Hadoop安装(YARN 集群)
前言
在前面的章节中, 我们介绍了Hadoop 安装(单结点). 本章中,我们介绍下Hadoop的集群安装模式.
前置条件
三台VMware虚拟机, 分别为:
- 192.168.31.60
- 192.168.31.61
- 192.168.31.62
其主机名称分别为: sean60/sean61/sean62(配置本机的/etc/hosts与/etc/hostname即可.)
- 三台机器上都已经安装了
JDK 1.7+. - 并且, 配置了60机器到其他两台机器的免密登陆.
- 三台机器间防火墙关闭.
正文
我们选择其中一台机器作为Master节点, 其余作为Slave节点.安装架构图大致如下所示: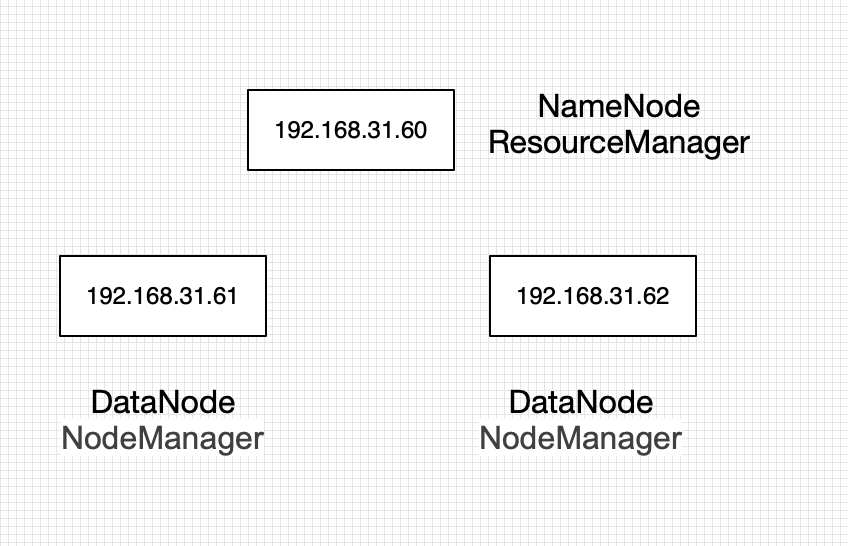
基本配置操作步骤如下所示:
- 分发安装包,设置安装目录解压
下载官方安装包,并将其分别分发到三个节点上,解压. 本人使用的目录为/opt/apps/hadoop/hadoop-2.7.5.(后文中的安装目录代指此处.) 配置环境变量
在三台机器上分别配置如下配置, 随后source /etc/profile命令使其生效.vi /etc/profile
export HADOOP_HOME=/opt/apps/hadoop/hadoop-2.7.5
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/Hadoopexport PATH=$PATH:$HADOOP_HOME/bin
设置
slaves节点
在sean60机器上设置slaves节点.(此设置在使用start-dfs.sh等启动关闭脚本时会用到.)salves
sean61
sean62配置通用配置
三台机器中的通用配置为(配置文件为./etc/hadoop/目录下的文件)vi etc/hadoop/core-site.xml
fs.defaultFS
hdfs://sean60:9000
hadoop.tmp.dir
/usr/local/hadoop-2.7.5/tmp
vi etc/hadoop/hdfs-site.xml
dfs.replication
1
vi etc/hadoop/mapred-site.xml
mapreduce.framework.name
yarn
创建目录并赋予权限
在各节点指定HDFS文件存储的位置(默认是/tmp)
Master节点: namenode
#mkdir -p /usr/local/hadoop-2.7.0/tmp/dfs/name#chmod -R 777 /usr/local/hadoop-2.7.0/tmpvi etc/hadoop/hdfs-site.xml<property><name>dfs.namenode.name.dir</name><value>file:///usr/local/hadoop-2.7.0/tmp/dfs/name</value></property>
Slave节点:datanode
创建目录并赋予权限
#mkdir -p /usr/local/hadoop-2.7.0/tmp/dfs/data#chmod -R 777 /usr/local/hadoop-2.7.0/tmp# vi etc/hadoop/hdfs-site.xml<property><name>dfs.datanode.data.dir</name><value>file:///usr/local/hadoop-2.7.0/tmp/dfs/data</value></property>
- YARN设置
Master节点: resourcemanager
# vi etc/hadoop/yarn-site.xml<configuration><property><name>yarn.resourcemanager.hostname</name><value>test166</value></property></configuration>
Slave节点: nodemanager
# vi etc/hadoop/yarn-site.xml<configuration><property><name>yarn.resourcemanager.hostname</name><value>test166</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property></configuration>
可以使用start-all.sh替代上述两个脚本.
测试
测试 HDFS
hdfs dfs -mkdir /user
hdfs dfs -mkdir /user/Sean
hdfs dfs -put etc/hadoop/ /user/Sean/
hdfs dfs -ls /user/Sean/input
测试YARN
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.5.jar wordcount /user/Sean/input output
Reference
[1]. Hadoop系列之(二):Hadoop集群部署
[2]. Hadoop(二)CentOS7.5搭建Hadoop2.7.6完全分布式集群
[3]. hadoop安装和配置




























——界面美化")




还没有评论,来说两句吧...