【Tensorflow】北京大学tensorflow学习笔记
AI_TensorflowNotebook
北京大学公开课学习笔记
课程链接:https://www.icourse163.org/course/PKU-1002536002
课程github主页:链接
推荐课程中的助教笔记,内容更加全面。笔记链接 提取码: jhk5
本文相关代码:github个人主页
1 AI概述与环境搭建
1.1 人工智能概述
- 人工智能的概念、兴衰史、学科带头人、常见消费产品。
- 机器学习概念、应用领域(CV、NLP)、三要素(数据、算法、算力)
- 深度学习概念、计算机实现。
- 关系:人工智能》机器学习》深度学习
1.2 环境配置
课程代码基于python2.7,tensorflow版本:1.3.0,系统:windows10,其他环境可以自行百度或参考课程视频安装。
个人使用64位虚拟机:ubuntu18.04,安装过程遇到的一些问题:
- 安装pip:
sudu apt install python-pip - pip 安装完成后去 tflearn.org 左侧Installation 找到对应python版本的TensorFlow下载指令。
如ubuntu/linux 64-bit,CPU only,python2.7对应:$ export TF_BINARY_URL=https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-1.1.0-cp27-none-linux_x86_64.whl - 借助输入下面的对应python2 的安装指令:
$ sudo pip install $TF_BINARY_URL - 安装后命令行进入python,输入:
import tensorflow as tf不报错说明安装成功,输入:print tf.__version__查看版本。
1.3 安装必要包
使用清华镜像,安装其他需要的python包,如pandas,命令行输入:pip install -i https://pypi.tuna.tsinghua.edu.cn/simple/ pandas
安装vim:sudo apt-get install vim
替换apt软件源为阿里云源:https://blog.csdn.net/zhangjiahao14/article/details/80554616
这里ubuntu的版本影响源地址,所以之前一直替换不成功。
python2.7比较老,很多包和函数都因为更新会出现各种各样的问题,遇到问题多找找博客论坛。
2 编程语言基础
2.1 常用基础命令
- pwd:当前路径
- ls:显示文件
- cd… 返回上一级 …/…上两级 ~ 返回home目录
- mkdir:创建文件夹
- vim A.py 用vim打开一个py文件
- vim全选,全部复制,全部删除,先按esc,分别对应ggVG、ggyG、dG
- :q 强制退出vim :wq保存更改退出 :q! 不保存退出 如果文件无法编辑保存退出,打开文件的时候使用sudo vim 文件命名
其他vim指令参考:点此连接
2.2 ubuntu指令
- 更新源:sudo apt-get update
- 更新已安装的软件:sudo apt-get upgrade
- 删除包:sudo apt-get remove package
- 打开命令终端:Ctrl+Alt+T
- 回到桌面:win+D
- 切换输入法:win+空格
- 其他快捷键在:设置->设备->键盘 处可看。
2.3 python基础语法
学习本课程的都是有基础的,不再赘述。
3 Tensorflow框架介绍
3.1 张量、图、会话
基于tensorflow的神经网络就是用张量(Tensor)表示数据,用计算图(Graph)搭建网络,用会话(Sess)进行运算,优化权重参数获得模型。
1、张量(Tensor):多维数组的特殊表示形式
#coding:utf-8import tensorflow as tfa=tf.constant([1.0,2.0]) #张量b=tf.constant([3.0,4.0])result=a+bprint result
输出:Tensor(“add:0”, shape=(2,), dtype=float32)
2、计算图(Graph):搭建神经网络的计算结构(乘加),不进行计算。
#coding:utf-8import tensorflow as tfx = tf.constant([[1.0, 2.0]])w = tf.constant([[3.0], [4.0]])y=tf.matmul(x,w)print y
输出:
Tensor(“MatMul:0”, shape=(1, 1), dtype=float32)
3、会话(Session):会话为执行计算结果
with tf.Session() as sess:print sess.run(y)
[[11.]]
