线程的基本状态和创建方式
线程的生命周期及五种基本状态
一.线程的生命周期及五种基本状态
关于Java中线程的生命周期,首先看一下下面这张较为经典的图:
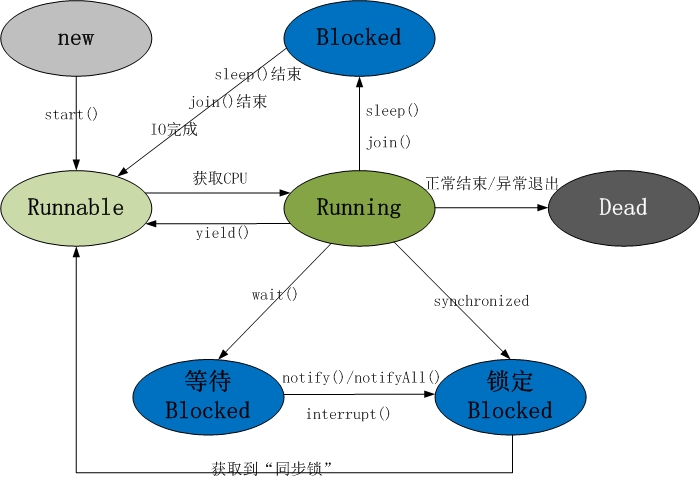
上图中基本上囊括了Java中多线程各重要知识点。掌握了上图中的各知识点,Java中的多线程也就基本上掌握了。主要包括:
Java线程具有五中基本状态
新建状态(New):当线程对象对创建后,即进入了新建状态,如:Thread t = new MyThread();
就绪状态(Runnable):当调用线程对象的start()方法(t.start();),线程即进入就绪状态。处于就绪状态的线程,只是说明此线程已经做好了准备,随时等待CPU调度执行,并不是说执行了t.start()此线程立即就会执行;
运行状态(Running):当CPU开始调度处于就绪状态的线程时,此时线程才得以真正执行,即进入到运行状态。注:就 绪状态是进入到运行状态的唯一入口,也就是说,线程要想进入运行状态执行,首先必须处于就绪状态中;
阻塞状态(Blocked):处于运行状态中的线程由于某种原因,暂时放弃对CPU的使用权,停止执行,此时进入阻塞状态,直到其进入到就绪状态,才 有机会再次被CPU调用以进入到运行状态。根据阻塞产生的原因不同,阻塞状态又可以分为三种:
1.等待阻塞:运行状态中的线程执行wait()方法,使本线程进入到等待阻塞状态;
2.同步阻塞 — 线程在获取synchronized同步锁失败(因为锁被其它线程所占用),它会进入同步阻塞状态;
3.其他阻塞 — 通过调用线程的sleep()或join()或发出了I/O请求时,线程会进入到阻塞状态。当sleep()状态超时、join()等待线程终止或者超时、或者I/O处理完毕时,线程重新转入就绪状态。
死亡状态(Dead):线程执行完了或者因异常退出了run()方法,该线程结束生命周期。
转折就在此处,以上线程的5中基本状态,网上部分博主是这样叙述的,看了源码 才知道,其实线程状态是6种…
扩展:线程的六种状态
Thread类中枚举State中给出了六种线程状态:
public enum State {//新建状态NEW,//就绪状态RUNNABLE,//阻塞状态BLOCKED,//等待状态WAITING,//限时等待状态TIMED_WAITING,//终止状态TERMINATED;}
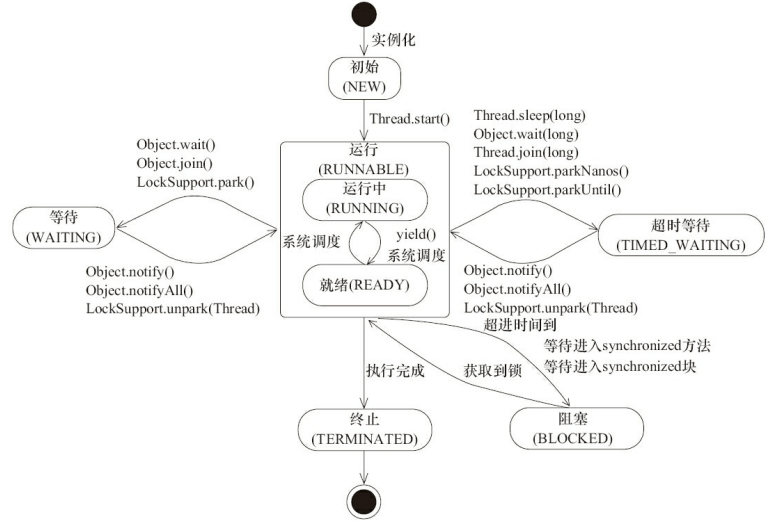
二. Java多线程的就绪、运行和死亡状态
就绪状态转换为运行状态:当此线程得到处理器CPU资源;
运行状态转换为就绪状态:当此线程主动调用yield()方法或在运行过程中失去处理器资源。
运行状态转换为死亡状态:当此线程线程执行体执行完毕或发生了异常。
此处需要特别注意的是:当调用线程的yield()方法时,线程从运行状态转换为就绪状态,但接下来CPU调度就绪状态中的哪个线程具有一定的随机性,因此,可能会出现A线程调用了yield()方法后,接下来CPU仍然调度了A线程的情况。
线程创建有几种方式:
1)继承Thread类创建线程
2)实现Runnable接口创建线程
3)使用Callable和Future创建线程
4)线程池创建
下面让我们分别来看看这三种创建线程的方法。
————————————继承Thread类创建线程——————————-
通过继承Thread类来创建并启动多线程的一般步骤如下
1】定义Thread类的子类,并重写该类的run()方法,该方法的方法体就是线程需要完成的任务,run()方法也称为线程执行体。
2】创建Thread子类的实例,也就是创建了线程对象
3】启动线程,即调用线程的start()方法
代码实例
public class MyThread extends Thread{//继承Thread类public void run(){//重写run方法}}public class Main {public static void main(String[] args){new MyThread().start();//创建并启动线程}}
