hadoop集群环境搭建
1、环境准备
192.168.33.138 master
192.168.33.139 slave1
192.168.33.140 slave2
2、更改主机名称
vi /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=master


3、修改host文件
vi /etc/hosts
192.168.33.138 master
192.168.33.139 slave1
192.168.33.140 slave2

检查是否能ping通
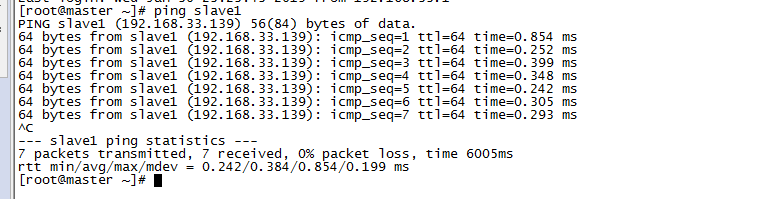
4、配置ssh免密码登录
在root用户下输入ssh-keygen -t rsa 一路回车
秘钥生成后在~/.ssh/目录下,有两个文件id_rsa(私钥)和id_rsa.pub(公钥),将公钥复制到authorized_keys并赋予authorized_keys600权限
cd ~/.ssh/
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
cat authorized_keys

将master节点上的authoized_keys远程传输到slave1和slave2的~/.ssh/目录下
scp ~/.ssh/authorized_keys root@slave1:~/.ssh/
scp ~/.ssh/authorized_keys root@slave2:~/.ssh/

在slave1和slave2节点执行以上步骤生成秘钥,然后将id_rsa.pub文件中的秘钥复制到master节点上的authoized_keys文件中

检查是否免密登录(第一次登录会有提示)
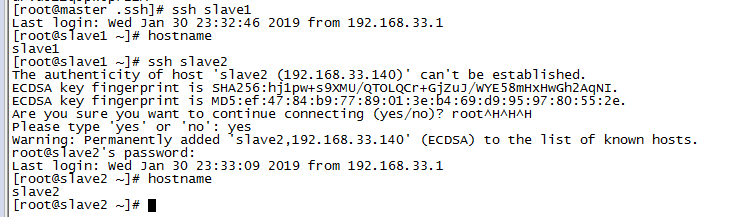
5、安装JDK
参考: https://blog.csdn.net/qq_38270106/article/details/83048876
6、安装MySQL(master节点)
参考:https://blog.csdn.net/qq_38270106/article/details/84780576
7、集群结构
新建hadoop用户及其用户组
groupadd hadoop
useradd -g hadoop hadoop
passwd hadoop
赋予hadoop用户root权限
vi /etc/sudoers
hadoop ALL-(ALL) ALL

8、安装hadoop并配置环境变量
由于hadoop集群需要在每一个节点上进行相同的配置,因此先在master节点上配置,然后再复制到其他节点上即可。
将hadoop包放在/usr/local目录下并解压

配置环境变量
vi /etc/profile
export HADOOP_HOME=/usr/local/hadoop-3.2.0

9、配置hadoop文件
cd /usr/local/hadoop-2.7.3
在master节点上创建以下文件夹
mkdir hdfs
mkdir hdfs/tmp
mkdir hdfs/name
mkdir hdfs/data
接下来配置/usr/hadoop-2.6.5/etc//hadoop/目录下的七个文件
hadoop-env.sh yarn-env.sh slaves core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml
cd /usr/local/hadoop-2.7.3/etc/hadoop/
1、配置hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_191

