细说Mammut大数据系统测试环境Docker迁移之路
欢迎访问网易云社区,了解更多网易技术产品运营经验。
前言
最近几个月花了比较多精力在项目的测试环境Docker迁移上,从最初的docker“门外汉”到现在组里的同学(大部分测试及少数的开发)都可以熟练地使用docker环境开展测试工作,中间也积累了一些经验和踩过不少坑,借此2017复盘的机会,总结一下整个环境的搭建过程,希望可以给其他有志于向docker迁移的项目提供些许参考,同时也想跟其他docker的老司机们一起探讨改进方式。
Docker迁移的必要性
这篇文章不对docker的基本概念和基本使用进行细讲,网上也有非常多关于docker的资料供大家参考。如果是对docker非常陌生的读者,建议可以自己google一下docker的入门资料,或者推荐大家看一下《第一本Docker书》,可以对docker有一个基本的概念和了解。
但是展开全篇介绍之前,我还是想简单介绍下“Docker迁移的必要性”,记得许家滔在《微服务在微信的架构实践》一文中提过:“技术的演进来源于业务的需求”(原话记不太清了,大致是这样),任何技术的改进不会是无端进行的。
从我们的大数据测试团队来看:
测试人员增加
随着网易猛犸技术团队业务线和人员的扩张,我们的测试人员从之前的2-3个已经增长到了现在的7-8个,未来是否会继续扩张不得而知。
测试类型丰富
从最初的仅有功能测试保障,到现在自动化测试、异常测试、稳定性测试、性能测试、tpcds兼容性/基准测试多种类型同步铺开。
多版本并行开展
随着产品方“对外私有化部署”和“内部版本开发”两条线的同时推进,我们经常会面临需要多版本同步测试的处境,而且后端组件可能同时需要测试“社区版本”和“内部开发版本”两个版本。
伴随着上述三方面的影响,而我们有且仅有一套测试环境。在测试过程中,经常会出现某一个人在执行测试活动时,其他测试人员被block,需要等待其执行完成后,再开始自己的测试,而且测试执行时不能被其他人影响的情况。此外,最近的一个版本上线后,出现了一个线上问题是跟“跨集群”业务有关的功能,而这一块在上线前不论是开发还是测试都是没有测试过的,因为无论是测试还是开发,我们都只部署了一套集群,没有办法进行跨集群的测试,仅通过开发的Code Review来保证上线。
至于为什么我们不再多部署几套测试环境呢?大数据整套系统非常的庞大,下面是我简单罗列的大数据组件的种类(可能会有遗漏):
1. Mammut:Webserver、Executor、Redis Server、MySQL2. Azkaban:Az-FC、Az-Webserver、Az-Executor、MySQL3. Hadoop-Meta:Scheduler RPC、Service、KDC-RPC、MySQL4. Kerberos:KDC Server、Kadmin、Kerberos Client5. LDAP:Client、LDAP Server、LdapAdmin Server6. Hive:HiveServer2、Hive Metastore、Hive Client、MySQL7. Spark:Spark History Server、Spark Thrift Server、Spark Client8. Ranger:RangerAdmin、MySQL9. HDFS:NameNode、DataNode、JournalNode、HDFS Client、ZKFailoverController10. YARN:ResourceManager、NodeManager11. MapReduce:MapReduce History Server、MapReduce Client12. ZooKeeper:Zookeeper Server、Zookeeper Clinet13. Ambari:Ambari Server、Ambari Agent、MySQL14. Hbase:待补充15. Impala:待补充