————————————实现Runnable接口创建线程——————————-
通过实现Runnable接口创建并启动线程一般步骤如下:
1】定义Runnable接口的实现类,一样要重写run()方法,这个run()方法和Thread中的run()方法一样是线程的执行体
2】创建Runnable实现类的实例,并用这个实例作为Thread的target来创建Thread对象,这个Thread对象才是真正的线程对象
3】第三部依然是通过调用线程对象的start()方法来启动线程
代码实例:
public class MyThread2 implements Runnable {//实现Runnable接口public void run(){//重写run方法}}public class Main {public static void main(String[] args){//创建并启动线程MyThread2 myThread=new MyThread2();Thread thread=new Thread(myThread);thread().start();//或者 new Thread(new MyThread2()).start();}}
————————————使用Callable和Future创建线程——————————-
和Runnable接口不一样,Callable接口提供了一个call()方法作为线程执行体,call()方法比run()方法**功能要强大。**
强大之处就是:call()方法可以有返回值**、call()方法可以声明抛出异常**
Java5提供了Future接口来代表Callable接口里call()方法的返回值,并且为Future接口提供了一个实现类FutureTask,这个实现类既实现了Future接口,还实现了Runnable接口,因此可以作为Thread类的target。在Future接口里定义了几个公共方法来控制它关联的Callable任务。
boolean cancel(boolean mayInterruptIfRunning)取消该Future里面关联的Callable任务V get():返回Callable里call()方法的返回值,调用这个方法会导致程序阻塞,必须等到子线程结束后才会得到返回值V get(long timeout,TimeUnit unit)返回Callable里call()方法的返回值,最多阻塞timeout时间,经过指定时间没有返回抛出TimeoutExceptionboolean isDone()若Callable任务完成,返回Trueboolean isCancelled()如果在Callable任务正常完成前被取消,返回True
介绍了相关的概念之后,创建并启动有返回值的线程的步骤如下:
1】创建Callable接口的实现类,并实现call()方法,然后创建该实现类的实例(从java8开始可以直接使用Lambda表达式创建Callable对象)。
2】使用FutureTask类来包装Callable对象,该FutureTask对象封装了Callable对象的call()方法的返回值
3】使用FutureTask对象作为Thread对象的target创建并启动线程(因为FutureTask实现了Runnable接口)
4】调用FutureTask对象的get()方法来获得子线程执行结束后的返回值
代码实例:
