read().decode('utf-8')soup = BeautifulSoup(html,'html.parser')links = soup.find_all('h4', 'text-truncate')for i in links:os.system('echo ' + str(i.a['href']).replace('https://blog.csdn.net/fungleo/article/details/', '') + ' >> id.txt')for i in range(14):getid(i)
好,现在,我们所有的博客文章的 ID 都已经存在了 id.txt 这个文件夹下面了。
这里,我用了 python 执行 shell 脚本的方式写入文件。确实,shell 实在太方便了。
下载博客文章的所有的 json 数据
我通过分析博客的编辑器,顺利找到了一个接口,其结果如下:
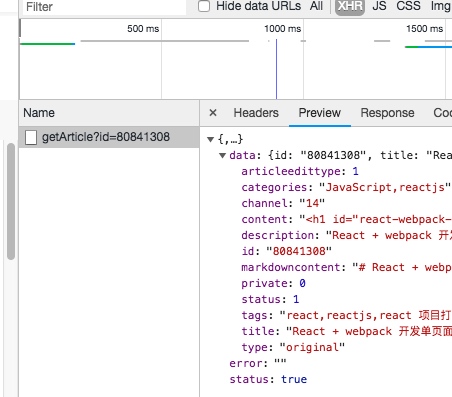
这个接口,实在是太完美了。下面,我就要把这些全部下载下来。
首先,我们先拿到 curl 的请求数据,在 chrome 浏览器中这样操作:

然后将复制到的内容,直接在终端内运行,果然能够拿到数据。这就好了,下面一个 shell 脚本循环,下载所有的 json 到本地。
首先,我们将浏览器用上面的操作复制出来的内容保存为一个 t.sh 的脚本文件,修改其中的 id 为 $1
curl 'https://mp.csdn.net/mdeditor/getArticle?id=$1' -H 'Cookie: __这里的代码我删除掉了。__' --compressed
然后,我们在命令行输入以下命令直接运行:
for i in $(cat id.txt); do sh t.sh $i > $i.json; sleep 1; done
好,经过数分钟的运行之后,我们的所有 JSON 数据就都已经保存到本地了。
至于这里为什么要用 shell 是因为它是在是太方便了。简单一句代码,就搞定所有问题。
将 json 数据读取,并保存成 markdown 格式的博文
通过两步,我们就已经拿到了数据了,下面要进行的就是数据的处理,这个 shell 就不方便了,我们继续用 python 脚本来解决问题。
我刚刚下载的时候,把 json 文件和我们的脚本放在一起了。我要规整一下,执行下面的几条命令:
mkdir json markdownmv *.json json
好,下面我们要把 json 文件夹中的所有数据读取,转换为 markdown 格式,并保存到 markdown 文件夹中。
脚本如下:
#!/usr/bin/env python3# -*- coding: UTF-8 -*-import osimport jsonsourceDir = './json'def readJson (filPath):f = open(filPath, encoding='utf-8')data = json.load(f)title = data['data']['title'].replace('/', ':')content = data['data']['markdowncontent']tags = data['data']['tags'].split(',')if content:mdFile = open('''./markdown/{title}.md'''.format(title=title), 'a+')mdFile.write('title: ' + title + '\n')mdFile.write('date: 2018-06-29 00:00:00 +0800\n')mdFile.write('update: 2018-06-29 00:00:00 +0800\n')mdFile.write('author: fungleo\n')mdFile.write('tags:\n')for tag in tags:mdFile.write(' -' + tag + '\n')mdFile.write('---\n\n')mdFile.write(content)def findJson ():for fil in os.listdir(sourceDir):filPath = os.path.join(sourceDir, fil)readJson(filPath)findJson()
嗯,我给每个博客都添加了一点元信息,不知道标准不标准,呵呵。
好,通过上面的几步,我就已经给所有的博客文章都备份到本地了。下面我想把所有的图片再全部备份出来,抽时间搞一下。
本文所有脚本均是在 mac 下运行的。linux 下可能略有差异,请注意。windows 下我不知道如何运行,不过可以搞一个云服务器或者虚拟机来跑,都是没有问题的。
本文由 FungLeo 原创,允许转载,但转载必须保留首发链接。

























Deep Multi-instance Networks with Sparse Label Assignment for Whole Mammogram Classific")




")



还没有评论,来说两句吧...