2、配置yarn-env.sh
JAVA_HOME=/usr/local/jdk1.8.0_191
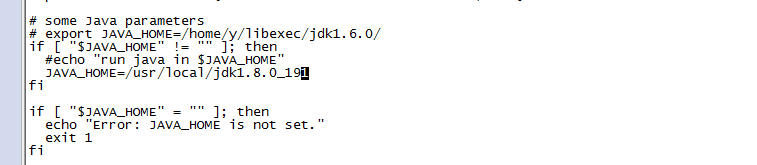
3、配置slaves文件,删除localhost
把原本的localhost删掉,加上salve1,slave2
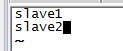
4、配置core-site.xml
在
hadoop.tmp.dir
file:/usr/local/hadoop-2.7.3/hdfs/tmp
A base for other temporary directories.
io.file.buffer.size
131072
fs.defaultFS
hdfs://master:9000
5、配置hdfs-site.xml
在
dfs.replication
2
dfs.namenode.name.dir
file:/usr/local/hadoop-2.7.3/hdfs/name
true
dfs.datanode.data.dir
file:/usr/local/hadoop-2.7.3/hdfs/data
true
dfs.namenode.secondary.http-address
master:9001
dfs.webhdfs.enabled
true
dfs.permissions
false
注意:其中第二个dfs.namenode.name.dir和dfs.datanode.data.dir的value和之前创建的/hdfs/name和/hdfs/data路径一致;因为这里只有2个从主机,所以dfs.replication设置为2)
6、配置 mapred-site.xml,在标签中添加以下代码
mapreduce.framework.name
yarn
7、配置yarn-site.xml
在
yarn.resourcemanager.address
master:18040
yarn.resourcemanager.scheduler.address
master:18030
yarn.resourcemanager.webapp.address
master:18088
yarn.resourcemanager.resource-tracker.address
master:18025
yarn.resourcemanager.admin.address
master:18141
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.auxservices.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
将配置好的hadoop文件复制到其他节点上
scp -r /usr/local/hadoop-2.7.3 root@slave1:/usr/local
scp -r /usr/local/hadoop-2.7.3 root@slave2:/usr/local
10、运行hadoop
格式化Namenode
cd /usr/local/hadoop-2.7.3
./bin/hdfs namenode -format
source /etc/profile
hadoop version

11、启动集群
cd /usr/local/hadoop-2.7.3/sbin
./start-dfs.sh

访问:http://192.168.33.138:50070
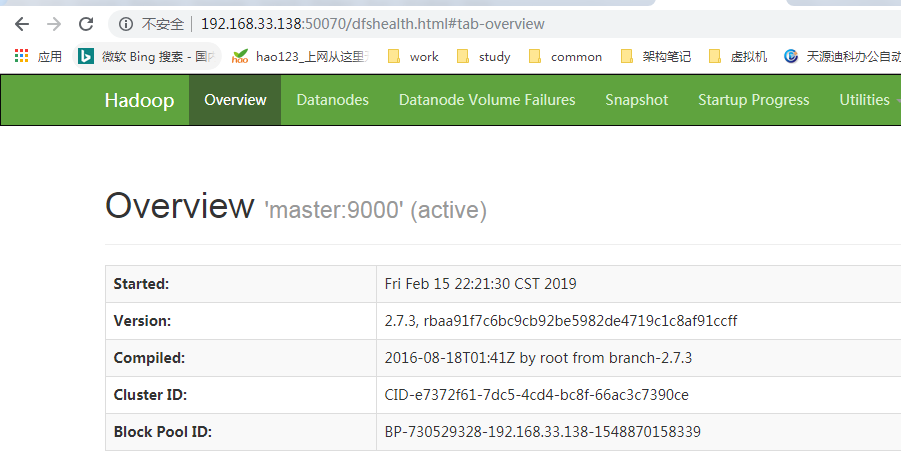
Hadoop相关的shell操作
cd /usr/local/hadoop-2.7.3
bin/hadoop fs -ls /input
bin/hadoop fs -put /home/hadoop/file/file*.txt /input/
bin/hadoop fs -ls /input

常用的shell命令:https://blog.csdn.net/l1394049664/article/details/82152548






























:动手搭建Spring Boot开发环境")



还没有评论,来说两句吧...