hadoop完全分布式环境搭建
1,设置Java环境

rpm -ivh jdk-8u73-linux-x64.rpm添加环境变量到启动文件vi /etc/profileexport JAVA_HOME=/usr/java/jdk1.8.0_73export PATH=$JAVA_HOME/bin:$PATHexport CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tool.jar
测试java环境
[root@DEV ~]# more test.javapublic class test{public static void main(String args[]){System.out.println("A new jdk test...sqing!");}}
javac test.java
[root@hadoop1 ~]# java test
A new jdk test…sqing!
看到这,表明java环境设置成功!
2,配置hosts
192.168.1.208 hadoop1
192.168.1.210 hadoop2
3,配置ssh无密登录
[root@hadoop1 ~]# ssh-keygen -t rsa -P ""Generating public/private rsa key pair.Enter file in which to save the key (/root/.ssh/id_rsa):Created directory '/root/.ssh'.Your identification has been saved in /root/.ssh/id_rsa.Your public key has been saved in /root/.ssh/id_rsa.pub.The key fingerprint is:0d:23:95:a0:7a:ce:78:ef:5b:a8:ab:35:53:01:91:85 root@hadoop1The key's randomart image is:+--[ RSA 2048]----+| o=o... || Eo .. || . o o || . o + || . . . S . || = . . || . B . . || o = . || ..oo+. |+-----------------+[root@hadoop1 ~]# cat .ssh/id_rsa.pub >>.ssh/authorized_keys[root@hadoop1 ~]# ssh localhostThe authenticity of host 'localhost (::1)' can't be established.RSA key fingerprint is 19:09:80:d2:03:1a:d0:1d:00:79:33:ea:4e:71:e0:eb.Are you sure you want to continue connecting (yes/no)? yesWarning: Permanently added 'localhost' (RSA) to the list of known hosts.Last login: Wed Mar 9 19:28:12 2016 from 192.168.1.3
copy authorized_keys到其它机器上,便可以实现无密登录其它机器
[root@hadoop1 ~]# ssh 192.168.1.210
Last login: Wed Mar 9 19:43:20 2016 from 192.168.1.3
[root@hadoop2 ~]#
下面便是解压,移动,hadoop
配置文件1:hadoop-env.sh
该文件是hadoop运行基本环境的配置,需要修改的为java虚拟机的位置。
/usr/local/hadoop/etc/hadoop

配置文件2:yarn-env.sh
该文件是yarn框架运行环境的配置,同样需要修改java虚拟机的位置。
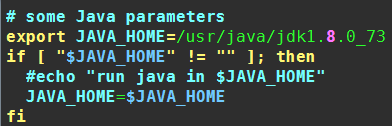
配置文件3:slaves
该文件里面保存所有slave节点的信息

