执行spark sql 遇到的问题
运行环境:
用图形更直观点。
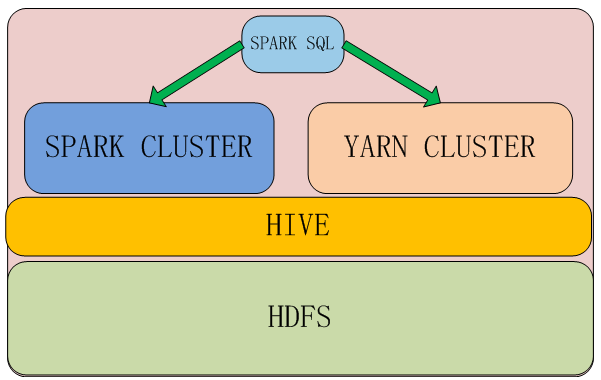
在 spark cluster 和 yarn cluster 两种方式运行spark sql, 操作hive中的数据,另外,hive 是独立的,可以直接运行hive处理数据。
spark sql的程序比较好写,直接看spark的example的例子HiveFromSpark ,很容易理解
首先,在spark cluster上运行:
将hive的 hive-site.xml 配置文件放到 ${SPARK_HOME}/conf 目录下
- #!/bin/bash
- cd $SPARK_HOME
- ./bin/spark-submit \
- -- class com.datateam.spark.sql.HotelHive \
- --master spark://192.168.44.80:8070 \
- --executor-memory 2G \
- --total-executor-cores 10 \
- /home/q/spark/spark-1.1.1-SNAPSHOT-bin-2.2.0/jobs/spark-jobs-20141023.jar \
执行脚本,遇到下面的错误:
- Exception in thread “main” org.apache.hadoop.hive.ql.metadata.HiveException: Unable to fetch table dw_hotel_price_log
- at org.apache.hadoop.hive.ql.metadata.Hive.getTable(Hive.java: 958)
- at org.apache.hadoop.hive.ql.metadata.Hive.getTable(Hive.java: 924)
- ……
- Caused by: org.datanucleus.exceptions.NucleusException: Attempt to invoke the “BONECP” plugin to create a ConnectionPool gave an error :
- The specified datastore driver (“com.mysql.jdbc.Driver”) was not found in the CLASSPATH.
- Please check your CLASSPATH specification, and the name of the driver.
- at org.datanucleus.store.rdbms.ConnectionFactoryImpl.generateDataSources(ConnectionFactoryImpl.java:237)
- at org.datanucleus.store.rdbms.ConnectionFactoryImpl.initialiseDataSources(ConnectionFactoryImpl.java:110)
- at org.datanucleus.store.rdbms.ConnectionFactoryImpl.
(ConnectionFactoryImpl.java:82) - … 127 more
- Caused by: org.datanucleus.store.rdbms.datasource.DatastoreDriverNotFoundException: The specified datastore driver (“com.mysql.jdbc.Driver”) was not
- found in the CLASSPATH. Please check your CLASSPATH specification, and the name of the driver.
- at org.datanucleus.store.rdbms.datasource.AbstractDataSourceFactory.loadDriver(AbstractDataSourceFactory.java:58)
- at org.datanucleus.store.rdbms.datasource.BoneCPDataSourceFactory.makePooledDataSource(BoneCPDataSourceFactory.java:61)
- at org.datanucleus.store.rdbms.ConnectionFactoryImpl.generateDataSources(ConnectionFactoryImpl.java:217)
意思是找不到 jdbc 的 connector,解决办法:
在提交任务的脚本里加入下面的配置语句即可:
--driver-class-path /home/q/spark/spark-1.1.1-SNAPSHOT-bin-2.2.0/lib/mysql-connector-java-5.1.22-bin.jar \
spark cluster 遇到的问题不多,主要在yarn cluster上遇到几个问题。
在spark cluster上调用hive的数据,需要将 hive-site.xml 文件放到spark的conf 目录下,那在yarn上运行该将hive的配置文件放到哪里才能被 spark sql 识别呢?
在提交任务的时候加上:
--files /home/q/spark/spark-1.1.1-SNAPSHOT-bin-2.2.0/conf/hive-site.xml \
这里用到的是 —files , 而不是 —conf
先看一下 提交任务的脚本:
- cd $SPARK_HOME
- ./bin/spark-submit — class com.qunar.datateam.spark.sql.HotelHive \
- --master yarn-cluster \
- --num-executors 10 \
- --driver-memory 4g \
- --executor-memory 2g \
- --executor-cores 2 \
- --files /home/q/spark/spark-1.1.1-SNAPSHOT-bin-2.2.0/conf/hive-site.xml \
- /home/q/spark/spark-1.1.1-SNAPSHOT-bin-2.2.0/jobs/spark-jobs-20141023.jar \
ok,我们这里同样需要将mysql connector的jar包添加进去,如何进行?
