Hive partition 分区表
分区表实际上就是对应一个HDFS文件系统上的独立的文件夹,该文件夹下是该分区所有的数据文件。Hive中的分区就是分目录,把一个大的数据集根据业务需要分割成小的数据集。在查询时通过WHERE子句中的表达式选择查询所需要的指定的分区,这样的查询效率会提高很多。
需求
需要根据日志产生的日期对日志进行管理。
数据准备
[root@hadoop102 stu_part]# pwd/opt/module/hive-1.2.1/datas/stu_part[root@hadoop102 stu_part]# ll总用量 16-rw-r--r--. 1 root root 33 4月 3 17:54 20190429.txt-rw-r--r--. 1 root root 33 4月 3 17:53 20190430.txt-rw-r--r--. 1 root root 33 4月 3 17:54 20190501.txt-rw-r--r--. 1 root root 33 4月 3 17:54 20190502.txt
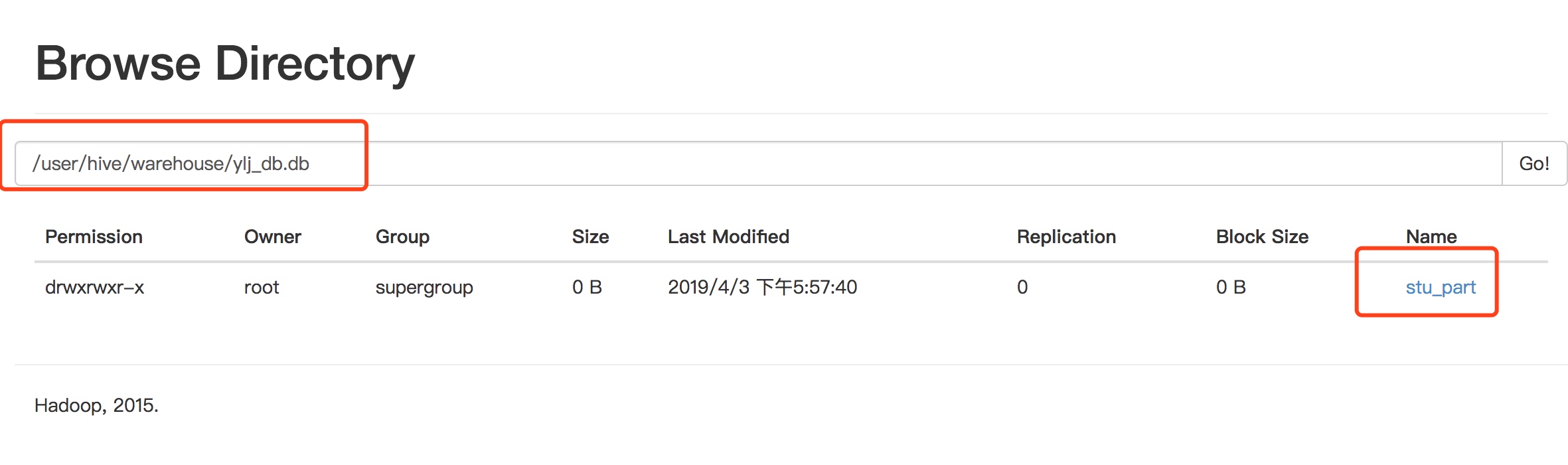
创建分区表
create table stu_part(id int,name string) partitioned by (month string) row format delimited fields terminated by '\t';
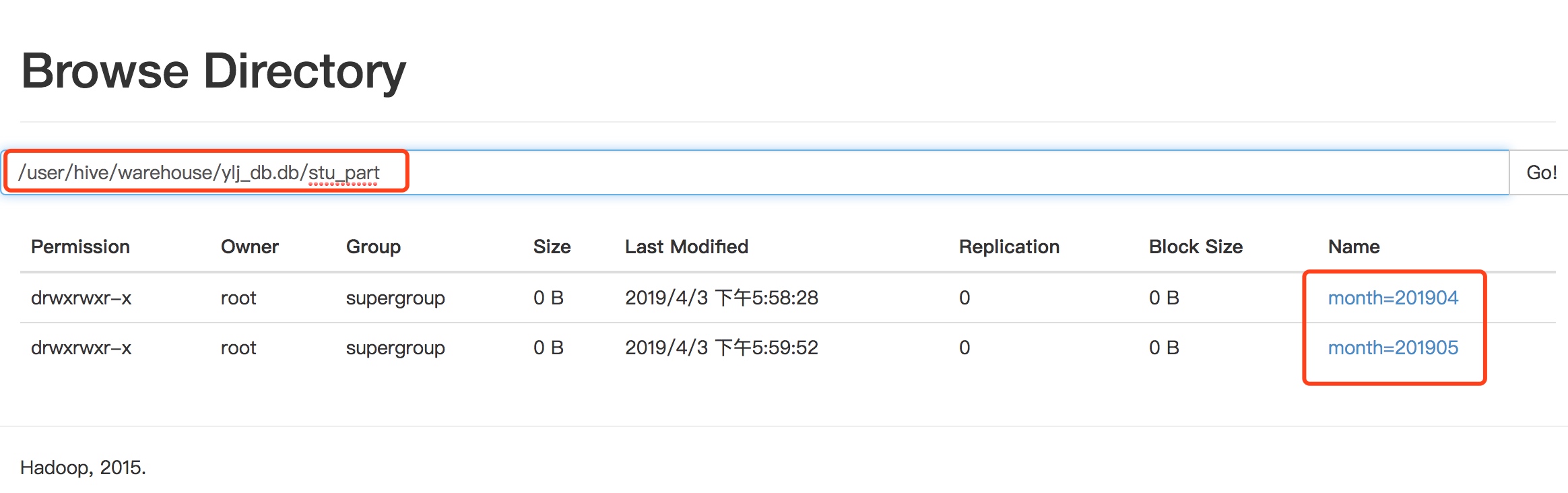
加载数据到分区表中
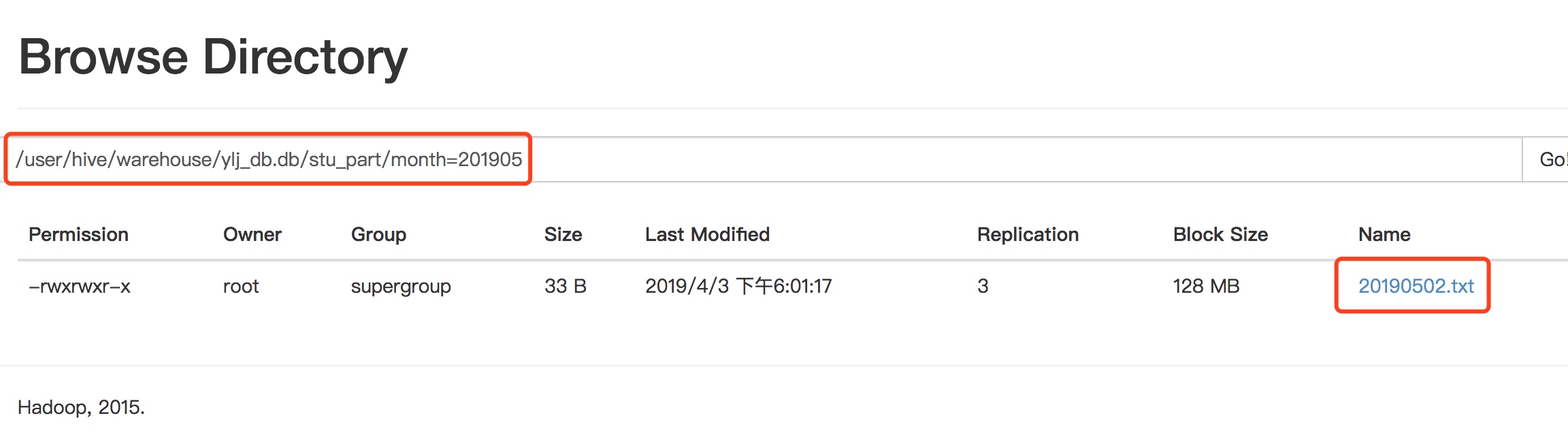
hive (ylj_db)> load data local inpath '/opt/module/hive-1.2.1/datas/stu_part/20190429.txt' overwrite into table stu_part partition(month='201904');Loading data to table ylj_db.stu_part partition (month=201904)Partition ylj_db.stu_part{month=201904} stats: [numFiles=1, numRows=0, totalSize=33, rawDataSize=0]OKTime taken: 0.765 secondshive (ylj_db)> load data local inpath '/opt/module/hive-1.2.1/datas/stu_part/20190502.txt' overwrite into table stu_part partition(month='201905');Loading data to table ylj_db.stu_part partition (month=201905)Partition ylj_db.stu_part{month=201905} stats: [numFiles=1, numRows=0, totalSize=33, rawDataSize=0]OKTime taken: 0.806 seconds
查询
本次查询使用HiveJDBC查询,返回格式好看☺️
全部查询
0: jdbc:hive2://hadoop102:10000> select * from stu_part;+--------------+----------------+-----------------+--+| stu_part.id | stu_part.name | stu_part.month |+--------------+----------------+-----------------+--+| 1 | zhangsan | 201904 || 2 | lisi | 201904 || 3 | houzi | 201904 || 4 | tuzi | 201904 || 1 | zhangsan | 201905 || 2 | lisi | 201905 || 3 | houzi | 201905 || 4 | tuzi | 201905 |+--------------+----------------+-----------------+--+
单分区查询
0: jdbc:hive2://hadoop102:10000> select * from stu_part where month='201904';+--------------+----------------+-----------------+--+| stu_part.id | stu_part.name | stu_part.month |+--------------+----------------+-----------------+--+| 1 | zhangsan | 201904 || 2 | lisi | 201904 || 3 | houzi | 201904 || 4 | tuzi | 201904 |+--------------+----------------+-----------------+--+4 rows selected (0.503 seconds)
多分区联合查询
select * from stu_part where month='201904'unionselect * from stu_part where month='201905'unionselect * from stu_part where month='201906';select * from stu_part where month='201904' or month='201905';
增加与删除分区
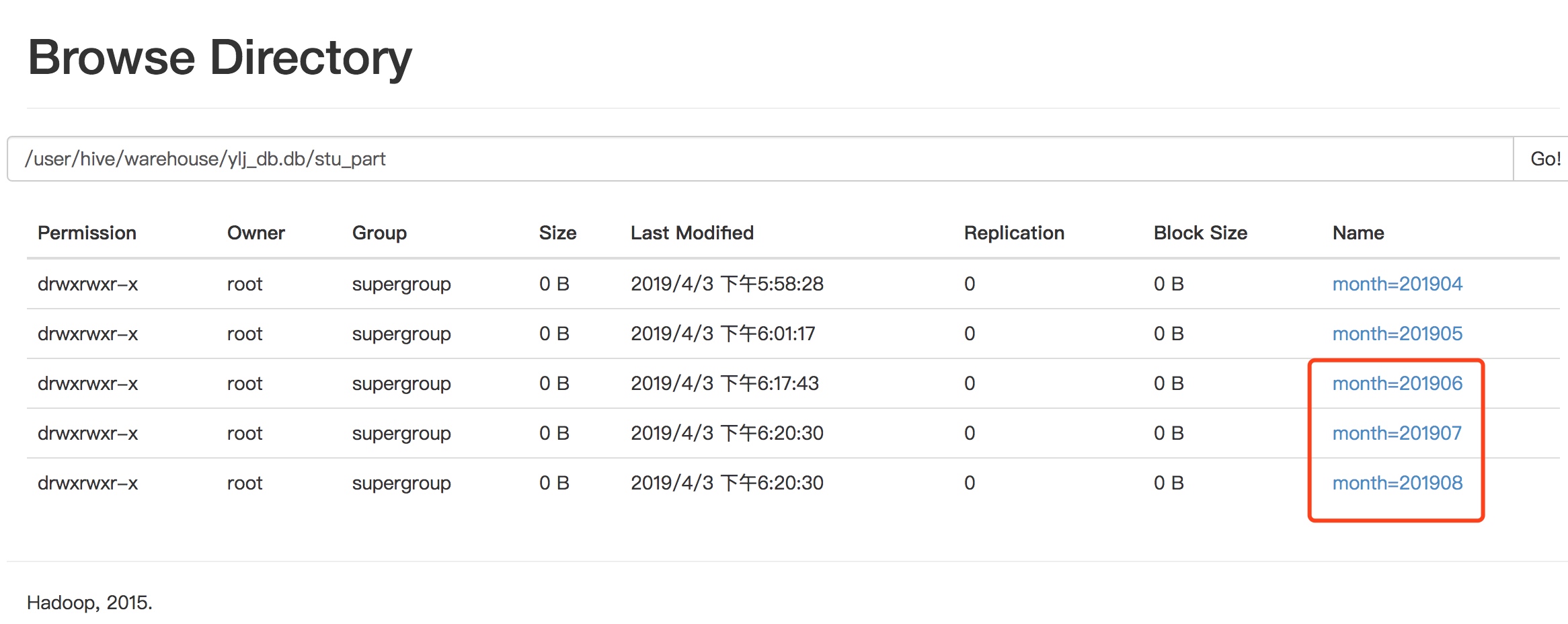
创建单个分区
alter table stu_part add partition(month='201906') ;
同时创建多个分区
alter table stu_part add partition(month='201907') partition(month='201908');
删除单个分区
alter table stu_part drop partition (month='201906');
同时删除多个分区
alter table stu_part drop partition (month='201907'),partition (month='201908');
