Map之LinkedHashMap源码实现
一、引言
1.回顾
1.1 HashMap的是怎么保证添加的元素的索引的(也就是说哈希桶是如何分布的)?
首先通过hash()方法:实现高位和低位进行充分位运算;然后通过 “table的长度” & “hash值”,计算得出其bucket值。
1.2 HashMap的扩容的流程是怎么样的?
把resize()的各种情况梳理一遍。值得注意的是:HashMap的的初始化操作也移到了resize方法中了。
1.3 1.8比1.7版本在HashMap的那些方面做了改动和优化?
最主要的是引入了红黑树对长链表进行了优化。其他的包括但不限于初始化的时机、扩容机制的微调等等。
2.要点
| 要点 | 说明 |
|---|---|
| 是否可以为空 | key和value都可以为空,但是key只能一个为空,value则不限 |
| 是否有序 | 有序。在继承HashMap的基础上,通过一个链表来维持顺序 |
| 是否可以重复 | key重复会覆盖,value则可以重复 |
| 是否线程安全 | 非线程安全 |
二、分析
1.继承关系结构图
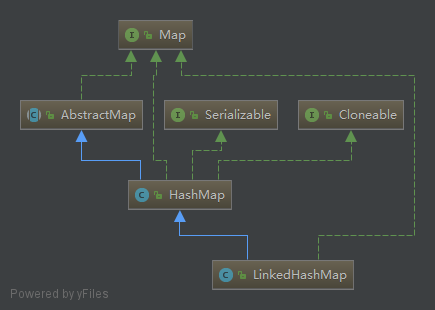
说明:LinkedHashMap是HashMap的子类。只是重写了其中维持顺序的列表的相关的操作。如下图所示: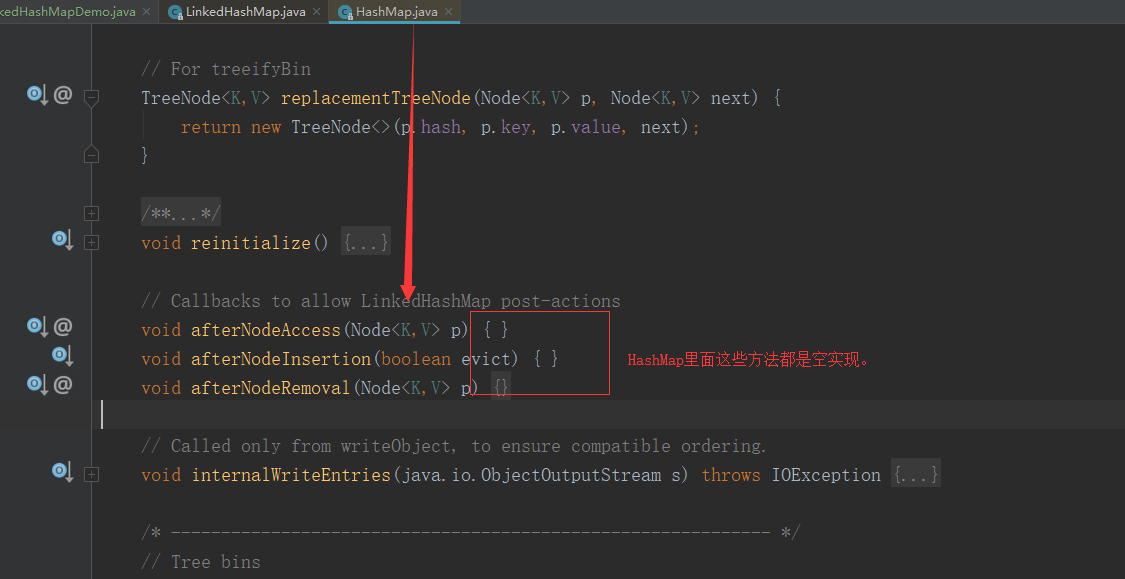
LinkedHashMap: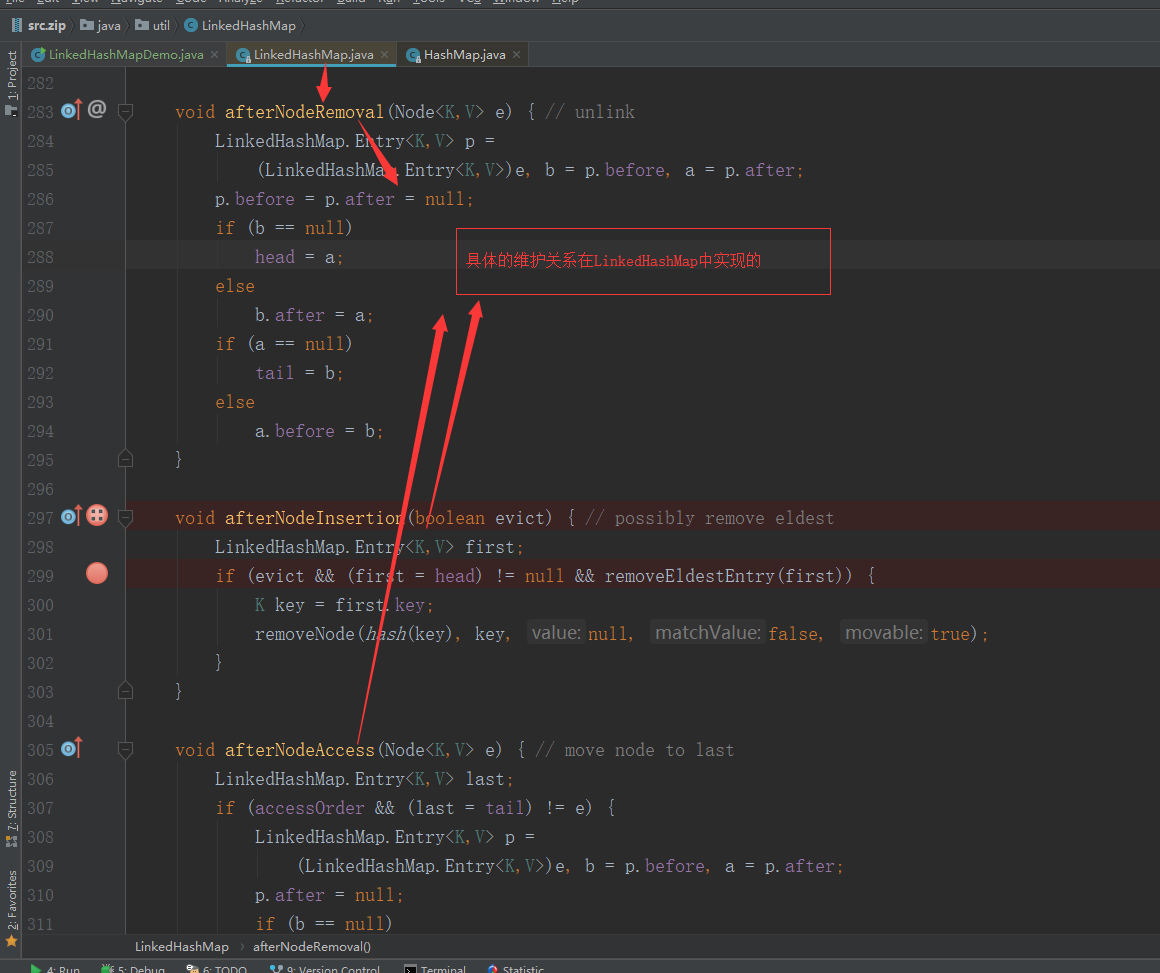
2.原理
2.1 图示
HashMap的存储方式: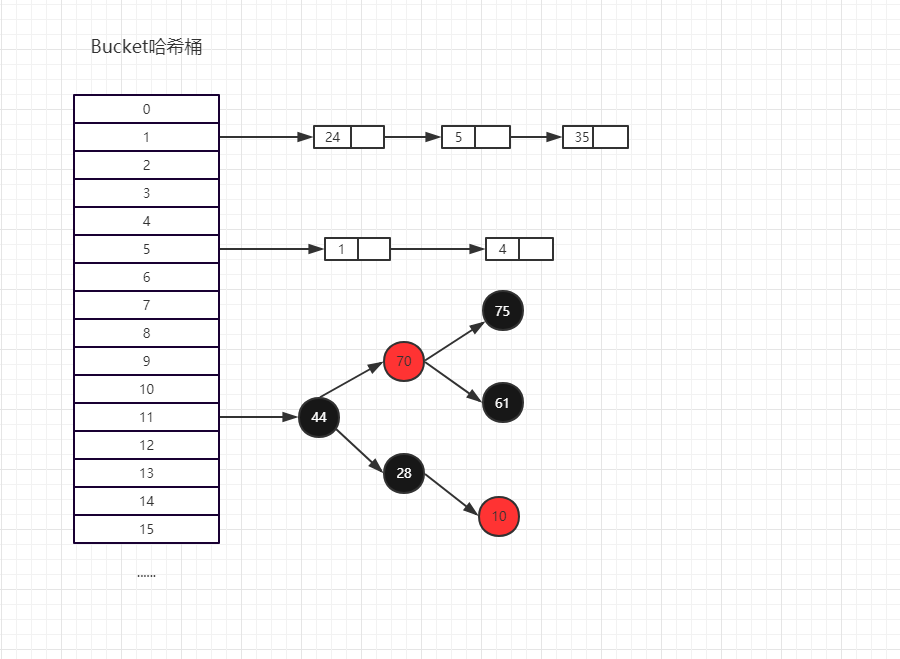
有顺序的HashMap的存储方式(即LinkedHashMap):多了一个双向列表来维护顺序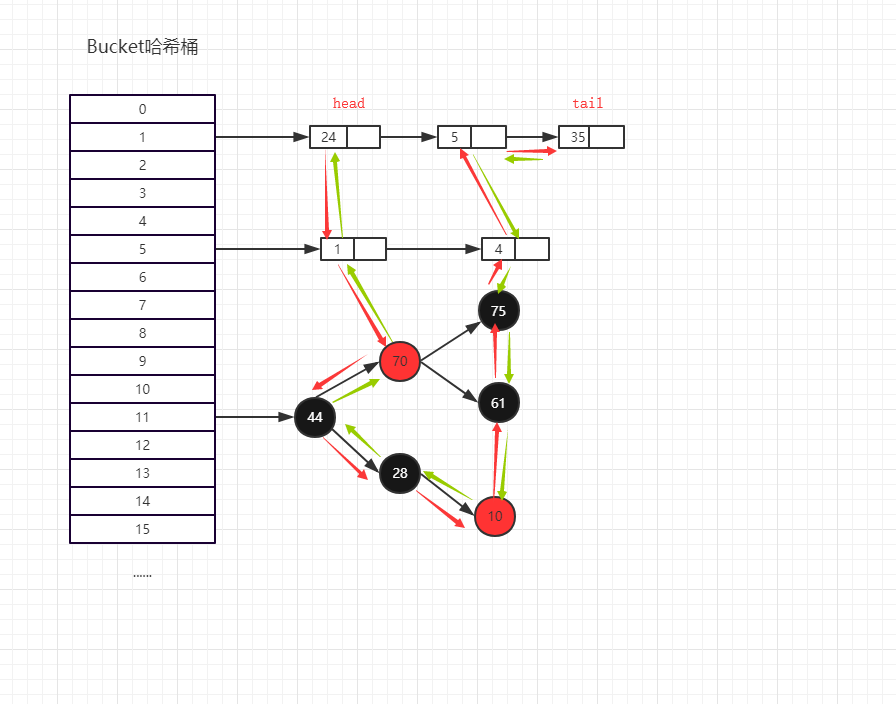
2.2 说明
LinkedHashMap的Entry结构:
/*** HashMap.Node subclass for normal LinkedHashMap entries.* LinkedHashMap的entry在hashmap的基础上多了before和after两个地址,依次来维护顺序。这点和LinkedList一致.*/static class Entry<K,V> extends HashMap.Node<K,V> {Entry<K,V> before, after;Entry(int hash, K key, V value, Node<K,V> next) {super(hash, key, value, next);}}
3.字段
/*** The head (eldest) of the doubly linked list.* 链表的头结点*/transient LinkedHashMap.Entry<K,V> head;/*** The tail (youngest) of the doubly linked list.* 链表的尾结点*/transient LinkedHashMap.Entry<K,V> tail;/*** The iteration ordering method for this linked hash map: <tt>true</tt>* for access-order, <tt>false</tt> for insertion-order.* LRU算法相关* @serial*/final boolean accessOrder;
4.方法
4.1构造方法