--jars mysql-connectorpath
但是会出现下面的问题:
- Exception in thread “Driver” java.lang.reflect.InvocationTargetException
- at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
- at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java: 57)
- at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java: 43)
- at java.lang.reflect.Method.invoke(Method.java: 606)
- at org.apache.spark.deploy.yarn.ApplicationMaster$$anon$ 2.run(ApplicationMaster.scala: 162)
- ……
- Caused by: org.apache.hadoop.hive.ql.metadata.HiveException: Unable to fetch table tablename
- at org.apache.hadoop.hive.ql.metadata.Hive.getTable(Hive.java: 958)
- at org.apache.hadoop.hive.ql.metadata.Hive.getTable(Hive.java: 924)
- Caused by: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.metastore.HiveMetaStoreClient
- at org.apache.hadoop.hive.metastore.MetaStoreUtils.newInstance(MetaStoreUtils.java: 1212)
- at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.
(RetryingMetaStoreClient.java: 62) - at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.getProxy(RetryingMetaStoreClient.java: 72)
- at org.apache.hadoop.hive.ql.metadata.Hive.createMetaStoreClient(Hive.java: 2372)
- at org.apache.hadoop.hive.ql.metadata.Hive.getMSC(Hive.java: 2383)
- at org.apache.hadoop.hive.ql.metadata.Hive.getTable(Hive.java: 950)
- … 68 more
- Caused by: java.lang.reflect.InvocationTargetException
- at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
- at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java: 57)
- at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java: 45)
- at java.lang.reflect.Constructor.newInstance(Constructor.java: 526)
- at org.apache.hadoop.hive.metastore.MetaStoreUtils.newInstance(MetaStoreUtils.java: 1210)
- … 73 more
- Caused by: javax.jdo.JDOFatalUserException: Class org.datanucleus.api.jdo.JDOPersistenceManagerFactory was not found.
- NestedThrowables:
- java.lang.ClassNotFoundException: org.datanucleus.api.jdo.JDOPersistenceManagerFactory
- ……
- Caused by: java.lang.ClassNotFoundException: org.datanucleus.api.jdo.JDOPersistenceManagerFactory
- at java.net.URLClassLoader$ 1.run(URLClassLoader.java: 366)
- at java.net.URLClassLoader$ 1.run(URLClassLoader.java: 355)
- at java.security.AccessController.doPrivileged(Native Method)
- at java.net.URLClassLoader.findClass(URLClassLoader.java: 354)
- at java.lang.ClassLoader.loadClass(ClassLoader.java: 425)
- at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java: 308)
- at java.lang.ClassLoader.loadClass(ClassLoader.java: 358)
- at java.lang.Class.forName0(Native Method)
- at java.lang.Class.forName(Class.java: 270)
- at javax.jdo.JDOHelper$ 18.run(JDOHelper.java: 2018)
- at javax.jdo.JDOHelper$ 18.run(JDOHelper.java: 2016)
- at java.security.AccessController.doPrivileged(Native Method)
- at javax.jdo.JDOHelper.forName(JDOHelper.java: 2015)
- at javax.jdo.JDOHelper.invokeGetPersistenceManagerFactoryOnImplementation(JDOHelper.java: 1162)
- … 97 more
查找资料,发现别人的讨论:http://apache-spark-user-list.1001560.n3.nabble.com/Spark-SQL-JDBC-td11369.html
于是将
datanucleus-api-jdo-3.2.1.jar, datanucleus-core-3.2.2.jar, datanucleus-rdbms-3.2.1.jar
都加到 —jars 里,但是还是出问题:
- Exception in thread “Driver” java.lang.reflect.InvocationTargetException
- at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
- at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java: 57)
- at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java: 43)
- at java.lang.reflect.Method.invoke(Method.java: 606)
- at org.apache.spark.deploy.yarn.ApplicationMaster$$anon$ 2.run(ApplicationMaster.scala: 162)
- Caused by: org.apache.spark.SparkException: Job aborted due to stage failure: Task 6 in stage 2.0 failed 4 times, most recent failure:
- Lost task 6.3 in stage 2.0 (TID 34, l-hbase72.data.cn8
- ): java.io.FileNotFoundException: ./datanucleus-core- 3.2.2.jar (Permission denied)
- java.io.FileOutputStream.open(Native Method)
- java.io.FileOutputStream.
(FileOutputStream.java: 221) - com.google.common.io.Files$FileByteSink.openStream(Files.java: 223)
- com.google.common.io.Files$FileByteSink.openStream(Files.java: 211)
- com.google.common.io.ByteSource.copyTo(ByteSource.java: 203)
- com.google.common.io.Files.copy(Files.java: 436)
经过不断尝试,将 —jars 后面的配置的jar包都用 —archives 的方式打到运行jar中:
--archives mysql-connector.jar,datanucleus-api-jdo-3.2.1.jar, datanucleus-core-3.2.2.jar, datanucleus-rdbms-3.2.1.jar
ok
另外还要注意一点:
spark sql 中不认“;”,所以只能在sql中指明database,不能用 use database ; 这样的hive sql 语句指定database






























、methods、watch的区别")



还没有评论,来说两句吧...