机器学习方法之KNN
K最近邻(k-Nearest Neighbor,KNN)分类算法,思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
实例分析
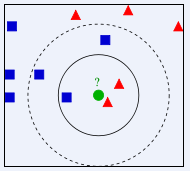
有两类不同的样本数据,分别用蓝色的小正方形和红色的小三角形表示,而图正中间的那个绿色的圆所标示的数据则是待分类的数据。也就是说,现在,我们不知道中间那个绿色的数据是从属于哪一类(蓝色小正方形or红色小三角形),下面,我们就要解决这个问题:给这个绿色的圆分类。
俗话说物以类聚,人以群分,判别一个人是一个什么样品质特征的人,常常可以从他/她身边的朋友入手。我们不是要判别上图中那个绿色的圆是属于哪一类数据么,好说,从它的邻居下手。但一次性看多少个邻居呢?从上图中,你还能看到:
- 若K=3,绿色圆点的最近的3个邻居是2个红色小三角形和1个蓝色小正方形,少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于红色的三角形一类。
- 若K=5,绿色圆点的最近的5个邻居是2个红色三角形和3个蓝色的正方形,还是少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于蓝色的正方形一类。
我们看到,当无法判定当前待分类点是从属于已知分类中的哪一类时,我们可以依据统计学的理论看它所处的位置特征,衡量它周围邻居的权重,而把它归为(或分配)到权重更大的那一类。这就是K近邻算法的核心思想。
KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
时间复杂度
KNN 算法本身简单有效,它是一种 lazy-learning 算法,分类器不需要使用训练集进行训练,训练时间复杂度为0。KNN 分类的计算复杂度和训练集中的文档数目成正比,也就是说,如果训练集中文档总数为 n,那么 KNN 的分类时间复杂度为O(n)。
算法三要素
- K 值的选择会对算法的结果产生重大影响。K值较小意味着只有与输入实例较近的训练实例才会对预测结果起作用,但容易发生过拟合;如果 K 值较大,优点是可以减少学习的估计误差,但缺点是学习的近似误差增大,这时与输入实例较远的训练实例也会对预测起作用,使预测发生错误。
在实际应用中,K 值一般选择一个较小的数值,通常采用交叉验证的方法来选择最优的 K 值。随着训练实例数目趋向于无穷和 K=1 时,误差率不会超过贝叶斯误差率的2倍,如果K也趋向于无穷,则误差率趋向于贝叶斯误差率。 - 分类决策规则往往是多数表决,即由输入实例的 K 个最临近的训练实例中的多数类决定输入实例的类别。
- 距离度量一般采用Lp 距离,当p=2时,即为欧氏距离,在度量之前,应该将每个属性的值规范化,这样有助于防止具有较大初始值域的属性比具有较小初始值域的属性的权重过大。
算法实现
算法步骤
(1)计算已知类别数据集中的点与当前点之间的距离
(2)按照距离递增次序排序
(3)选取与当前点距离最小的K个点
(4)确定前K个点所在类别出现的频率
(5)返回前K个点出现频率最高的类别作为当前点的预测分类
代码实例
iris数据集,包含150条用例,每条用例共5列,前4列为特征数据,最后一列为标签数据。
简单实现
调用sklearn自带的库
from sklearn import neighborsfrom sklearn import datasetsknn = neighbors.KNeighborsClassifier() # 申明对象iris = datasets.load_iris() # 导入数据print(iris)knn.fit(iris.data,iris.target) # 生成KNN模型predicit_label = knn.predict([[0.2,0.3,0.3,0.2]]) # 预测print(predicit_label)
复杂实现
自己编写函数实现
import csvimport randomimport mathimport operator'''导入数据filename数据存储路径radio,按指定比例将数据划分为训练集和测试集'''def loadDateset(filename,radio,trainSet=[],testSet=[]):with open(filename,'rt') as csvfile:lines = csv.reader(csvfile) # 逐行读取数据dataset = list(lines) # 转换为列表存储for x in range(len(dataset)-1): # 循环每行数据,将前4个特征值存入数组for y in range(4):dataset[x][y] = float(dataset[x][y])if random.random()<radio: # 取随机值,小于radio就划分到训练集trainSet.append(dataset[x])else:testSet.append(dataset[x])'''计算2个样例之间的距离(欧氏距离),length表示数据的维度'''def