4、常用参数tf.Variable()
tf.random_normal() #生成正态分布随机数tf.truncated_normal() #去大偏离点的正态tf.random_uniform() #均匀分布随机tf.zeros() #全0tf.ones() #全1tf.fill() #全部为某一个给定值tf.constant([]) #给指定值,可不同
涉及到随机数时给定seed即可生成相同随机数。
3.2 前向传播
将数据输入,搭建好的Graph,Session结构,经卷积、池化、非线性激活等操作输出运算结果。
#coding:utf-8import tensorflow as tfx = tf.constant([[0.7, 0.5]]) #输入w1= tf.Variable(tf.random_normal([2, 5], stddev=1, seed=1)) #两层参数w 五个节点w2= tf.Variable(tf.random_normal([5, 1], stddev=1, seed=1))a = tf.matmul(x, w1) #前向传播计算y = tf.matmul(a, w2)with tf.Session() as sess:init_op = tf.global_variables_initializer() #汇总变量sess.run(init_op) #变量初始化print"y in test is:\n",sess.run(y) #计算接点输出
使用:tf.placeholder(tf.float32, shape=(A, B))对输入数据占位,选择喂入一组(A=1)或多组(A=None),以及选择数据属性(B=)。
喂1组,每组2列:
x = tf.placeholder(tf.float32, shape=(1, 2))sess.run(y, feed_dict={x: [[0.6,0.4]]})
喂2组,每组3列:
x = tf.placeholder(tf.float32, shape=(None, 3))sess.run(y, feed_dict={x: [[0.6,0.4,0.2],[0.3,0.5,0.8]]})
3.3 反向传播
指定学习率、损失函数等参数不断喂入数据进行参数w权重偏置b的优化,达到最小损失,参数最优。
1、损失函数(loss):预测值yu和已知答案y的差值,优化的目标,使它最小。
常用方法:
均方误差(MSE): 预测yu和标准y差的平方和再求平均
loss_MSE = tf.reduce_mean(tf.square(y-yu))
交叉熵(CE):概率分布距离,只越大预测、实际差距越大。
ce = -tf.reduce_mean(yu*tf.log(tf.clip_by_value(yu,1e-12,1.0))) #限定yu作为log指数不为0
自定义:其他损失函数。
2、 学习率(learning_rate)
参数更新的幅度,一般预设0.001
3、优化器选择:
train_step = tf.train.GradientDescentOptimizer(0.001).minimize(loss_MSE) #梯度下降train_step = tf.train.MomentumOptimizer(0.001,0.9).minimize(loss_MSE)train_step = tf.train.AdamOptimizer(0.001).minimize(loss_MSE)
常见优化器优缺点比较:参考博客
训练时可以加入 time 模块计算时间。
4、激活函数:
增加模型的表达力,提高非线性分类的能力。
- relu函数:tf.nn.relu()
- sigmoid函数:tf.nn.sigmoid()
- tanh函数:tf.nn.tanh()
常用激活函数理解和总结:StevenSun2014的博客
3.4 神经网络复杂度
与神经网络层数和参数个数有关。
神经网络层数为隐含层个数+1,没经过运算的不算(输入层不算,输出算)
参数:总的权重参数w个数 + 总偏置项b个数。权重参数w个数看每层前后节点乘积和,总偏置b个数看每两层后靠后一层的节点数量。
4 神经网络优化
4.0先导环节
tensorflow里的一些常用函数
tf.get_collection("")#从集合中取出全部变量形成列表tf.add_n([])#列表内对应元素相加tf.cast(x,dtype)#将x转化为dtype类型f.argmax(x,axis=)#返回最大值索引号with tf.Graph().as_default as g:#将()其中的节点用在计算图 g 中,一般用于复现定义好的网络
4.1 损失函数