public class Main {public static void main(String[] args) throws Exception {// 将Callable包装成FutureTask,FutureTask也是一种RunnableMyCallable callable = new MyCallable();//FutureTask包装callableFutureTask<Integer> futureTask = new FutureTask<>(callable);//作为Thread对象的target创建并启动线程new Thread(futureTask).start();// get方法会阻塞调用的线程Integer sum = futureTask.get();System.out.println(Thread.currentThread().getName() + Thread.currentThread().getId() + "=" + sum);}}class MyCallable implements Callable<Integer> {@Overridepublic Integer call() throws Exception {System.out.println(Thread.currentThread().getName() + "\t" + Thread.currentThread().getId() + "\t" + new Date() + " \tstarting...");int sum = 0;for (int i = 0; i <= 100000; i++) {sum += i;}Thread.sleep(5000);System.out.println(Thread.currentThread().getName() + "\t" + Thread.currentThread().getId() + "\t" + new Date() + " \tover...");return sum;}}
了解下 Callable FutureTask RunnableFuture之间的关系
Callable 也是一种函数式接口
@FunctionalInterfacepublic interface Callable<V> {V call() throws Exception;}
FutureTask
public class FutureTask<V> implements RunnableFuture<V> {// 构造函数public FutureTask(Callable<V> callable);// 取消线程public boolean cancel(boolean mayInterruptIfRunning);// 判断线程public boolean isDone();// 获取线程执行结果public V get() throws InterruptedException, ExecutionException;}
RunnableFuture
public interface RunnableFuture<V> extends Runnable, Future<V> {void run();}
———————————————————三种创建线程方法对比———————————————————
三种方式比较:
Thread: 继承方式, 不建议使用, 因为Java是单继承的,继承了Thread就没办法继承其它类了,不够灵活
Runnable: 实现接口,比Thread类更加灵活,没有单继承的限制
Callable: Thread和Runnable都是重写的run()方法并且没有返回值,Callable是重写的call()方法并且有返回值并可以借助FutureTask类来判断线程是否已经执行完毕或者取消线程执行
当线程不需要返回值时使用Runnable,需要返回值时就使用Callable,一般情况下不直接把线程体代码放到Thread类中,一般通过Thread类来启动线程
Thread类是实现Runnable,Callable封装成FutureTask,FutureTask实现RunnableFuture,RunnableFuture继承Runnable,所以Callable也算是一种Runnable,所以三种实现方式本质上都是Runnable实现
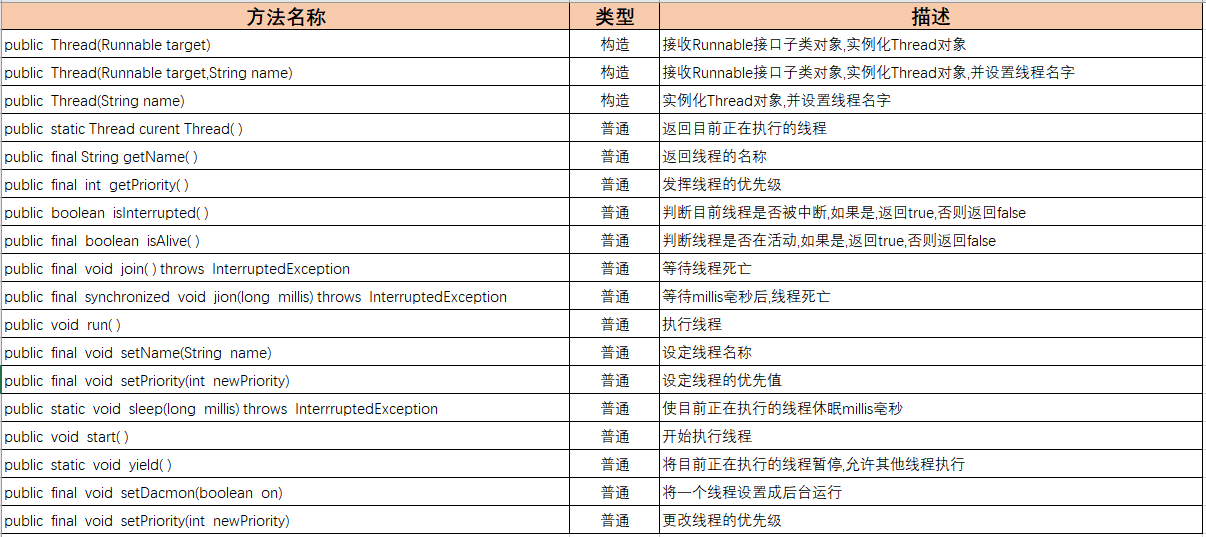
线程的各种方法:

如何实现线程同步?
