【论文学习】Densely Connected Convolutional Networks 学习
【fishing-pan:https://blog.csdn.net/u013921430 转载请注明出处】
众所周知,自从ResNet 的网络结构被提出后,一直引领着深度学习的潮流,后来提出的一些网络结构都有这种short paths 的思想。而今天要提到的DenseNet 更是将这种思想发挥到了极致。DenseNet 凭借着优秀的表现当选 CVPR 2017 最佳论文,而他的网络结构并不复杂,思想也很简单,可以说是简单易学且高效的网络结构。
论文链接:https://arxiv.org/pdf/1608.06993.pdf
代码的github链接:https://github.com/liuzhuang13/DenseNet
(TensorFlow版本的代码推荐学习这个版本https://github.com/ikhlestov/vision\_networks)
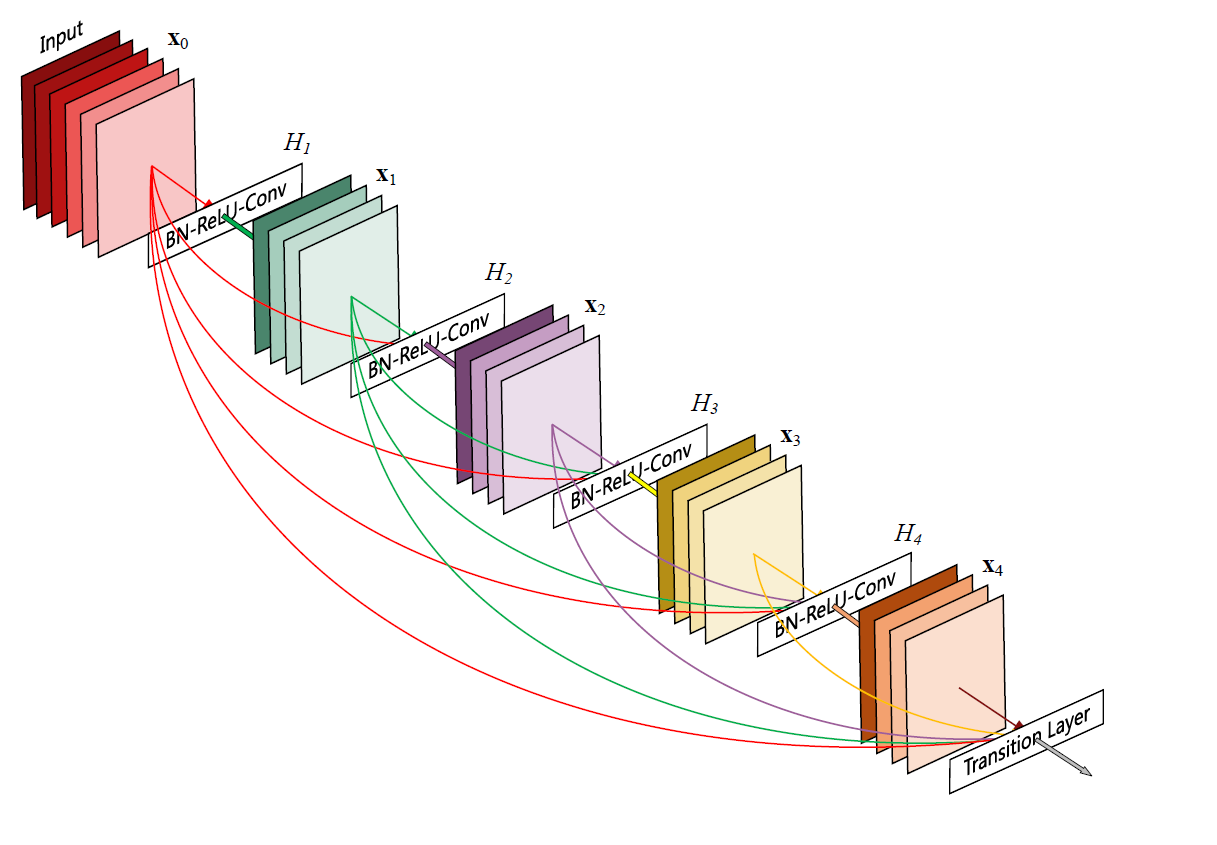
Figure 1 每一层将前面所有层的feature map都作为自身的输入
就像上面的图片中展示出的,Dense Block中每一层都输入是由前面所有层的feature map结合起来的,这种方式将特征重用发挥到了极致,这也正是DenseNet核心的优势所在,让网络中的每一层可以依赖于更前面层学习的特征。此外,在ResNet 中存在冗余的情况:将训练好的ResNet随机去掉网络中的几层,对于结果并不会产生明显的影响。因此作者将Dense Block设计的特别窄,每一层只学习得到比较少数量的feature,从而达到减轻冗余的情况。