MSE、CE、自定义三种,再tensorflow中的使用不再赘述,参考上节。
在交叉熵损失函数使用时如果使用softmax()转化为分类概率分布:
CE = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=,labels=tf.argmax(yu,1)) #返回每行在列维度的最大值索引CEM = tf.reduce_mean(CE)
4.2 学习率
可以设置静态学习率为定值,不宜过小过大,过小损失函数收敛很慢,较大容易振荡不收敛。
指数衰减学习率:根据训练轮数动态更新学习率。
lr = lr_base * lr_decay^(global_step/lr_step)
- lr_base:学习率初始值,学习率基数
- lr_decay:学习率衰减率,属于(0,1)
- global_step:运行了多少轮batch_size
- lr_step:多少轮更新(减低)一次学习率,取(总样本数/batch_size)
在tensorflow中:
global_step = tf.Variable(0,trainable = False) #轮数不可训练lr = tf.train.exponential_decay(lr_base,global_step,lr_step,lr_decay,staircase = Ture)#staircase = Ture 时,比值取整,梯形衰减,False平滑衰减
指数衰减的学习率,在迭代初期得到较高的下降速度,可以在较小的训练轮数下取得更有收敛度。
注意:global_step的值是使学习率更新的关键:
train_step = tf.train.GradientDescentOptimizer(lr).minimize(loss, global_step=global_step)
如果不在训练目标**minimize(loss, global_step=global_step)**里加上global_step=global_step的话这个数值不会变化,学习率也就不会变化。
4.3 滑动平均
记录网络中每个参数一段时间内过往值的平均值,增加模型的泛化能力。针对所有参数w和b
滑动均值初值 = 参数初值
滑动均值 = 衰减率 * 上一滑动均值 + (1-衰减率)* 更新的参数值(w或b)
衰减率 = Min{ Moving_Average_Decay,(1+global_step)/(10+global_step)}
实际使用:
ema = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY,global_step) #global_step当前轮数ema_op = ema.apply(tf.trainable_variables()) #对所有待优化的参数求滑动平均with tf.contral_dependencies([train_step,ema_op]): #只优化这两个参数集train_op = tf.no_np(name='train') #执行完上面两之后什么也不做
ema.average(w1)可以在运行过程调用查看参数情况
4.4 正则化
在模型损失函数中给每个参数加上权重,抑制模型训练数据噪声。
通常只对权重参数w使用,缓解过拟合现象。
loss_all = loss(CE,MSE等) + REGULARIZER * loss(w)#loss_all表示模型总的损失函数,REGULARIZER表示超参数权重,决定w在总loss中的比例。loss(w)是进行正则化的参数。
常用的两种正则化方法:
L1正则: L1_loss=∑|w|
loss(w) = tf.contrib.layers.l1_regularizer(REGUIARIZER)(w)
L2正则:L2_loss=∑|w^2|
loss(w) = tf.contrib.layers.l2_regularizer(REGUIARIZER)(w)
tensorflow中使用方法:
loss_ce = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(yu, 1))loss_cem = tf.reduce_mean(loss_ce)loss_all = loss_cem + tf.add_n(tf.get_collection('losses')) #这里的losses就是经过正则化的,
其他正则化方法可参考博客:Maples丶丶的博客
示例:初始分布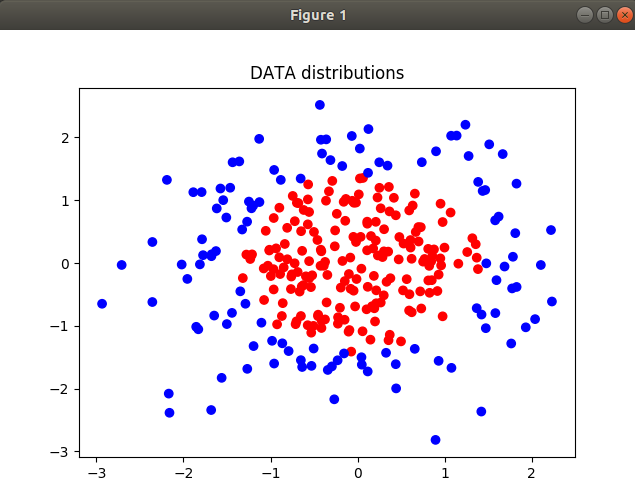
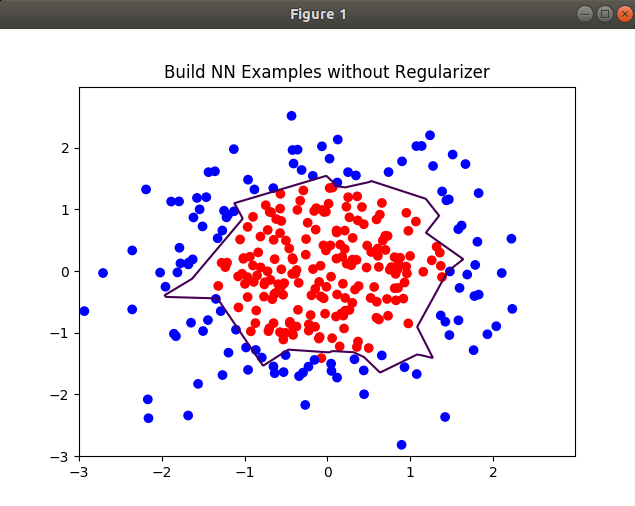
无正则化训练:60000次,学习率0.001.