evaluateDistance(instance1,instance2,length):distance = 0for x in range(length): # 循环每一维度,数值相减并对其平方,然后进行累加distance += pow((instance1[x]-instance2[x]),2)return math.sqrt(distance) # 开方求距离'''对于一个实例,找到离他最近的k个实例'''def getNeighbors(trainSet,testInstance,k):distance = []length = len(testInstance)-1 # 每个测试实例的维度for x in range(len(trainSet)-1): # 训练集中每一个实例到测试实例的距离dist = evaluateDistance(testInstance,trainSet[x],length)distance.append((trainSet[x],dist)) # 将每一个训练实例和其对应到测试实例的距离存储到列表distance.sort(key=operator.itemgetter(1)) # operator模块提供的itemgetter函数用于获取距离维度的数据并排序neighbors = [] # 存储离一个实例最近的几个实例for x in range(k): # 取distance中前k个实例存储到neighborsneighbors.append(distance[x][0])return neighbors'''在最近的K个实例中投票,少数服从多数,把要预测的实例归到多数那一类'''def getResponse(neighbors):classvotes = {} # 定义一个字典,存储每一类别的数目for x in range(len(neighbors)):response = neighbors[x][-1]if response in classvotes:classvotes[response] += 1else:classvotes[response] = 1sortedVotes = sorted(classvotes.items(),key=operator.itemgetter(1),reverse=True) # 排序,输出数目最大的类别return sortedVotes[0][0]'''计算测试集的准确率'''def getAccuracy(testSet,predictions):correct = 0for x in range(len(testSet)):if testSet[x][-1] == predictions[x]: # 每行测试用例最后一列的标签与预测标签是否相等correct += 1return (correct/float(len(testSet)))*100.0def main():trainSet = [] # 存储训练集testSet = [] # 存储测试集radio = 0.80 # 按4:1划分loadDateset('G:/PycharmProjects/Machine_Learning/KNN/irisdata.txt',radio,trainSet,testSet) #导入数据并划分print("trainSetNum: "+ str(len(trainSet)))print("testSetNum: "+ str(len(testSet)))predictions = []k = 3 # 选取前k个最近的实例for x in range(len(testSet)): # 循环预测测试集合的每个实例neighbors = getNeighbors(trainSet,testSet[x],k)result = getResponse(neighbors)predictions.append(result)print('>predicted=' + repr(result) + ', actual=' + repr(testSet[x][-1]))accuracy = getAccuracy(testSet,predictions)print('Accuracy: ' + repr(accuracy) + '%')if __name__ == '__main__':main()
运行结果