组件的种类大致有15类,每个组件各自有自己的多个服务需要部署,并且其中大部分(80%以上)的服务都是集群式地多节点部署以支持高可用/负载均衡。从我们测试环境的Ambari管理页面上看下我们具体部署的组件数量:
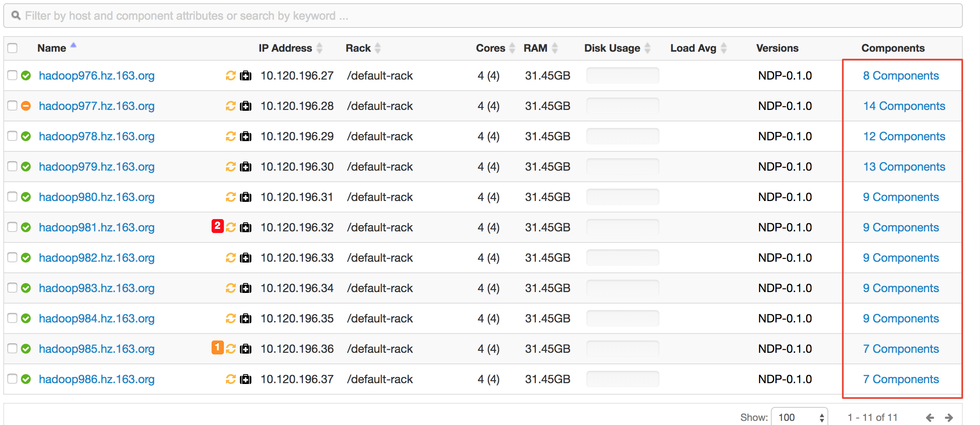
可以看到集成Ambari的“进程”级别的组件数量已经总计多达106个,还不包括其它未集成ambari的组件,如hadoop-meta、ldap、hbase、impala等等。
上述介绍的是猛犸系统的组件规模,而部署一套系统的成本到底有多大?记得在我们第一次进行私有化部署演练的时候,当时还没有使用ambari,项目组让每个开发、运维事先整理好自己所要部署的组件的详细操作记录,然后十来个开发加运维一起坐在“小黑屋”,部署了三天,没有部署成功。更不用说,部署完成后,投入使用过程中的环境维护成本。如果离开ambari,相信没有多少人敢独自去部署一套猛犸系统。
在“环境亟待扩张”和“环境搭建维护成本巨大”的矛盾对立下,将测试环境向docker迁移的思路应运而生,docker的引进可以很好地解决我们的困境。
下面开始进入正题,介绍整个测试环境向Docker迁移演化的过程。主要包含的内容如下:
- 基于Ambari的容器镜像制作
- 基于Swarm的容器云搭建
- 跨云主机的容器私有网络组建和容器内部通信
- 支持多套环境的容器管理和组网方案
- 基于镜像的环境自动部署
- Rancher——集群环境的监控和管理
1.基于Ambari的容器镜像制作
首先介绍下镜像的制作过程。大家都知道,docker的镜像制作有两种方式:
(1)基于容器的commit (2)基于Dockerfile的构建
从Docker官方的推荐和业界大量的实践证明,Dockerfile是更好的镜像制作方式,它从一个基础镜像开始,记录所有的操作过程,以及workspace、环境变量、volumn卷挂载、端口映射等一系列的重要信息。并且,它是可重录的,在任何安装了docker的环境下,只要基于一份简单的Dockerfile文件就可以构建出所要的镜像。当镜像发生更改时,也只需要修改部分内容,即可以完成新镜像的构建。对于频繁更新的镜像来说,这绝对是一种最佳的实践方式,因为从基础镜像到目标镜像的所有操作一目了然,不会引入额外的冗余文件系统。
然而,在大数据组件的镜像制作过程中,并没有采用Dockerfile的方式,而是选择了第一种commit的方式。这主要是因为前面介绍过了大数据组件规模的庞大,如果要为每个组件的每个服务去制作单独的镜像,可能需要制作上百个镜像,并且,各个组件的服务之间存在着繁杂的依赖关系,不管是采取何种方式(组件间的依赖处理一般有两种方式:1.手动地将服务的端口映射到宿主机的端口,依赖服务调被依赖服务所在宿主机的相应端口;2.借助编排工具,如compose、kubernetes等,创建service,处理service之间的关系),我觉得由我一个人在短时间内都是无法实现的,更不论你需要去详细了解每个组件的单独部署方式。
此外,因为我们的私有化部署环境和现有测试后端集群的搭建都是基于Ambari(大数据环境部署工具,可以通过ambari-server将众多集成的大数据组件,批量部署到若干台安装了ambari-agent的机器上)搭建的,如果我们脱离ambari去制作各个单独的组件服务镜像,即使最终组合到一起成功完成环境的搭建,那与我们现有的环境也是不相符的。
基于上述背景,我们采取了一种新的环境搭建思路:
(1)使用基础镜像(如debian7官方镜像),先启动一组容器(比如8个)(2)在其中一个容器上部署ambari-server,在每个容器上部署ambari-agent(3)使用Ambari Web将集成了ambari的大数据组件(如Hive、Azkaban、YARN、Zookeeper、Spark、HDFS、Mammut、Ranger、MapReduce等)部署到各个容器内部(4)在各个容器内手动部署未集成ambari的组件(如Hadoop-meta、LDAP、Kerberos等)(5)执行docker commit将全部8个容器制作为“容器镜像套件”