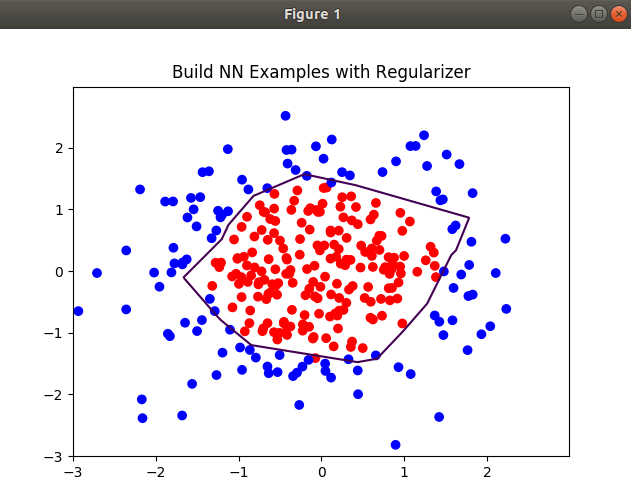
有正则化训练:60000次,学习率0.001.
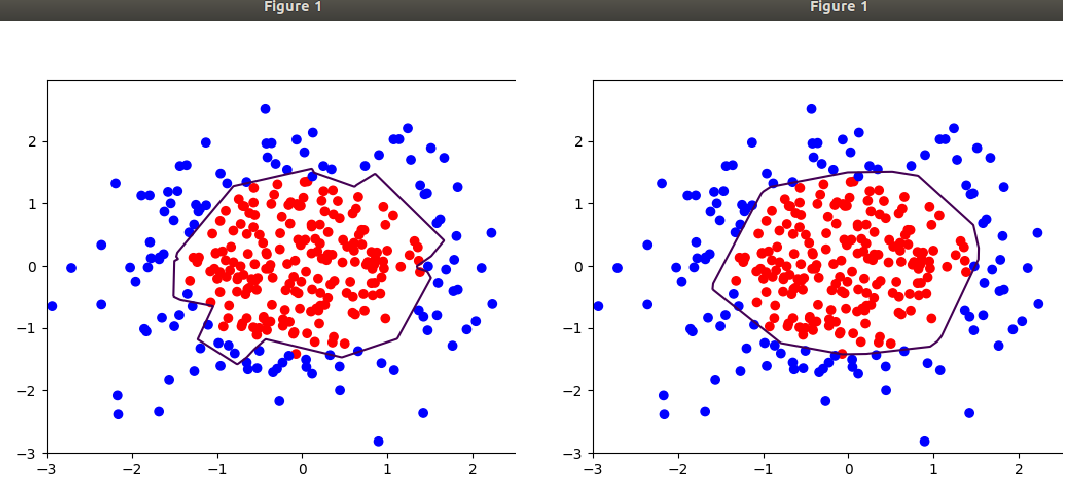
可以调整其他参数查看效果:如训练轮数为120000次时:
4.5 神经网络搭建样例
1、前向传播forward.py
def forward(x,regularizer): #声明权重、参数,和预测输出的计算方法w =b =y =return y #输出结果def get_weight(shape,regularizer): #shape是中间权重矩阵形状w = tf.Variable() #一般用随机函数声明if regularizer != None: tf.add_to_collection('losses', tf.contrib.layers.l2_regularizer(regularizer)(w))#声明如果有正则化超参数,则对w使用正则化return wdef get_bias(shape): #偏置形状和参数b = tf.Variable()return b
2、反向传播backward.py
def backward():x = tf.placeholder()y = tf.placeholder() #标准的x和类标签y 数据占位yu = forward.forward(x,REGULARIZER) #调用forward.py里的forward函数计算预测输出global_step = tf.Variable(0,trainable=False)loss = 可视任务情况选择加入优化方法
①正则化的优化方法:
内容参考上一节:
最终loss = 基本损失loss(CE等) + 正则化损失tf.add_n(tf.get_collection('losses'))
②指数衰减学习率优化:
调用函数参考上节。
最终的训练目标:train_step = tf.train.GradientDesentOptimizer(lr).minimize(loss,global_step = global_step)
优化器除梯度下降也可选其他MomentumOptimizer、AdamOptimizer等。
③滑动平均优化:
ema = tf.train.ExponentialMovingAverage(M_A_DECAY,global_step)ema_op = ema.apply(tf.trainable_variables()) #应用到所有参数求滑动平均with tf.contral_dependencies([train_step,ema_op]): #只执行这两个部分train_op = tf.no_np(name='train') #之后无操作
④实例化声明:用以保存模型参数:
saver = tf.train.Saver()
⑤所有变量环节初始化
with tf.Session() as sess:init_op = tf.global_variables_initializer()sess.run(init_op) #生成会话, 初始化变量for i in range(STEPS):sess.run(train_step,feed_dict={x: ,y_: }) #喂数if i % 轮数 ==0:print #每多少轮显示轮数或者loss损失值saver.save() #保存模型及参数