public LinkedHashMap() {super();accessOrder = false; // 是否开启LRU缓冲}public LinkedHashMap(int initialCapacity) {super(initialCapacity);accessOrder = false; // 是否开启LRU缓冲}public LinkedHashMap(int initialCapacity, float loadFactor) {super(initialCapacity, loadFactor);accessOrder = false; // 是否开启LRU缓冲}public LinkedHashMap(Map<? extends K, ? extends V> m) {super();accessOrder = false; // 是否开启LRU缓冲putMapEntries(m, false);}
4.2 方法
4.2.1 存储:put方法
public V put(K key, V value) {return putVal(hash(key), key, value, false, true);}// 说明:在这里再次强调一遍:evict参数用于LinkedHashMap中的尾部操作,这里没有实际意义。// onlyIfAbsent参数用于是否覆盖相同key下的value值final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;if ((p = tab[i = (n - 1) & hash]) == null)// 这里调用的是LinkedHashMap的newNode()方法。// 如果理解多态的:这点应该很容易理解tab[i] = newNode(hash, key, value, null);else {Node<K,V> e; K k;if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p;else if (p instanceof TreeNode)e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);else {for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) {// 同上p.next = newNode(hash, key, value, null);if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);break;}if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;p = e;}}if (e != null) { // existing mapping for keyV oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value;// 由LinkedHashMap的实现,并调用// 作用:afterNodeAccess(e);return oldValue;}}++modCount;if (++size > threshold)resize();// 由LinkedHashMap的实现,并调用// 作用:在执行一次插入操作都会执行的操作// 主要就是对LRU算法的支持。// 是否移动最早的元素。但是LinkedHashMap中总是返回false.所以在这里没什么用。