而容器间的通信方式,最容易实现的当然是借助端口映射,将容器内部端口映射到宿主机端口,通过访问宿主机IP加端口的方式来通信。但是,ambari-web在配置各个组件服务的地址时,有一部分配置必须使用主机名的格式,不支持ip加host的方式。而且考虑到后续想要在多套环境中基于镜像去快速部署,基于ip加端口的方式显然会对扩展造成严重的阻碍,需要额外地编写脚本去动态获取对端服务的宿主机ip、映射端口,甚至可能在部署完成后需要对一些配置进行大量手动修改。
为了解决上述问题,在我们的镜像制作过程中,采取了固定hostname的方式。为每个容器加上特定的hostname(mammut-qa-docker-1.server.org~mammut-qa-docker-8.server.org),这样在任何需要配置服务依赖的地方,我们可以直接填写对端服务的hostname。而容器之间的通信,我们为每套大数据环境,创建一个特定的私有网络(network),将同一套环境的容器挂载到同一个特定网络下,这样每个容器会被分配到一个私有ip,同一个私有网络下的私有ip之间是互通的。然后通过自动化脚本去修改每个容器内部的/etc/hosts文件,添加ip-hostname的映射到容器内部的路由列表中。
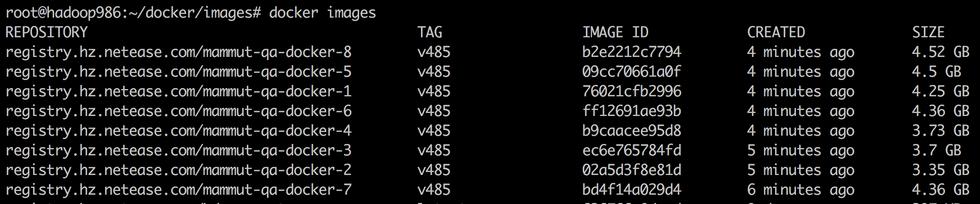
到此,介绍了基于ambari的镜像制作思路和容器内部通信的方式。已经可以在一台物理机器上,完成整套大数据环境的搭建。然而,在实践过程中发现,整个容器的镜像套件,文件“体积”非常地大:

整个镜像套件占用的磁盘空间可达到70多G。对于一个新的机器,去下载70G的镜像,显然还是需要挺久的时间。通过对镜像内部文件的分析,可以发现,镜像中有一大部分的文件来自于ambari-web在部署组件过程中产生的日志文件,存储在各个容器内部的/var/log文件下,而这部分日志其实并不是我们部署所必须的,完全可以不打进镜像中。因此,通过将/var/log目录以volumn卷方式挂载到宿主机磁盘中,重新制作镜像,整个镜像套件的“体积”大幅度缩小,约30G:
2.基于Swarm的容器云搭建
上节介绍了容器镜像的制作,已经可以在一台物理机上完成整套环境的搭建。然而,对于我们大多数项目来说,物理机资源是非常奢侈和稀缺的,我们不太可能让公司采购那么多的高规格的物理机。相对来说,云主机资源比较容易申请。目前通过“运维夸父系统”申请的云主机的配置可以达到8核cpu、32G内存、挂载500G云盘。显然,这么多的组件如果要全部部署在一台云主机上,暂不说该云主机是否可以支持这么多的进程资源,即使你部署成功,后续在执行任务的时候肯定会出现资源不足的场景,要知道你的机器要支持的可是YARN、HDFS等。所以,如何将多台云主机联合起来组成一个容器云,让镜像套件中的8个容器镜像,分散地部署到不同的云主机上,成为我们一个突破机器瓶颈的思路。
业界处理容器编排的主要工具有Kubernertes、Swarm、Mesos。从GitHub上的活跃度来说,Kubernetes是远超其它二者。而且,沸沸扬扬的容器编排之争最近也已经结束,Kubernetes成为了容器编排最佳实践的典范,Docker官方也已经宣布在下一个企业版本开始支持Kubernetes。然而,通过对Kubernetes的调研,它非常依赖于严格的微服务的架构,通过yaml可以很容易处理好服务之间的关系,非常适合企业级应用的生产环境部署。而我们的环境,实际上是通过ambari将多个不同组件服务揉合到了一起,并没有为每个组件去制作单独的镜像。组件之间的依赖配置还严格依赖于特定的主机名,从各个角度来看Kubernetes都不适用于我们的场景(当然我并不是反对使用k8s,其实我是很想使用k8s。但是要使用k8s的前提应该是需要为每个服务去制作单独的镜像,而不是杂糅在一起,可能需要去除ambari工具的使用,这需要更上层的架构师来推动。此处如果我的理解有偏差,希望k8s的前辈指出)。
