关于损失函数的一些个人理解
关于损失函数的一些个人理解
1、损失函数的定义:量化不同的错误到底有多坏
2、SVM损失函数
真实分类的得分要比其他分类的得分高出足够的安全边距,那么损失为0,也就是有足够的能力进行分类了,并且大于足够的阈值后,即能够正确分类了,算法就不管了不再继续了。
一开始用一些很小的随机值来初始化并在第一次迭代时损失函数等于C-1
(1)hinge损失(合页损失)是SVM损失函数的一种,对微小的错误并不在意,但出现很多错误就扩大错误,以纠正的更加正确。
(2)平方hinge损失函数,将错误的分类变得更加大,一点都不想要错误的分类。
3、softmax loss或交叉熵损失
一般用于softmax分类器或者多项式逻辑斯蒂回归
经过softmax后能够得到一个概率分布,softmax的输出向量S是一个概率分布(映射到(0,1)区间)
因为找到log(单调函数)的最大值相对简单,所以用log函数,加负号是因为loss函数是衡量坏的程度而不是好的程度。
并且softmax loss会将正确的分值推向无穷大,错误的推向无穷小,总是不断尝试提高正确的分值,降低错误的分值,使每一个数据点都越来越好,同时也增强了分类器的鲁棒性。
softmax loss公式如下:
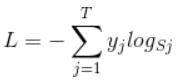
Sj是softmax输出向量S的第j个值,表示这个样本属于第j个类的概率。
cross entropy loss的公式如下:
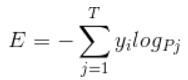


































还没有评论,来说两句吧...