trainSetNum: 124testSetNum: 26>predicted='Iris-setosa', actual='Iris-setosa'>predicted='Iris-setosa', actual='Iris-setosa'>predicted='Iris-setosa', actual='Iris-setosa'>predicted='Iris-setosa', actual='Iris-setosa'>predicted='Iris-setosa', actual='Iris-setosa'>predicted='Iris-setosa', actual='Iris-setosa'>predicted='Iris-setosa', actual='Iris-setosa'>predicted='Iris-setosa', actual='Iris-setosa'>predicted='Iris-versicolor', actual='Iris-versicolor'>predicted='Iris-versicolor', actual='Iris-versicolor'>predicted='Iris-versicolor', actual='Iris-versicolor'>predicted='Iris-versicolor', actual='Iris-versicolor'>predicted='Iris-versicolor', actual='Iris-versicolor'>predicted='Iris-versicolor', actual='Iris-versicolor'>predicted='Iris-versicolor', actual='Iris-versicolor'>predicted='Iris-versicolor', actual='Iris-virginica'>predicted='Iris-virginica', actual='Iris-virginica'>predicted='Iris-virginica', actual='Iris-virginica'>predicted='Iris-virginica', actual='Iris-virginica'>predicted='Iris-virginica', actual='Iris-virginica'>predicted='Iris-virginica', actual='Iris-virginica'>predicted='Iris-virginica', actual='Iris-virginica'>predicted='Iris-virginica', actual='Iris-virginica'>predicted='Iris-versicolor', actual='Iris-virginica'>predicted='Iris-virginica', actual='Iris-virginica'>predicted='Iris-virginica', actual='Iris-virginica'Accuracy: 92.3076923076923%
算法优缺点
优点
- 精度高、对异常值不敏感、无数据输入假定。
- KNN算法不仅可以用于分类,还可以用于回归。通过找出一个样本的k个最近邻居,将这些邻居的属性的平均值赋给该样本,就可以得到该样本的属性。
缺点
- 样本分布不均衡时,如果一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。
- 计算量较大,因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最近邻点。
适用的数据范围
数值型和标称型。
**标称型:**一般在有限的数据中取,而且只存在‘是’和‘否’两种不同的结果(一般用于分类)
**数值型:**可以在无限的数据中取,而且数值比较具体化,例如4.02,6.23这种值(一般用于回归分析)
K-Means简介
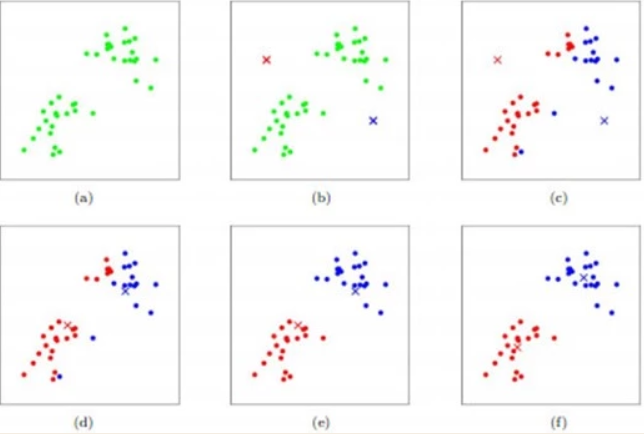
如图所示,数据样本用圆点表示,每个簇的中心点用叉叉表示。
(a) 刚开始时是原始数据,杂乱无章,没有label,看起来都一样,都是绿色的。
(b) 假设数据集可以分为两类,令K=2,随机在坐标上选两个点,作为两个类的中心点。
(c-f) 演示了聚类的两种迭代。先划分,把每个数据样本划分到最近的中心点那一簇;划分完后,更新每个簇的中心,即把该簇的所有数据点的坐标加起来去平均值。这样不断进行”划分—更新—划分—更新”,直到每个簇的中心不在移动为止。
KNN和K-Means的区别
| KNN | K-Means |
|---|---|
| KNN是分类算法 | K-Means是聚类算法 |
| 监督学习 | 非监督学习 |
| 喂给它的数据集是带label的数据,已经是完全正确的数据 | 喂给它的数据集是无label的数据,是杂乱无章的,经过聚类后才变得有点顺序,先无序,后有序 |
| 没有明显的前期训练过程,属于memory-based learning | 有明显的前期训练过程 |
| K的含义:来了一个样本x,要给它分类,即求出它的y,就从数据集中,在x附近找离它最近的K个数据点,这K个数据点,类别c占的个数最多,就把x的label设为c | K的含义:K是人工固定好的数字,假设数据集合可以分为K个簇,由于是依靠人工定好,需要一点先验知识 |
两者相似点:都包含这样的过程,给定一个点,在数据集中找离它最近的点。即二者都用到了NN(Nears Neighbor)算法。
参考资料
KNN与K-Means的区别




























还没有评论,来说两句吧...