配置文件4:core-site.xml
这个是hadoop的核心配置文件,这里需要配置的就这两个属性,fs.default.name配置了hadoop的HDFS系统的命名,位置为主机的 9000端口;hadoop.tmp.dir配置了hadoop的tmp目录的根位置。这里使用了一个文件系统中没有的位置,所以要先用mkdir命令新 建一下。
配置文件5:hdfs-site.xml
这个是hdfs的配置文件,dfs.http.address配置了hdfs的http的访问位置;dfs.replication配置了文件块的副本数,一般不大于从机的个数。
配置文件6:mapred-site.xml
配置文件7:yarn-site.xml
将配置好的hadoop复制到其他节点
scp -r hadoop/ root@hadoop2:~/
格式化namenode:
./bin/hdfs namenode -format
若出现如图所示提示,则格式化成功
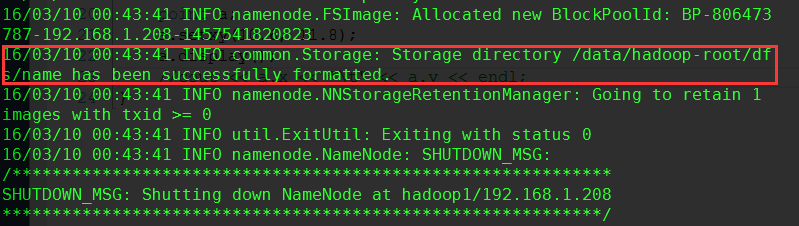
出现图示部分,则表示成功!
启动hdfs: ./sbin/start-dfs.sh
此时在Master上面运行的进程有:namenode secondarynamenode
Slave1和Slave2上面运行的进程有:datanode
启动yarn: ./sbin/start-yarn.sh
此时在Master上面运行的进程有:namenode secondarynamenode resourcemanager
Slave1和Slave2上面运行的进程有:datanode nodemanager
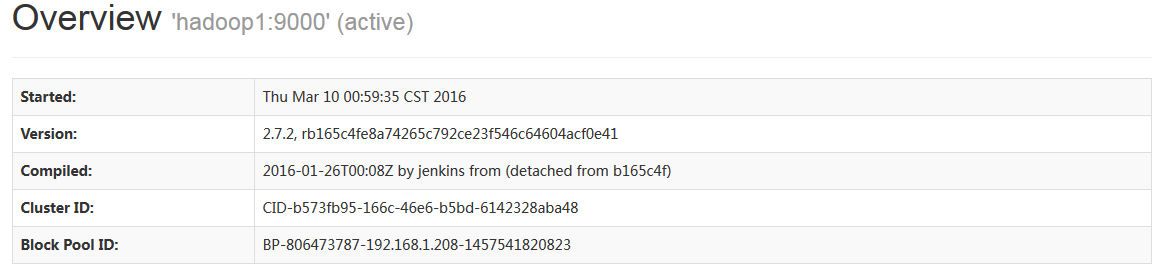
http://192.168.1.208:50070
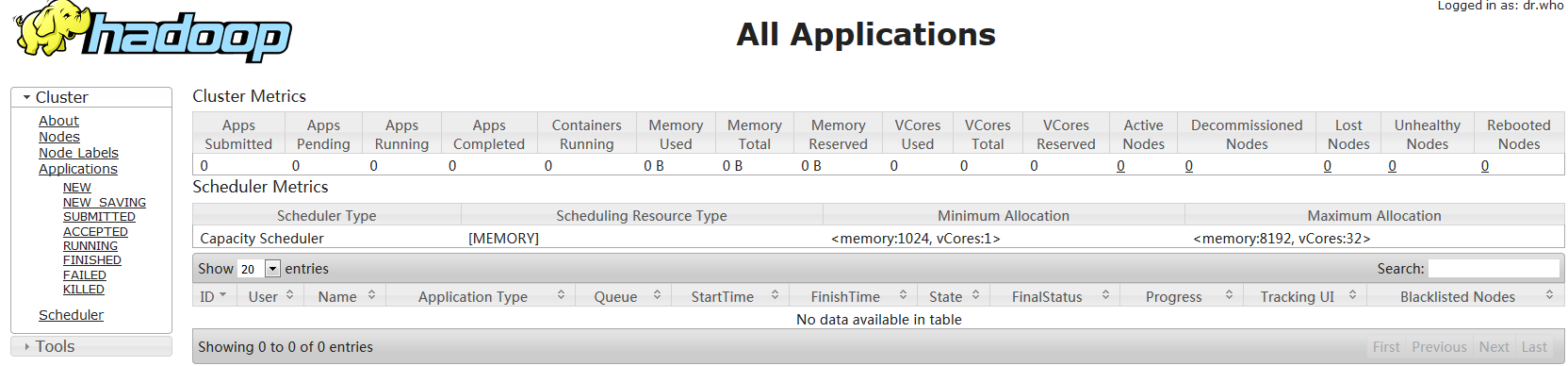
http://192.168.1.208:8088
end!


































还没有评论,来说两句吧...