但是,要知道一个网络结构想要达到高度的准确性,无外乎满足两点:网络结构深,或者宽(前者的代表就是ResNet,后者的代表就是GoogleNet了)。所以在设计了一个窄的网络结构后,一般人会想着加深网络层数以达到预期的准确性,但是作者并没有纠结于这两点。作者是从feature map着手,通过对feature map的极致的运用,使得即使没有很深的网络结构也不会出现准确性不足或者说欠拟合的现象,这是一个非常大的优势。(你网络效果好,你怎么说都对,哈哈哈哈)
如同ResNet 一样,由于short paths 的存在使得DenseNet 在网络结构在很深的时候也不会出现过拟合和梯度消失的情况。而DenseNet 还具有抗过拟合的作用,网络每一层提取的特征都相当于对输入数据的一个非线性变换,而随着深度的增加,变换的复杂度也逐渐增加(更多非线性函数的复合)。相比于一般神经网络的分类器直接依赖于网络最后一层(复杂度最高)的特征,DenseNet 可以综合利用浅层复杂度低的特征,因而更容易得到一个光滑的具有更好泛化性能的决策函数。
所以总的来说DenseNet有以下几个优点:
- 减少了参数量,计算量
- 解决了深层网络梯度消失的问题
- 加强了特征的传播,更有效地利用特征。
- 减轻了过拟合
那么DenseNet 具体是怎样实现的呢?
首先是非线性变换方程,在ResNet中,非线性变换方程如下;
x l = H ( x l − 1 ) + x l − 1 x_{l}=H(x_{l-1})+x_{l-1} xl=H(xl−1)+xl−1
DenseNet中的非线性变换方程如下;
x l = H ( [ x 0 , x 1 , ⋯ , x l − 1 ] ) x_{l}=H([x_{0},x_{1},\cdots ,x_{l-1}]) xl=H([x0,x1,⋯,xl−1])
从上面可以看出,ResNet 是将经过非线性变换的feature map 与上一层的feature map 直接相加,在作者看来,这种方式有点“粗鲁”,会干扰网络信息的传递。所以在DenseNet 中,第 l l l 层将所有前面 x 0 x_{0} x0 到 x l − 1 x_{l-1} xl−1 层的feature map 连接起来作为输入。