当多个线程访问同一个数据时,容易出现线程安全问题,需要某种方式来确保资源在某一时刻只被一个线程使用。需要让线程同步,保证数据安全
线程同步的实现方案:同步代码块和同步方法,均需要使用synchronized关键字
线程同步的好处:解决了线程安全问题
线程同步的缺点:性能下降,可能会带来死锁
下面是synchronized对方法和代码块的使用及都锁住什么东西
Class A {public synchronized methodA() {//对当前对象加锁}public methodB() {synchronized(this){}//对当前对象加锁,与methodA用法相同}public static synchronized methodC() {}//对类加锁,即对所有此类的对象加锁public methodD(){synchronized(A.class){}//对类加锁,即对所有此类的对象加锁}}synchronize用法关键是搞清楚对谁加锁,methodA,和methodB都是对当前对象加锁,即如果有两个线程同时访问同一个对象的methoA和methodB则会发生竞争,必须等待其中一个执行完成后另一个才会执行。如果两个线程访问的是不同对象的methodA和methodB则不会竞争。
methodC和methodD是对类的class对象加锁,methodC和methodD的加锁对象一样,效果也一样。如果两个线程同时访问同一个对象的methodC和methodD是会发生竞争的,两个线程同时访问不同对象的methodC和methodD是也是会发生竞争的,如果两个线程同时访问methoA/B 和methodC/D则不会发生竞争,因为锁对象不同。
wait() 与notify()/notifyAll()使用:
这三个方法都是Object的方法,并不是线程的方法!
wait() : 释放占有的对象锁,线程进入等待,释放cpu,而其他正在等待的线程即可抢占此锁,获得锁的线程即可运行程序。而sleep()不同的是,线程调用此方法后,会休眠一段时间,休眠期间,会暂时释放cpu,但并不释放对象锁。也就是说,在休眠期间,其他线程依然无法进入此代码内部。休眠结束,线程重新获得cpu,执行代码。wait()和sleep()最大的不同在于wait()会释放对象锁,而sleep()不会!
notify() : 该方法会唤醒因为调用对象的wait()而等待的线程,其实就是对对象锁的唤醒,从而使得wait()的线程可以有机会获取对象锁。调用notify()后,并不会立即释放锁,
而是继续执行当前代码,直到synchronized中的代码全部执行完毕,才会释放对象锁。
JVM则会在等待的线程中调度一个线程去获得对象锁,执行代码。需要注意的是,wait()和notify()必须在synchronized代码块中调用。
notifyAll():则是唤醒所有等待的线程。
为了说明这一点,举例如下:
两个线程依次打印”A””B”,总共打印10次。
线程A:public class Produce implements Runnable {@Overridepublic void run() {// TODO Auto-generated method stubint count = 10;while(count > 0) {synchronized (Test. obj) {//System.out.print("count = " + count);System. out.print( "A");count --;Test. obj.notify();try {Test. obj.wait();} catch (InterruptedException e) {// TODO Auto-generated catch blocke.printStackTrace();}}}}}线程B:public class Consumer implements Runnable {@Overridepublic synchronized void run() {// TODO Auto-generated method stubint count = 10;while(count > 0) {synchronized (Test. obj) {System. out.print( "B");count --;Test. obj.notify(); // 主动释放对象锁try {Test. obj.wait();} catch (InterruptedException e) {// TODO Auto-generated catch blocke.printStackTrace();}}}}}测试类如下:public class Test {public static final Object obj = new Object();public static void main(String[] args) {new Thread( new Produce()).start();new Thread( new Consumer()).start();}}
这里使用static obj作为锁的对象,当线程Produce启动时(假如Produce首先获得锁,则Consumer会等待),打印“A”后,会先主动释放锁,然后阻塞自己。Consumer获得对象锁,打印“B”,然后释放锁,阻塞自己,那么Produce又会获得锁,然后…一直循环下去,直到count = 0.这样,使用Synchronized和wait()以及notify()就可以达到线程同步的目的。
除了wait()和notify()协作完成线程同步之外,使用Lock也可以完成同样的目的。
ReentrantLock:
ReentrantLock 与synchronized有相同的并发性和内存语义,还包含了中断锁等候和定时锁等候,意味着线程A如果先获得了对象obj的锁,那么线程B可以在等待指定时间内依然无法获取锁,那么就会自动放弃该锁。
但是由于synchronized是在JVM层面实现的,因此系统可以监控锁的释放与否,而ReentrantLock使用代码实现的,系统无法自动释放锁,需要在代码中finally子句中显式释放锁lock.unlock();
这样的例子,使用lock 如何实现呢?