afterNodeInsertion(evict);return null;}Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {LinkedHashMap.Entry<K,V> p =new LinkedHashMap.Entry<K,V>(hash, key, value, e);// 作用:将新建的节点添加到维护的双向链表上去// 方式:往链表的尾部进行添加linkNodeLast(p);return p;}// link at the end of listprivate void linkNodeLast(LinkedHashMap.Entry<K,V> p) {LinkedHashMap.Entry<K,V> last = tail;// p为新的需要追加的结点tail = p;// 如果last为null.则表示现在链表为空。新new出来的p元素就是链表的头结点if (last == null)head = p;else {// 否则就是链表中已存在结点的情况:往尾部添加即可// 把新追加p的结点的前驱结点设置之前的尾部结点// 把之前的尾部结点的后驱结点设为新追加的p结点p.before = last;last.after = p;}}
由此可见:LinkedHashMap的在新建一个结点的时候,做了两件事:1.新建结点,并放入到对应的hash桶位置。2.将新建的结点追加到双向链表的尾部。
void afterNodeInsertion(boolean evict) { // possibly remove eldestLinkedHashMap.Entry<K,V> first;// 此方法在LinkedHashMap中总是执行不到。原因见下面。if (evict && (first = head) != null && removeEldestEntry(first)) {K key = first.key;removeNode(hash(key), key, null, false, true);}}// 总是返回false,所有上面的方法总是执行不到protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {return false;}
下面我们我们看一下添加时候的另外一种情况:既不是新建结点、也不是放入到hash桶的位置。而是放到链表或红黑树的情况:
// 作用:将结点元素移到链表的最后位置void afterNodeAccess(Node<K,V> e) { // move node to lastLinkedHashMap.Entry<K,V> last;// 根据LRU原则,只有当元素不在尾部的时候,才需要进行以为操作// 需要move的e结点有以下几种情况:// ①e结点没有前驱结点,有后驱结点情况下:将头结点设为e的后驱结点,然后把e的后驱结点的前驱结点“连接”到e的前驱结点的前驱结点上(这时候为null)。最后把p设为tail结点,置于尾部。// ②e结点没有后驱结点,有前驱结点情况下:将e结点的前驱结点和后驱结点(null)直接相连;并把last结点设为e的前驱结点。最后将p(即e)结点设为tail结点,置于尾部。// ③链表为空情况下:直接将当前结点p,置为链表的head结点。// ④e结点既有前驱结点,也有后驱结点情况下:将p结点的前驱结点和后驱结点直接相连。然后把p结点方法最后一个结点。同时将tail结点赋值为p.if (accessOrder && (last = tail) != e) {LinkedHashMap.Entry<K,V> p =(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;p.after = null;if (b == null)head = a;elseb.after = a;if (a != null)a.before = b;elselast = b;if (last == null)head = p;else {p.before = last;last.after = p;}tail = p;++modCount;}}