⑥判断backward是否为主文件:
if __name__ = '__main__':backward()
3 测试文件test.py
def test():with tf.Graph().as_default() as g: #复现计算图x = tf.placeholder(tf.float32, [None, ])y = tf.placeholder(tf.float32, [None, ]) #输入x y 占位yu = forward.forward(x, None) #前向传播计算输出yu
实例化带滑动平均的saver对象,所有参数在会话中被加载时会被赋值为各自的滑动平均值。就是调用以前经过滑动平均的参数。
ema = tf.train.ExponentialMovingAverage(mnist_backward.MOVING_AVERAGE_DECAY)ema_restore = ema.variables_to_restore()saver = tf.train.Saver(ema_restore)
计算准确率
correct_prediction = tf.equal(tf.argmax(yu, 1), tf.argmax(y, 1))#yu是神经网络喂入的batch_size组数据后计算的结果,是batchsiZe组*10(单个标签所含10分类)的二维数组。#1表示argmax函数选取最大值的操作仅在第一个维度,就是返回每行里的最大值对应索引。accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))#cast()把equal()函数获取的布尔值转化为实数,再用tf.reduce_mean()求平均,获得准确率while True:with tf.Session() as sess:ckpt = tf.train.get_checkpoint_state(mnist_backward.MODEL_SAVE_PATH)#加载模型,赋参数滑动平均值if ckpt and ckpt.model_checkpoint_path: #确认模型路径和文件都存在saver.restore(sess, ckpt.model_checkpoint_path) #恢复到当前会话global_step = ckpt.model_checkpoint_path.split('/')[-1].split('-')[-1]accuracy_score = sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels})print("经过 %s 训练轮数, 准确率为: %g" % (global_step, accuracy_score))else:print('没有对应模型')returntime.sleep(T) #测试进行的快,训练保存模型进行的慢,不延迟可能多次调用的是同一个模型的参数,若不是一起运行则无影响
5 全连接网络基础
5.1 MNIST数据集
mnist为黑底白字的手写数字数据集,每行图片大小为28*28像素,附带每张图片的标签信息。纯黑像素为 0,纯白色像素为1.