public class Producer implements Runnable{private Lock lock;public Producer(Lock lock) {this. lock = lock;}@Overridepublic void run() {// TODO Auto-generated method stubint count = 10;while (count > 0) {try {lock.lock();count --;System. out.print( "A");} finally {lock.unlock();try {Thread. sleep(90L);} catch (InterruptedException e) {// TODO Auto-generated catch blocke.printStackTrace();}}}}}public class Consumer implements Runnable {private Lock lock;public Consumer(Lock lock) {this. lock = lock;}@Overridepublic void run() {// TODO Auto-generated method stubint count = 10;while( count > 0 ) {try {lock.lock();count --;System. out.print( "B");} finally {lock.unlock(); //主动释放锁try {Thread. sleep(91L);} catch (InterruptedException e) {// TODO Auto-generated catch blocke.printStackTrace();}}}}}调用代码:public class Test {public static void main(String[] args) {Lock lock = new ReentrantLock();Consumer consumer = new Consumer(lock);Producer producer = new Producer(lock);new Thread(consumer).start();new Thread( producer).start();}}
使用建议:
在并发量比较小的情况下,使用synchronized是个不错的选择,但是在并发量比较高的情况下,其性能下降很严重,此时ReentrantLock是个不错的方案。
线程中join方法的使用
join方法有三个重载版本:
join()
join(long millis) //参数为毫秒
join(long millis,int nanoseconds) //第一参数为毫秒,第二个参数为纳秒
假如在main线程中,调用thread.join方法,则main方法会等待thread线程执行完毕或者等待一定的时间。如果调用的是无参join方法,则等待thread执行完毕,如果调用的是指定了时间参数的join方法,则等待一定的事件。
看下面一个例子:
public class Test {public static void main(String[] args) throws IOException {System.out.println("进入线程"+Thread.currentThread().getName());Test test = new Test();MyThread thread1 = test.new MyThread();thread1.start();try {System.out.println("线程"+Thread.currentThread().getName()+"等待");thread1.join();System.out.println("线程"+Thread.currentThread().getName()+"继续执行");} catch (InterruptedException e) {// TODO Auto-generated catch blocke.printStackTrace();}}class MyThread extends Thread{@Overridepublic void run() {System.out.println("进入线程"+Thread.currentThread().getName());try {Thread.currentThread().sleep(5000);} catch (InterruptedException e) {// TODO: handle exception}System.out.println("线程"+Thread.currentThread().getName()+"执行完毕");}}}