4.2.2 获取:get方法
// 说明:调用HashMap的get逻辑;如果获取值为null,则直接返回null。否则判断是否开启了LRU,如果开启的话,就把最近访问的元素放到链表的尾部。最后返回需要获取元素的值。public V get(Object key) {Node<K,V> e;if ((e = getNode(hash(key), key)) == null)return null;if (accessOrder)afterNodeAccess(e);return e.value;}
4.2.3 获取:删除方法
// 这里是:HashMap的删除方法final Node<K,V> removeNode(int hash, Object key, Object value,boolean matchValue, boolean movable) {Node<K,V>[] tab; Node<K,V> p; int n, index;if ((tab = table) != null && (n = tab.length) > 0 &&(p = tab[index = (n - 1) & hash]) != null) {Node<K,V> node = null, e; K k; V v;if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))node = p;else if ((e = p.next) != null) {if (p instanceof TreeNode)node = ((TreeNode<K,V>)p).getTreeNode(hash, key);else {do {if (e.hash == hash &&((k = e.key) == key ||(key != null && key.equals(k)))) {node = e;break;}p = e;} while ((e = e.next) != null);}}if (node != null && (!matchValue || (v = node.value) == value ||(value != null && value.equals(v)))) {if (node instanceof TreeNode)((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);else if (node == p)tab[index] = node.next;elsep.next = node.next;++modCount;--size;// 在删除元素之后,回调钩子方法,进行相关的钩子操作:// 在这里就是:删除节点,删除其关联的维护顺序的双向列表的操作afterNodeRemoval(node);return node;}}return null;}void afterNodeRemoval(Node<K,V> e) { // unlinkLinkedHashMap.Entry<K,V> p =(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;// 此时p节点已删除,将p的前驱和后驱结点均置为nullp.before = p.after = null;// 目的:将a,b结点进行相连操作if (b == null)head = a;elseb.after = a;if (a == null)tail = b;elsea.before = b;}