在DenseNet 中 H ( ⋅ ) H(\cdot ) H(⋅) 包括BN,ReLU和3x3的conv 操作。为了能让各层的feature map 尺寸一致,所以不会在Dense Block 中设置池化层。而每一个Dense Block 之间有transition layers 相连,在transition layers 中带有平均池化的操作。
DenseNet-B:
在Dense Block 中,有一个很关键的参数增长率(Growth rate) k k k ,他表示的是在 H ( ⋅ ) H(\cdot ) H(⋅) 中,每一层会产生多少feature map ,作者的实验表明 k k k 取较小的值,可能会得到更好的结果。但是,由于Dense Block 每一层的输入中包含了前面所有层的feature map ,那么第 l l l 层就会有 k 0 + k ∗ ( l − 1 ) k_{0}+k*(l-1) k0+k∗(l−1) 层输入,当 l l l 很大时,这个数值很明显是不可接受的。所以作者提出了DenseNet-B结构,在DenseNet-B 中的每个 H ( ⋅ ) H(\cdot ) H(⋅) 前都有一个瓶颈层(Bottleneck layers),以减少输入的feature map 的数目。瓶颈层由多个1x1的卷积核构成,其输出feature map 的数目一般为4*Growth rate。
DenseNet-BC:
为了让模型更加紧凑,作者又在transition layers 添加了瓶颈层,如果一个Dense Block 的输出有 m m m 张 feature map,设置一个参数 θ \theta θ ,最终在过度层中产生 θ m \theta m θm 张feature map;这种模型就是DenseNet-BC。