查看分区表有多少分区
hive (ylj_db)> show partitions stu_part;OKpartitionmonth=201904month=201905Time taken: 0.124 seconds, Fetched: 2 row(s)
二级分区表
创建
create table stu_part2(id int,name string) partitioned by (month string,day string) row format delimited fields terminated by '\t';
正常的加载数据
hive (ylj_db)> load data local inpath '/opt/module/hive-1.2.1/datas/stu_part/20190429.txt' overwrite into table stu_part2 partition(month='201904',day='29');Loading data to table ylj_db.stu_part2 partition (month=201904, day=29)Partition ylj_db.stu_part2{month=201904, day=29} stats: [numFiles=1, numRows=0, totalSize=33, rawDataSize=0]OKTime taken: 0.62 seconds
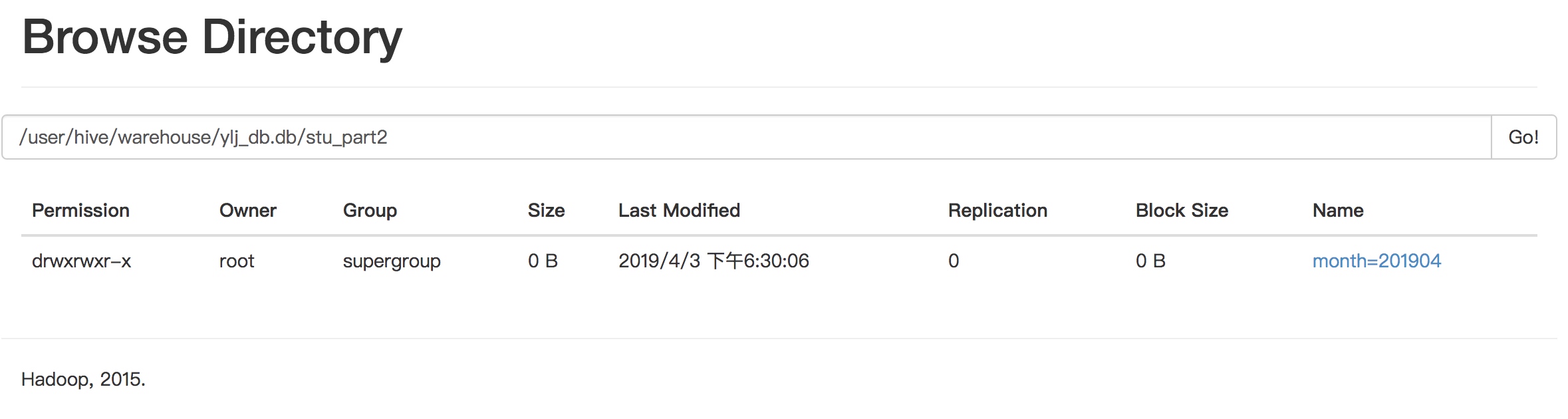
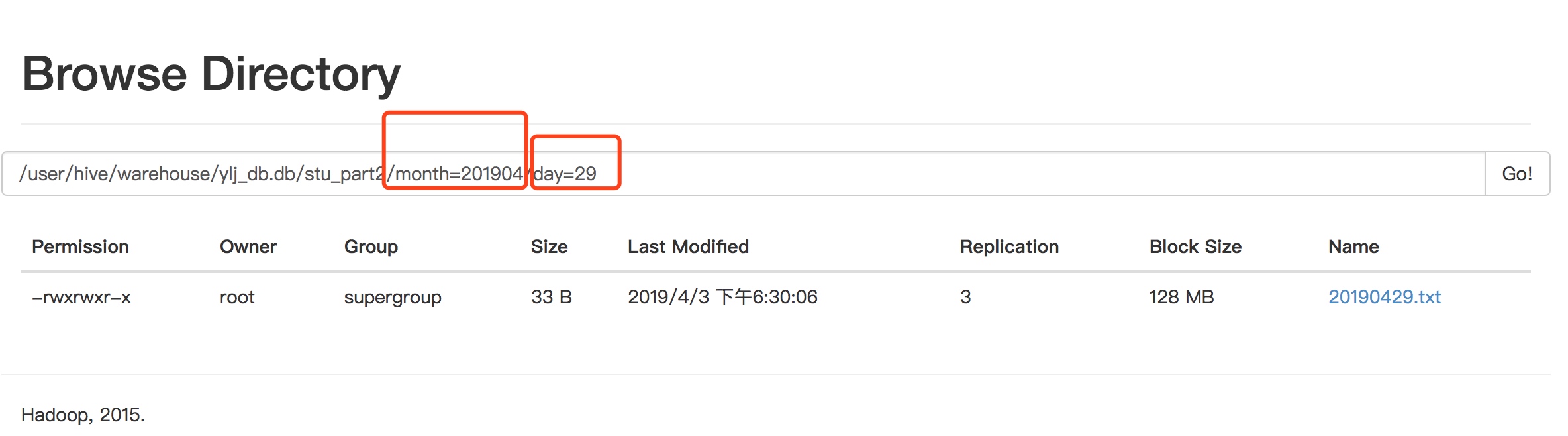
查询数据
hive (ylj_db)> select * from stu_part2 where month='201904' and day='29';OKstu_part2.id stu_part2.name stu_part2.month stu_part2.day1 zhangsan 201904 292 lisi 201904 293 houzi 201904 294 tuzi 201904 29Time taken: 0.244 seconds, Fetched: 4 row(s)