4.2.4 迭代器
// 首先LinkedHashMap重写了entry的方法// 返回LinkedEntrySet的一个内部类类型public Set<Map.Entry<K,V>> entrySet() {Set<Map.Entry<K,V>> es;return (es = entrySet) == null ? (entrySet = new LinkedEntrySet()) : es;}// 下面是:LinkedEntrySet类的全部代码。在这里我们主要看iterator()方法。其他的方法或代码感兴趣的可以研究,并不难。final class LinkedEntrySet extends AbstractSet<Map.Entry<K,V>> {public final int size() { return size; }public final void clear() { LinkedHashMap.this.clear(); }public final Iterator<Map.Entry<K,V>> iterator() {// 这里返回了LinedEntryIterator对象。下面我们来看看这个对象是什么return new LinkedEntryIterator();}public final boolean contains(Object o) {if (!(o instanceof Map.Entry))return false;Map.Entry<?,?> e = (Map.Entry<?,?>) o;Object key = e.getKey();Node<K,V> candidate = getNode(hash(key), key);return candidate != null && candidate.equals(e);}public final boolean remove(Object o) {if (o instanceof Map.Entry) {Map.Entry<?,?> e = (Map.Entry<?,?>) o;Object key = e.getKey();Object value = e.getValue();return removeNode(hash(key), key, value, true, true) != null;}return false;}public final Spliterator<Map.Entry<K,V>> spliterator() {return Spliterators.spliterator(this, Spliterator.SIZED |Spliterator.ORDERED |Spliterator.DISTINCT);}public final void forEach(Consumer<? super Map.Entry<K,V>> action) {if (action == null)throw new NullPointerException();int mc = modCount;for (LinkedHashMap.Entry<K,V> e = head; e != null; e = e.after)action.accept(e);if (modCount != mc)throw new ConcurrentModificationException();}}// 类LinkedEntryIterator的构成:final class LinkedEntryIterator extends LinkedHashIteratorimplements Iterator<Map.Entry<K,V>> {//在这里调用了nextNode()方法。