而Swarm(官方原生支持),基于容器的调度,可以说是非常适合我们的场景。将多台云主机联合成一个容器集群,通过swarm-manage将这批容器镜像调度到不同的云主机上,即可完成容器的部署。同时,如果环境中的云主机出现资源不足的场景,我们可以很方便地添加新的机器,然后将环境部署到更多的云主机上来实现动态扩容。
关于Swarm集群的搭建,官方的样例中,服务发现使用的是Consul,其实Consul包含的功能Zookeeper都有。由于对Zookeeper更加熟悉,就使用了 Zookeeper来代替Consul做了服务发现后端(discovery backend)。
3.跨云主机的容器私有网络组建和容器内部通信
不同于Kubernetes其自身有健全的网络机制,通过pod可以很好的管理service的网络,Swarm并没有提供任何容器间网络的支持。所以,我们需要自己解决当容器被调度到多个不同的云主机之后,它们之间的通信问题。
前面提到过,在一台云主机上,我们可以创建一个私有网络,然后将8个容器全部挂载到该私有网络下,让它们各自拥有自己的私有ip,然后添加ip-hostname的映射,以支持通过hostname的方式互相通信。现在容器被分配到了不同的云主机上,是否还可以创建这样的私有网络呢?
幸运的是,docker1.9版本之后,docker采用VXLAN的覆盖网技术,原生地提供了对“跨宿主机组网”非常便利的支持。
这里简要介绍下跨主机组网的实现方式,对于实践过程中遇到问题的同学可以再私下单独探讨 。
(1)部署服务发现后端,如Zookeeper(2)修改DOCKER_OPTS,加入-H tcp://0.0.0.0:2375 -H unix:///var/run/docker.sock --cluster-advertise=eth1:2375 --cluster-store zk://zk_path,重启docker进程(3)创建overlay网络 :docker network create -d overlay netzni(4)创建docker_gwbridge网桥:docker network create --subnet 192.168.48.0/20 \--opt com.docker.network.bridge.name=docker_gwbridge \--opt com.docker.network.bridge.enable_icc=false \--opt com.docker.network.bridge.enable_ip_masquerade=true \docker_gwbridge(5)创建容器加入网络:docker run --net netzni {image}(6)将已经运行的容器加入网络:docker network connect netzni {container}
其中第2步是将云主机加入集群中,让集群知道有哪些机器在集群中。-H tcp://0.0.0.0:2375是开启通过tcp socket的方式访问本机的docker进程,默认情况下本地的docker进程只有-H unix://var/run/docker.sock的方式,即只支持unix socket的方式访问本地docker进程。而eth1,必须是你云主机机房网ip对应的网卡。如果是debian8的系统,修改DOCKER_OPTS参数会出现不生效的问题,可以参见附录中第1个问题的解答。
对于第4步,创建docker_gwbridge网桥,这个网桥的作用在跨主机容器网络中的作用就相当于单主机容器网络中的docker0网桥的作用,用于连通不同主机容器之间的通信网络。
自此,我们又实现了在不同云主机环境下的私有网络的创建,仔细观察容器内部的网络可以看到:
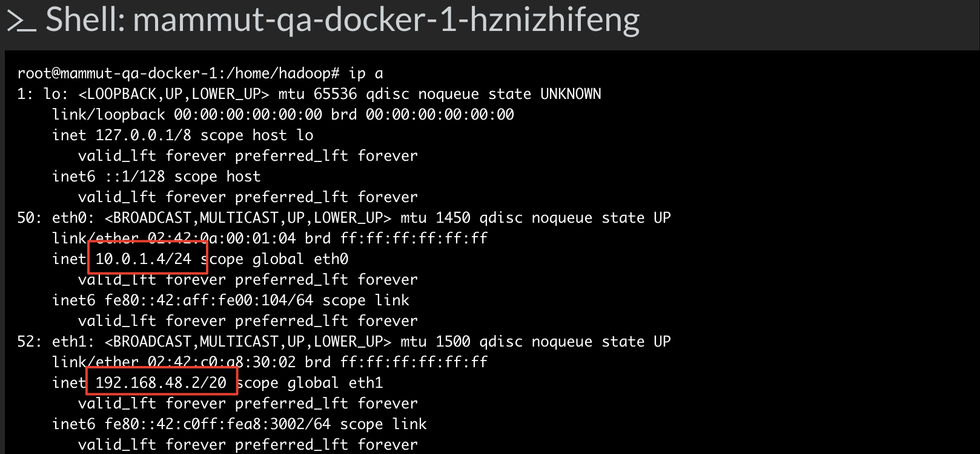