数据集分为train, validation 和 test 三个数据集。训练集和验证集一般用来训练。
- train:一般用来训练调整网络权重参数,计算训练集准确率。
- validation:一般只用来计算准确率,达到阈值就退出训练。**不使用该数据集调整参数权重。**如果训练验证过程中训练集的准确率仍然不断上升,但是验证集准确率不变或者降低了,就过拟合了,停止训练。
- test:用来测试网络的实际预测能力
0加载数据集到指定路径:
from tensorflow.examples.tutorials.mnist import input_datamnist = input_data.read_data_sets("./python/pymnist/data/", one_hot=True)
1查看各个数据集样本数量:
print "train sets size:\n",mnist.train.num_examplesprint "validation sets size:\n",mnist.validation.num_examplesprint "test sets size:\n",mnist.test.num_examples
2 查看制动数据集、指定图片的标签和像素值:
#训练集中第6张图片的标签和像素值mnist.train.labels[6]>>>array([0., 1., 0., 0., 0., 0., 0., 0., 0., 0.])#该数字为2mnist.train.images[6]
3 喂入网络数据
xs,ys = mnist.train.next_batch(batchsize)
参数 batchsize,表示随机从训
练集中抽取 batchsize 个样本输入神经网络,并将样本的像素值和标签分别赋
给 xs 和 ys。
5.2 模型的保存、复用和断点续训
保存:
saver = tf.train.Saver()#声明实例对象with tf.Session() as sess:...for i in range(STEPS):xs, ys = mnist.train.next_batch(BATCH_SIZE)if i % 轮数 == 0:saver.save(sess, os.path.join(MODEL_SAVE_PATH, MODEL_NAME), global_step=global_step)#保存模型到当前会话,标注保存时的训练轮数
模型加载:
with tf.Session() as sess:ckpt = tf.train.get_checkpoint_state( 存储路径) )if ckpt and ckpt.model_checkpoint_path:saver.restore(sess, ckpt.model_checkpoint_path)#如果ckpt模型和保存路径都存在,复用
断点续训:一般加在会话sess开始后初始化的后面,可以继续之前意外中断的训练过程。
ckpt = tf.train.get_checkpoint_state(MODEL_SAVE_PATH)if ckpt and ckpt.model_checkpoint_path:saver.restore(sess, ckpt.model_checkpoint_path)
5.3 全连接神经网络识别手写体数据
对应文件在文件夹chapter5_fullyConect中。
包含几个部分:
- data文件夹:存放下载的mnist数据文件。
- model文件夹:存放训练完成保存的模型及各个参数,默认只保存最近的5个。
- pic文件夹:为待识别的手写数字图片。
- mnist_backward.py:反向传播过程,及常见优化方法。
- mnist_forward.py:定义输入参数、网络结构。
- mnist_test.py:复用模型进行测试,查看准确率。
- mnist_app.py:应用训练好的模型实现手写数字预测。
使用时注意各文件存放路径,避免使用时调用路径错误,进行图片预测测试时待判别图片路径输入要完整。
反向传播:
注意训练过程可以按 ctrl+Z中断训练,模型下次训练可以继续,若要重新开始先删除model文件夹里的文件。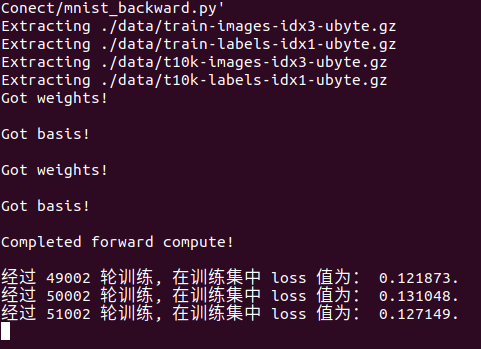
测试: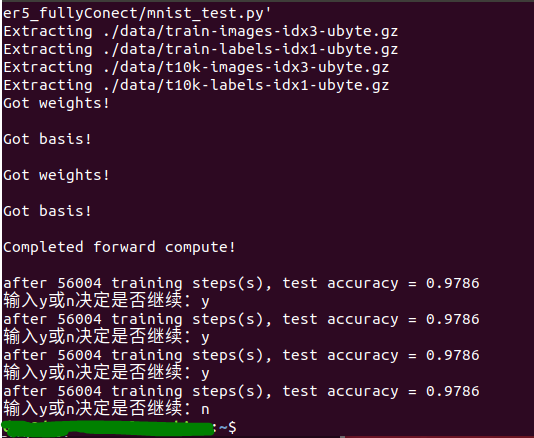