Figure 2 一个有三个Dense Block的深度网络,每个Dense Block之间有过渡层相连,过渡层由卷积层和池化层组成。
网络结构
DenseNet:
Dense Block: BN+Relu+Conv(33)+dropout
transition layer: BN+Relu+Conv(11)(m)+dropout+Average Pooling(22)
DenseNet-B:
Dense Block: BN+Relu+Conv(11)(4K)+dropout+BN+Relu+Conv(33)+dropout
transition layer: BN+Relu+Conv(11)(m)+dropout+Average Pooling(22)
DenseNet-BC:
Dense Block: BN+Relu+Conv(11)(4K)+dropout+BN+Relu+Conv(33)+dropout
transition layer: BN+Relu+Conv(11)(θm,0<θ<1,文中θ=0.5)+dropout+Average Pooling(2*2)
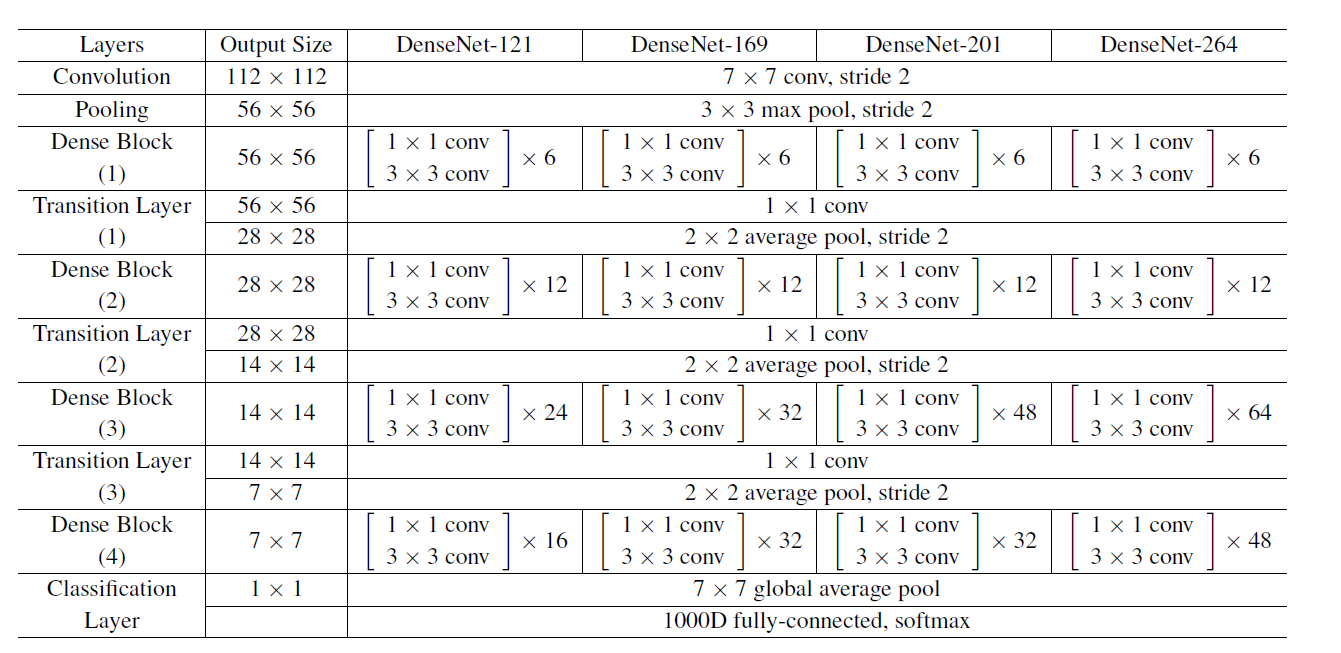
DenseNet-BC的网络结构参数如下,其中网络增长率K=32,conv 代表BN-ReLU-Conv
测试结果
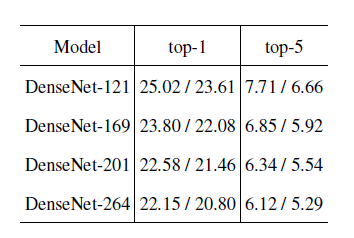
Table 1 不同的网络结构在ImageNet上1%和5%的错误率。
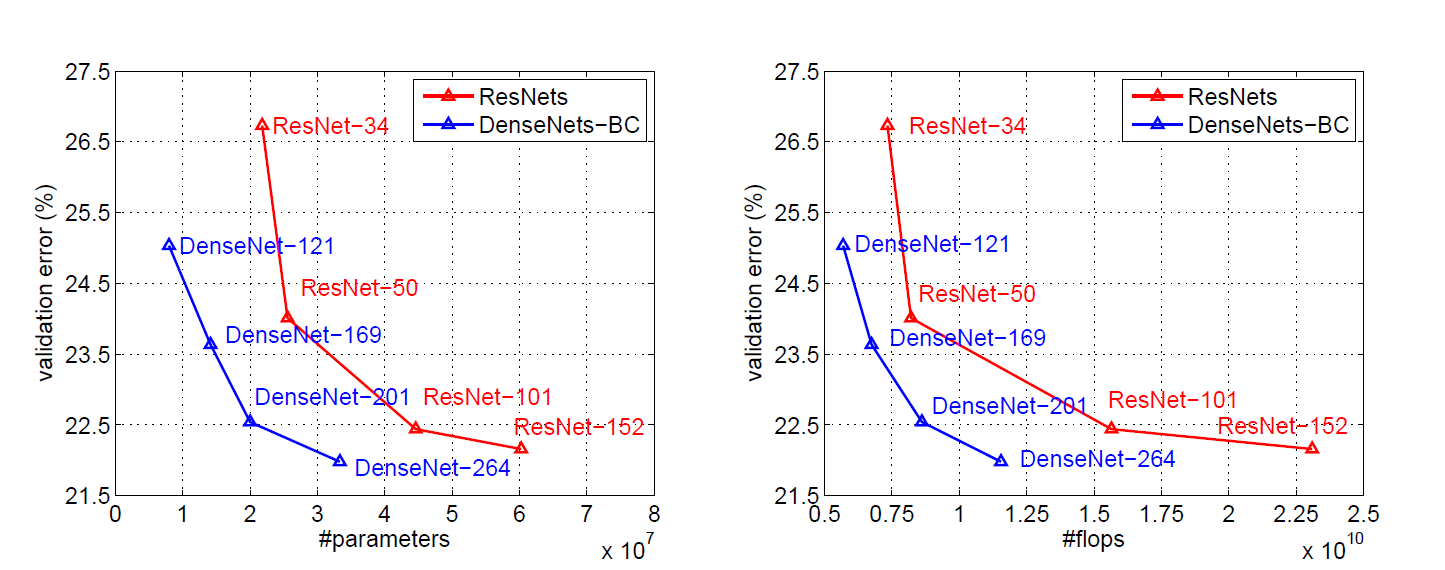
Figure 3 ImageNet上DenseNet-BC和ResNet对比
已完…


























truffle + web3 + webpack Metcoin 运行")







还没有评论,来说两句吧...