每个容器内部有两个虚拟网卡,eth0对应的就是私有网络分配的私有ip,而eth1对应的就是docker_gwbridge网桥分配的ip。当两个容器通过私有ip进行互相通信时,需要经过docker_gwbridge网桥的转发。
类似地,当跨主机的容器部署完成后,我们也需要通过自动化脚本去预置每个容器内部的/etc/hosts文件,加上ip-hostname的映射。
4.支持多套环境的容器管理和组网方案
前面介绍了如何在多台云主机上搭建私有网络以及部署容器。那么当部署的环境逐渐增多时,我们如何去部署和管理多套不同的环境呢?答案还是Swarm。
Swarm提供了“Label”的功能,即可以给每个云主机贴上相应的标签。所有基于docker搭建的大数据环境,都加入到一个统一的Swarm集群,受同一个swarm-manage管理。对不同的机器,给它们贴上对应的标签。比如我有一批新的机器,都给它们都贴上“onwner=hznizhifeng”的标签,表明是用来部署我的一套测试环境。然后相对应地,创建一个overlay私有网络networkl_hznizhifeng。在使用swarm-manange进行容器调度时,通过过滤地方式指定容器可以被调度的机器,以及指定容器需要加入的网络名,如:
docker -H ${HOST} run -d -e constraint:owner==${OWNER} --net network_${OWNER} --name mammut-qa-docker-7-$OWNER ${REGISTRY}/mammut-qa-docker-7:${VERSION} ./startup.sh
可以看到,容器名字的命名也可以通过{OWNER}来进行区分。
5.基于镜像的环境自动部署
在完成前期的环境搭建工作后,我们需要将整个部署过程整合成自动化脚本,以实现快速部署,并降低部署的门槛,使得任何测试人员都可以轻松地完成环境部署。
下面简单列下几个部署脚本的内容,其它项目使用时可以参考。
(1)debian_init.sh:完成新机器环境的初始化工作,包括安装docker、给docker守护进程打上owner标签、 挂载云盘、加入docker swarm集群、创建docker_gwbridge网桥、创建docker私有网络等。
(2)mammut-docker-service.sh:容器调度脚本,包含容器启动、停止、镜像提交等。
(3)reset_container_hosts.sh:修改容器内部的hosts文件,预置ip-hostname的映射关系。
(4)setup_hosts.py:python脚本,获取各个容器与所被分配到的云主机之间的映射信息
关于gitlab的权限,有兴趣的可以私下popo联系我开通访问。
在自动化脚本编辑过程中,有几个有意思的实现方式可以给大家介绍下:
(1)容器镜像的拉取
从前文可以看到,我们即使使用了volumn卷对日志文件进行挂载,但是镜像套件“体积”依然有30G,如何提升拉取速度呢?我们可以在shell脚本里,在脚本命令后增加“&”的方式,将该条拉取命令挂到后台执行,以实现多线程拉取的方式提升拉取镜像的速度,然后在后面加上“wait”命令,以等待所有线程执行完了再执行后续的命令。
docker -H ${HOST} run -d -e constraint:owner==${OWNER} --net network_${OWNER} --name mammut-qa-docker-7-$OWNER -h mammut-qa-docker-7.server.org -v /root/log/mammut-qa-docker7:/var/log -p3306:3306 -p8080:8080 --cap-add=ALL ${REGISTRY}/mammut-qa-docker-7:${VERSION} ./startup.sh &docker -H ${HOST} run -d -e constraint:owner==${OWNER} --net network_${OWNER} --name mammut-qa-docker-6-$OWNER -h mammut-qa-docker-6.server.org -v /root/log/mammut-qa-docker6:/var/log -p80:80 -p8042:8042 --cap-add=ALL ${REGISTRY}/mammut-qa-docker-6:${VERSION} ./startup.sh &docker -H ${HOST} run -d -e constraint:owner==${OWNER} --net network_${OWNER} --name mammut-qa-docker-1-$OWNER -h mammut-qa-docker-1.server.org -v /root/log/mammut-qa-docker1:/var/log -p18081:18081 -p10000:10000 -p50070:50070 ${REGISTRY}/mammut-qa-docker-1:${VERSION} ./startup.sh &docker -H ${HOST} run -d -e constraint:owner==${OWNER} --net network_${OWNER} --name mammut-qa-docker-2-$OWNER -h mammut-qa-docker-2.server.org -v /root/log/mammut-qa-docker2:/var/log -p19888:19888 ${REGISTRY}/mammut-qa-docker-2:${VERSION} ./startup.sh &docker -H ${HOST} run -d -e constraint:owner==${OWNER} --net network_${OWNER} --name mammut-qa-docker-3-$OWNER -h mammut-qa-docker-3.server.org -v /root/log/mammut-qa-docker3:/var/log -p8088:8088 ${REGISTRY}/mammut-qa-docker-3:${VERSION} ./startup.sh &docker -H ${HOST} run -d -e constraint:owner==${OWNER} --net network_${OWNER} --name mammut-qa-docker-4-$OWNER -h mammut-qa-docker-4.server.org -v /root/log/mammut-qa-docker4:/var/log -p8088:8088 --cap-add=ALL ${REGISTRY}/mammut-qa-docker-4:${VERSION} ./startup.sh &docker -H ${HOST} run -d -e constraint:owner==${OWNER} --net network_${OWNER} --name mammut-qa-docker-5-$OWNER -h mammut-qa-docker-5.server.org -v /root/log/mammut-qa-docker5:/var/log -p50070:50070 -p8042:8042 ${REGISTRY}/mammut-qa-docker-5:${VERSION} ./startup.sh &docker -H ${HOST} run -d -e constraint:owner==${OWNER} --net network_${OWNER} --name mammut-qa-docker-8-$OWNER -h mammut-qa-docker-8.server.org -v /root/log/mammut-qa-docker8:/var/log -p10001:10001 -p6080:6080 ${REGISTRY}/mammut-qa-docker-8:${VERSION} ./startup.sh &wait