应用预测: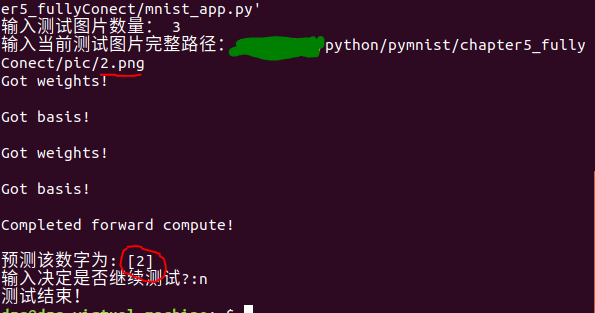
6 全连接神经网络实战
6.1 与第五章内容重合,不赘述
6.2 以mnist为例自制数据集
6.2.1 什么是tfrecords文件
1、tfrecords文件:
一种二进制文件,可先将图片和标签制作成该格式的文件。使用这种格式进行数据读取,会提高内存利用率。
2、 tf.train.Example():
用来存储训练数据。tf.train.Example中包含了一个从属性名称及取值的字典,其中属性名称为一个字符串,属性的取值可以为字符串(BytesList ),实数列表(FloatList )或整数列表(Int64List )。
训练数据的特征用 键值对 的形式表示。
如:
'img_raw':值'label':值
值取:Byteslist/FloatList/Int64List
3、 SerializeToString( ) :
把数据序列化成字符串存储。
6.2.2 生成 tfrecords文件
writer = tf.python_io.TFRecordWriter('train.tfrecords') #新建writer文件..#中间读待制作数据文件过程.for content in contents: #对每个数据处理..#取数据路径、转为二进制,打标签.example = tf.train.Example(features=tf.train.Features(feature={'img_raw': tf.train.Feature(bytes_list=tf.train.BytesList(value=[img_raw])),'label': tf.train.Feature(int64_list=tf.train.Int64List(value=labels))})) #标准封装格式 每张图片和标签封装到example中writer.write(example.SerializeToString()) #序列化存储writer.close() #完成
6.2.3 解析 tfrecords文件
filename_queue = tf.train.string_input_producer([tfRecord_path], shuffle=True) #解析队列reader = tf.TFRecordReader() #新建reader文件_, serialized_example = reader.read(filename_queue) #读出来的每一个样本保存features = tf.parse_single_example(serialized_example,features={'label': tf.FixedLenFeature([10], tf.int64),'img_raw': tf.FixedLenFeature([], tf.string)}) #解序列化img = tf.decode_raw(features['img_raw'], tf.uint8) #恢复图片... #降维,整形 主要是符合选用网络的输入要求.
6.2.4 获取展示 tfrecords文件
tfrecords_file = '.../train.tfrecords'image_batch, label_batch = read_tfrecord(tfrecords_file)img_batch, label_batch = tf.train.shuffle_batch([img, label],batch_size= batch_size,num_threads=2,capacity=2000,min_after_dequeue=1500,)#从总样本中顺序取出capacity组数据,每次打乱顺序输出batch_size组,#如果capacity小于min_after_dequeue,会再从总样本中取出数据填满capacity,#结果输出为随即取出的batchsize组图像和标签数据
此章数据集tfrecords文件制作有部分内容参考博客:链接
最后修改测试我没有成功复现:可参考博客young liu
这部分内容数据及源码链接:链接
试了几次数据文件解压都有问题。




























")





还没有评论,来说两句吧...