分区表和数据产生关联的三种方式
上传数据后修复
创建分区目录
dfs -mkdir -p /user/hive/warehouse/ylj_db.db/stu_part/month=201906;
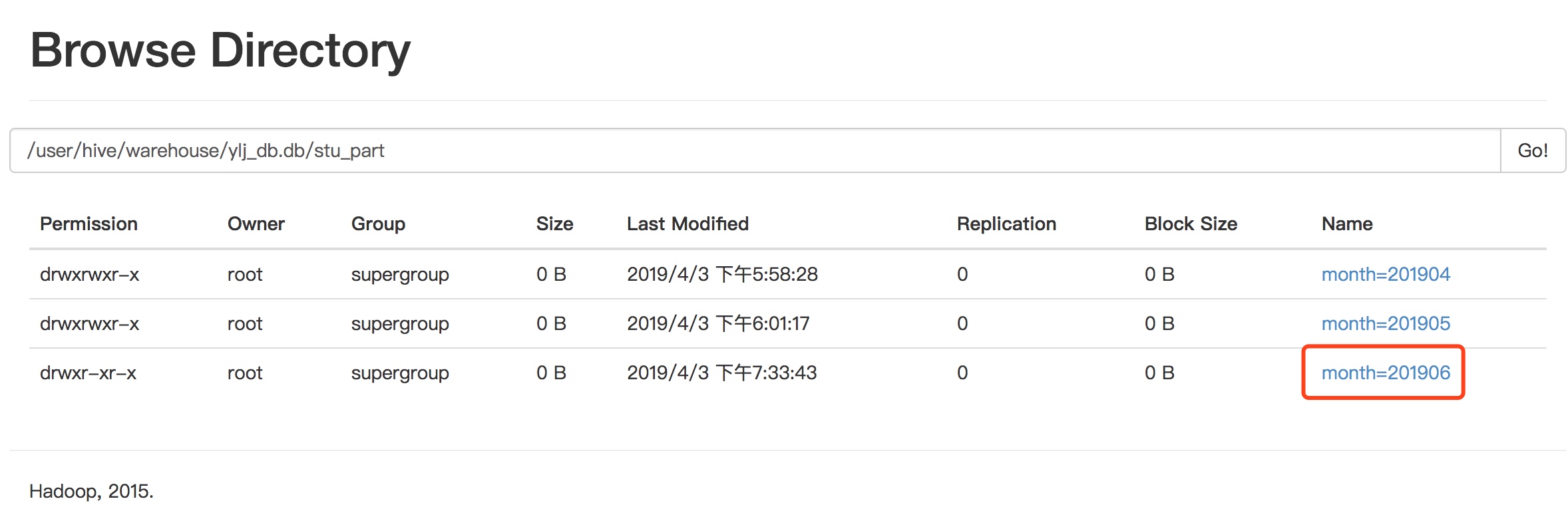
上传数据
dfs -put /opt/module/hive-1.2.1/datas/stu_part/20190601.txt /user/hive/warehouse/ylj_db.db/stu_part/month=201906;
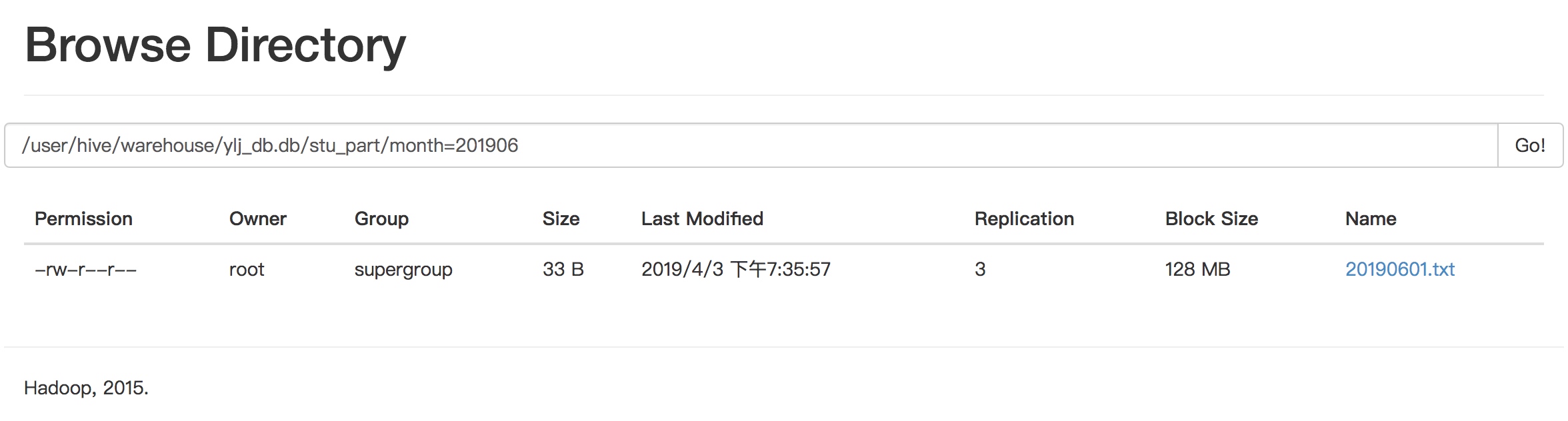
查询数据
刚上传的数据查询不到,因为没有对应的元数据信息。
hive (ylj_db)> select * from stu_part where month='201906';OKstu_part.id stu_part.name stu_part.monthTime taken: 0.16 seconds
执行修复命令
hive (ylj_db)> msck repair table stu_part;OKPartitions not in metastore: stu_part:month=201906Repair: Added partition to metastore stu_part:month=201906Time taken: 0.343 seconds, Fetched: 2 row(s)hive (ylj_db)> select * from stu_part where month='201906';OKstu_part.id stu_part.name stu_part.month1 zhangsan 2019062 lisi 2019063 houzi 2019064 tuzi 201906Time taken: 0.147 seconds, Fetched: 4 row(s)
上传数据后添加分区
上传数据
hive (ylj_db)> dfs -mkdir -p /user/hive/warehouse/ylj_db.db/stu_part/month=201907;hive (ylj_db)> dfs -put /opt/module/hive-1.2.1/datas/stu_part/20190701.txt /user/hive/warehouse/ylj_db.db/stu_part/month=201907;
执行添加分区
alter table stu_part add partition(month='201907');
查询数据
hive (ylj_db)> select * from stu_part where month='201907';OKstu_part.id stu_part.name stu_part.month1 zhangsan 2019072 lisi 2019073 houzi 2019074 tuzi 201907Time taken: 0.128 seconds, Fetched: 4 row(s)
创建文件夹后load数据到分区
创建目录
dfs -mkdir -p /user/hive/warehouse/ylj_db.db/stu_part/month=201908;
load上传数据
load data local inpath '/opt/module/hive-1.2.1/datas/stu_part/20190801.txt' into table stu_part partition(month='201908');
查询数据
hive (ylj_db)> select * from stu_part where month='201908';OKstu_part.id stu_part.name stu_part.month1 zhangsan 2019082 lisi 2019083 houzi 2019084 tuzi 201908Time taken: 0.128 seconds, Fetched: 4 row(s)




























还没有评论,来说两句吧...