(2)容器内部hosts文件预置ip-hostname的映射关系
当容器部署完成后,我们可以通过docker network inspect network_hznizhifeng的方式,来查看该私有网络下各个容器所分配到的私有ip信息,该信息是一个json格式,通过对该json的解析,便可以得到每个hostname对应的ip地址。这边用的是python的方式,解析脚本可以参考:
#!/usr/bin/python# -*- coding: utf-8 -*__author__ = 'zni.feng'import osimport sysreload (sys)sys.setdefaultencoding('utf-8')import jsonclass HostsParser:def __init__(self, owner):self.owner = ownerself.network_info_file = 'docker_network_%s' % ownerself.network_info_dict = Noneself.ip_hosts_mapping = list() def get_network_info(self):if not self.network_info_dict: with open(self.network_info_file, 'r') as f:self.network_info_dict = json.load(f)[0] return self.network_info_dict.copy() def get_ip_host_mapping(self):if not self.ip_hosts_mapping:network_info_dict = self.get_network_info()containers_dict = network_info_dict['Containers'] for container in containers_dict.values():ipv4 = container['IPv4Address'].split('/')[0]hostname = container['Name'][:container['Name'].find(self.owner)-1]ip_hosts_mapping="{0} {1}.server.org".format(ipv4, hostname)self.ip_hosts_mapping.append(ip_hosts_mapping) return self.ip_hosts_mapping def save_hosts(self):ip_hosts_mapping = self.get_ip_host_mapping()open('hosts','w').write('%s' % '\n'.join(ip_hosts_mapping))if __name__ == '__main__': if len(sys.argv) <2: print 'USAGE: python setup_hosts.py [LABEL]'print 'LABEL: hznizhifeng|hzzhangyongbang|hzzhangjun15|e.g.'sys.exit(1)owner = sys.argv[1]parser = HostsParser(owner)parser.save_hosts()
6.Rancher——集群环境的监控和管理
完成集群的自动部署后,我们的测试集群已经可以轻松的部署使用了。并且,通过swarm-manage也可以对集群的容器进行管理。但是,swarm并没有提供集群的监控,以及没有友好的管理页面。自然而然,我们希望有一种类似Web页面的方式,可以对集群进行监控和管理。