下面让我们来看看nextNode是个 什么方法。public final Map.Entry<K,V> next() { return nextNode(); }}// nextNode()方法是LinkedHashIterator中的一个方法。// 下面让我们来研究下这个类的大概结构:abstract class LinkedHashIterator {// 存储着要迭代的下一个元素LinkedHashMap.Entry<K,V> next;// 储存着当前迭代的元素对象LinkedHashMap.Entry<K,V> current;// 修改次数。作用见下方。int expectedModCount;// 第一次进来。默认将next节点指向头结点。LinkedHashIterator() {// 将next节点默认指向head结点next = head;expectedModCount = modCount;// 将current 置为nullcurrent = null;}// 判断:下一个节点是否为空public final boolean hasNext() {return next != null;}final LinkedHashMap.Entry<K,V> nextNode() {LinkedHashMap.Entry<K,V> e = next;// 如果在初始化迭代器的过程到初始化结束之前这段时间,集合发生了添加、删除等操作 ,抛出异常if (modCount != expectedModCount)throw new ConcurrentModificationException();if (e == null)throw new NoSuchElementException();// 对象current和next节点进行初始化操作,并返回当前结点current = e;next = e.after;return e;}public final void remove() {Node<K,V> p = current;if (p == null)throw new IllegalStateException();if (modCount != expectedModCount)throw new ConcurrentModificationException();current = null;K key = p.key;removeNode(hash(key), key, null, false, false);expectedModCount = modCount;}}
三、结语
- 学习LinkedHashMap一定要在 理解HashMap的基础上,如果不了解HashMap的请看下HashMap的源码实现这篇文章。
思考
- LinkedHashMap是怎么保证元素有序的?
- LinkedHashMap和HashMap的有什么异同点?
- LinkedHashMap的在设置时用到了哪些Java的思想或设计模式?
看到以上问题,脑子能有清晰的认识和思路。说明真的掌握了LinkedHashMap的源码实现。具体思路在下一章回答。

























")


还没有评论,来说两句吧...