复制代码
输出结果: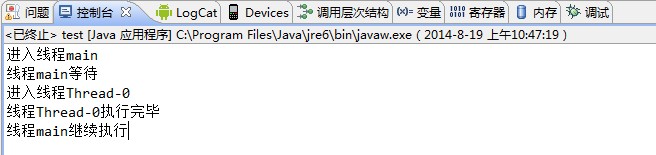
可以看出,当调用thread1.join()方法后,main线程会进入等待,然后等待thread1执行完之后再继续执行。
实际上调用join方法是调用了Object的wait方法,这个可以通过查看源码得知:
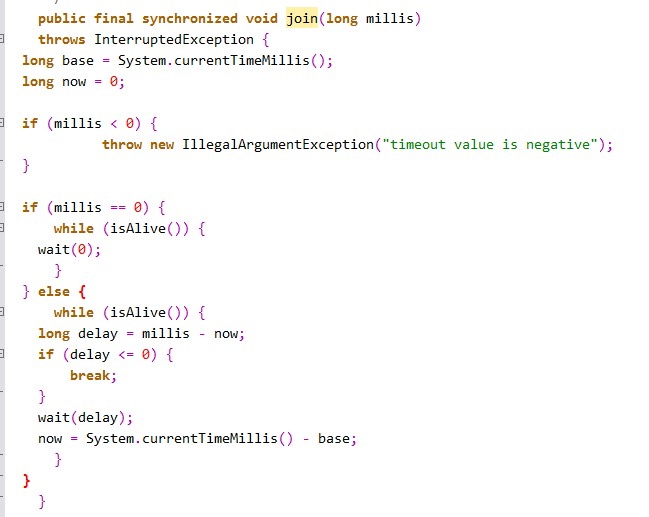
wait方法会让线程进入阻塞状态,并且会释放线程占有的锁,并交出CPU执行权限。
由于wait方法会让线程释放对象锁,所以join方法同样会让线程释放对一个对象持有的锁
简单的面试题:
1、为什么wait(),notify(),notifyAll()等方法都定义在Object类中???
因为这些方法的调用是依赖于锁对象的,而同步代码块的锁对象是任意锁。
而Object代码任意的对象,所以,定义在这里面。
2、如何避免死锁???
Java多线程中的死锁
死锁是指两个或两个以上的进程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。这是一个严重的问题,因为死锁会让你的程序挂起无法完成任务,死锁的发生必须满足以下四个条件:

死锁发生的四个条件
避免死锁最简单的方法就是阻止循环等待条件,将系统中所有的资源设置标志位、排序,规定所有的进程申请资源必须以一定的顺序(升序或降序)做操作来避免死锁
3、ThreadLocal有什么用
简单说ThreadLocal就是一种以空间换时间的做法,在每个Thread里面维护了一个以开地址法实现的ThreadLocal.ThreadLocalMap,把数据进行隔离,数据不共享,自然就没有线程安全方面的问题了
4、为什么wait()方法和notify()/notifyAll()方法要在同步块中被调用
这是JDK强制的,wait()方法和notify()/notifyAll()方法在调用前都必须先获得对象的锁
5、wait()方法和notify()/notifyAll()方法在放弃对象监视器时有什么区别
wait()方法和notify()/notifyAll()方法在放弃对象监视器的时候的区别在于:wait()方法立即释放对象监视器,notify()/notifyAll()方法则会等待线程剩余代码执行完毕才会放弃对象监视器。
6、怎么唤醒一个阻塞的线程
如果线程是因为调用了wait()、sleep()或者join()方法而导致的阻塞,可以中断线程,并且通过抛出InterruptedException来唤醒它;如果线程遇到了IO阻塞,无能为力,因为IO是操作系统实现的,Java代码并没有办法直接接触到操作系统
7、什么是多线程的上下文切换
多线程的上下文切换是指CPU控制权由一个已经正在运行的线程切换到另外一个就绪并等待获取CPU执行权的线程的过程。
8、进程线程的概念及区别
进程:是具有一定独立功能的程序关于某个数据集合上的一次进行活动,是系统进行资源分配和调度的一个独立单位。
线程:是进程的一个实体,是cpu调度和分派的基本单位,
区别:
1、一个线程只能属于一个进程,而一个进程可以拥有多个线程。
2、线程是进程工作的最新单位。
3、一个进程会分配一个地址空间,进程与进程之间不共享地址空间。即不共享内存。
4、同一个进行下的不同的多个线程,共享父进程的地址空间。
5、线程在执行过程中,需要协助同步。不同进程的线程间要利用消息通信的办法实现同步。
6、线程作为调度和分配的基本单位,进程作为拥有资源的基本单位。






























之HelloWorld(IDEA版)")



还没有评论,来说两句吧...