在对业界的一些集群监控工具进行了调研后,最终选择了Rancher(http://rancher.com/)作为我们的集群管理工具。它可以跟Kubernetes、Swarm等都很好地兼容,并提供了ldap等权限管理的方式,和丰富的管理api。此外它的一大特色就是它的“镜像应用商店”,就好像App Store一样。
Rancher的架构跟Swarm类似,由一个rancher-manage,多个rancher-agent和一个mysql组成。其部署方式这里不细讲,大家可以参考下rancher的官方文档,或者私下交流。
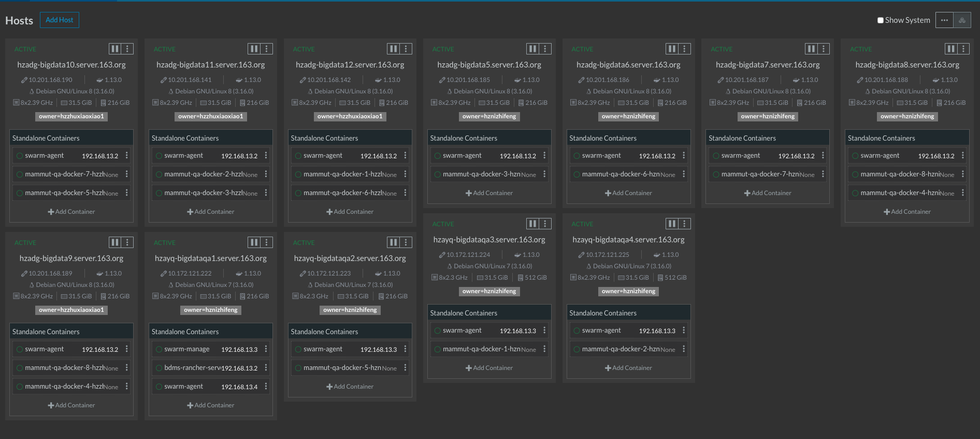
下面截两张rancher界面的图,看看是不是你想要的:
(1)Rancher机器管理页面
(2)Rancher容器监控页面
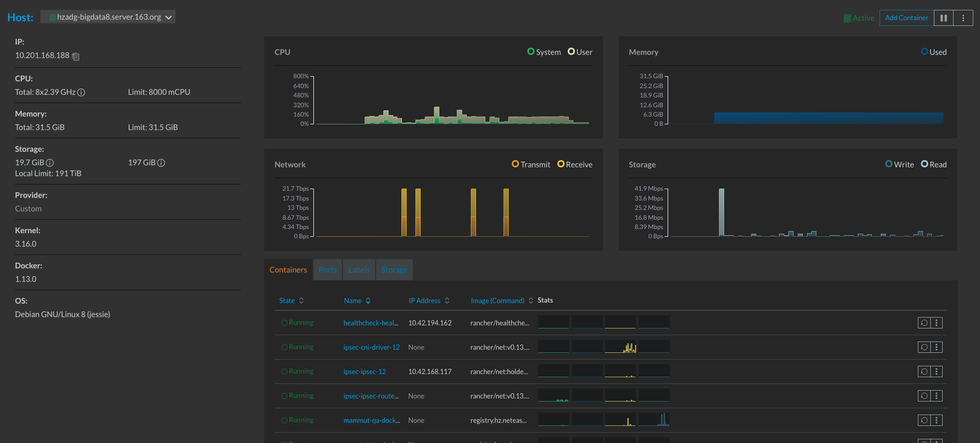
此外,我们还可以在Rancher页面上进入集群中的任一容器,进行内部操作,截图可见“3.跨云主机的容器私有网络组建和容器内部通信”这一节中的图。
总结和展望
能耐着性子看完的,相信都是真的想使用docker进行环境迁移的“真爱粉”,以及愿意指点迷津帮助我们继续改进的老司机。
从目前的现状来看,我觉得当前的docker环境基本满足了我们测试的需要,但是从整个大数据系统的部署来说,肯定不是最佳实践。我相信如果能将各个组件制作成单独的镜像,借用k8s的service理念,肯定是可以让整个结构更加完善。
从版本升级和镜像维护的角度来说,我们目前其实是比较痛苦的。因为没有使用Dockerfile,我们需要基于已有的镜像,不断地叠加新的文件系统然后commit,中间势必会引入冗余的操作影响容器的整个“体积”。因为没有为每个服务制作单独的镜像,不容易实现单个服务镜像的升级。目前,我们也只是人为地建立了一套“版本镜像套件升级规范”,以一个版本为一个迭代的方式,统一升级全部的镜像套件。
目前,我们所有的部署操作都是在后台执行脚本的方式来完成自动部署。未来,我们可以基于我们已有的技术栈,搭建一个基于docker的测试平台,来实现环境的自动部署、回收、扩容,以及基于大数据的特点,实现多类型数据源(如DDB、Oracle、SQLServer、MySQL、PostgreSQL等)的一键生成和自动化测试工作。
附录
- debian8系统/etc/default/docker配置没生效的问题
(1)修改/etc/default/docker文件,用OPTIONS替代DOCKER_OPTS。如:OPTIONS="--insecure-registry registry.hz.netease.com -H tcp://0.0.0.0:2375 -H unix:///var/run/docker.sock"(2)修改/lib/systemd/system/docker.service文件,加入EnvironmentFile,并在ExecStart中加入$OPTIONSEnvironmentFile=-/etc/default/dockerExecStart=/usr/bin/dockerd $OPTIONS -H fd://(3)执行systemctl daemon-reload使之生效(4)重启docker守护进程: /etc/init.d/docker restart(5)ps -ef|grep docker 或 docker info 看配置是否生效
网易大数据为您提供网易猛犸等服务,欢迎点击免费试用。
本文来自网易实践者社区,经作者倪志风授权发布。
相关文章:
【推荐】 基于Redis+Kafka的首页曝光过滤方案
【推荐】 完善的IaaS云服务的个人理解


































还没有评论,来说两句吧...